01
08 Jul, 2026 AI Coding
Matt Pocock 的 AI Skills:把软件工程基本功重新封装给 Agent
AI 编程工具越来越强,但需求对齐、上下文管理、架构腐化、验证和记忆这些老问题没有消失。Matt Pocock 的 skills 更适合仍想掌握代码质量和架构判断的开发者。
Today
09:07:39
2026年7月31日星期五
zhangferry's blog, iOSer 这里聚合最近的技术文章、阶段复盘和长期积累的内容,让首页更像一份清晰的阅读入口。
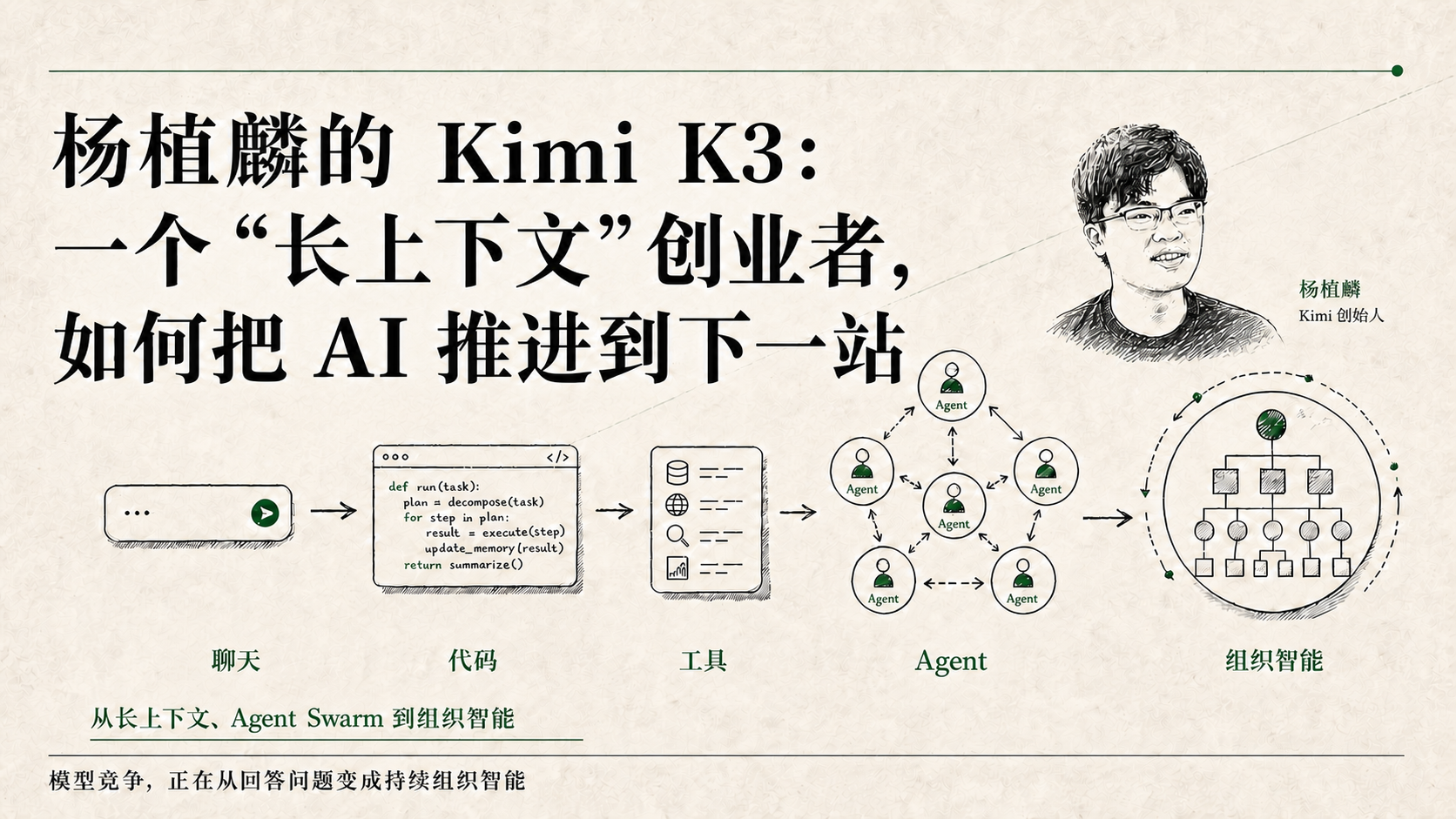
从长上下文、协作型 Agent 到让 AI 参与下一代 AI 的研发,杨植麟和月之暗面如何把一套技术路线推进到 Kimi K3。
Latest Posts
AI 编程工具越来越强,但需求对齐、上下文管理、架构腐化、验证和记忆这些老问题没有消失。Matt Pocock 的 skills 更适合仍想掌握代码质量和架构判断的开发者。
wwdc-notes 收录 2020 到 2025 共 1032 场 WWDC Session,既提供面向人的中文浏览网站,也提供给 Agent 使用的 WWDC Skill,让 Apple 平台问题能回到具体 Session...
接近 4 小时的姚顺宇访谈里,最值得记住的不是哪句出圈狠话,而是他对组织、技术演进、coding 与未来程序员的一整套判断。
AHE 提出让独立的进化 agent 根据 benchmark 轨迹,自动修改 coding agent 周围的 harness(工具、中间件、记忆等),而非只优化 prompt,10 轮闭环进化将 pass@1 从 69.7% 提升到...
multica 定位是为 AI-native 团队设计的人 + Agent 协作平台,主要解决 Agent 任务管理、团队知识孤岛和多人多 Agent 缺乏协作中枢等问题
Anthropic 是当前 AI 行业中产品迭代速度最快的公司之一,其背后有一套值得深究的产品方法论。这期访谈中 Cat Woo 系统性地分享了 Claude Code 团队的实战经验,信息密度极高,值得反复阅读。
一个开源的本地 Web Dashboard,用于统计与可视化 Claude Code 和 OpenAI Codex 的 Token、费用与缓存命中率。
团队介绍 抖音基础技术是负责抖音客户端基础能力研发和新技术探索的团队。我们在工程/业务架构,研发工具,编译系统等方向深耕,支撑业务快速迭代的同时,保证超大规模团队的研发效能和工程质量。在性能/稳定性方面不断探索,努力为全球数亿用户提供最极致...
个人介绍 1、简单介绍下自己吧 大家好,我叫张安宇,我以前是一名普通的 iOS...