
继续学习《程序员的自我修养 - 链接、装载与库》的第二个大的部分,这一部分包含本书的二、三、四、五章节,作者深入浅出的给我们讲解了静态链接的相关的知识,干货满满,受益良多。
作为一名 iOS 开发人员,我们几乎每天都会用 Xcode 构建我们的程序,但是编译和链接的过程,我们却很少关注, Xcode 作为一种 IDE(集成开发环境)功能十分强大,它能够和 Mac OS 系统中其它的工具协作,例如编译器 gcc,它们提供的默认配置、编译和链接参数对于大部分的应用开发已经足够使用了,也正是由于这些集成工具的存在,我们也忽略了软件的运行机制与机理。
如果我们能深入的了解这些软件的运行机制,也许我们就能在解决问题的时候,多上一种思路,甚至是打破一些瓶颈。所以马上回到今天打算研究的部分,静态链接。大体来说,静态链接是由链接器在链接时将库的内容加入到可执行程序中的做法。具体分为四个部分来讲解:编译和链接,目标文件里有什么,静态链接,Windows PE/COFF,具体的知识点分布如下:
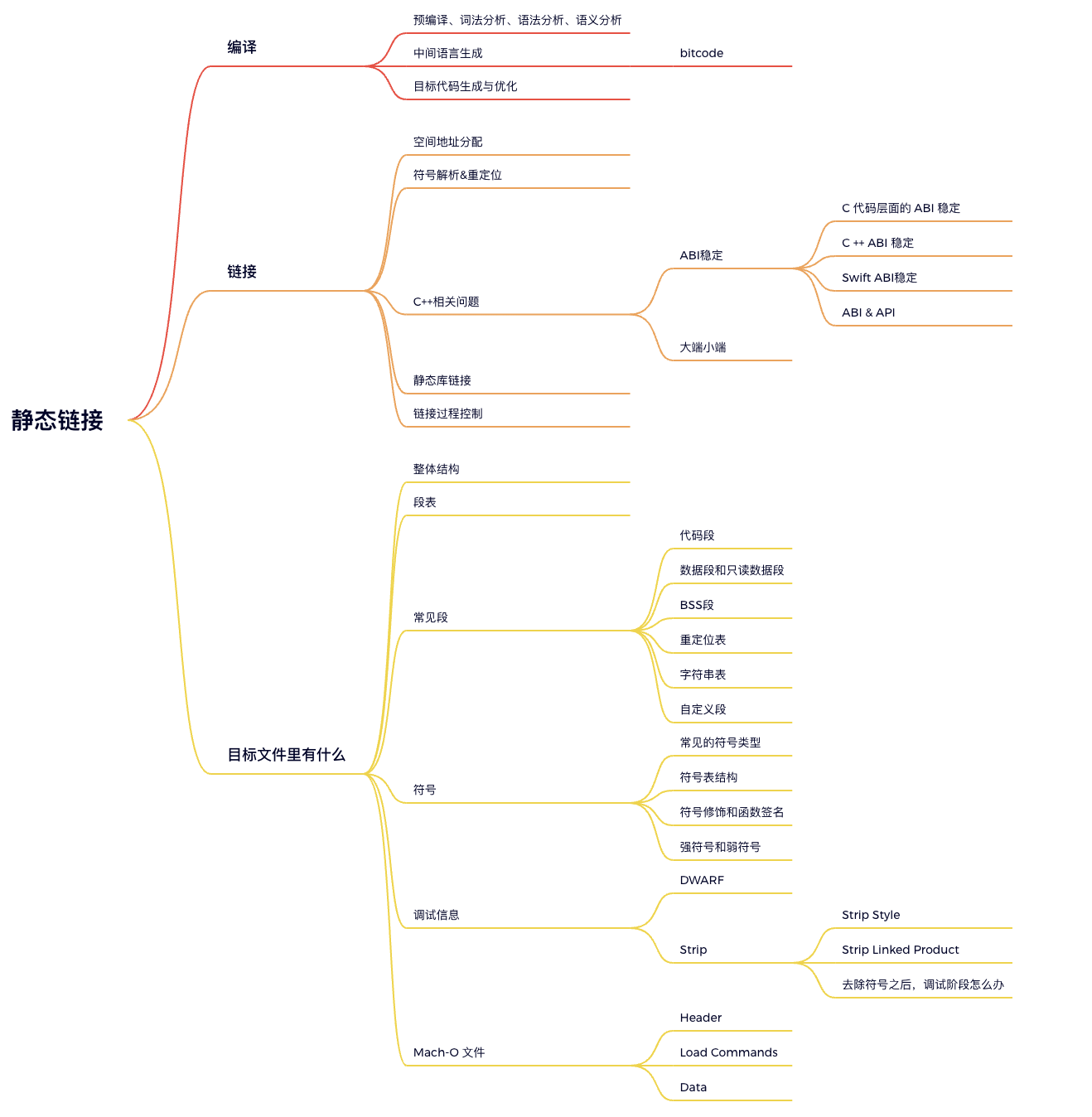
还记得连载上一文提到的 Hello World 程序吗?
#include <stdio.h>
int main() {
printf("Hello World\n");
return 0;
}
在 Linux 下执行,需要使用使用 gcc 来编译,首先通过 gcc hello.c,这会产生默认命名为 a.out 的可执行文件,然后通过 ./a.out 执行这个文件,输出 Hello World,事实上,这里要分为4个步骤:预处理,编译,汇编,链接。
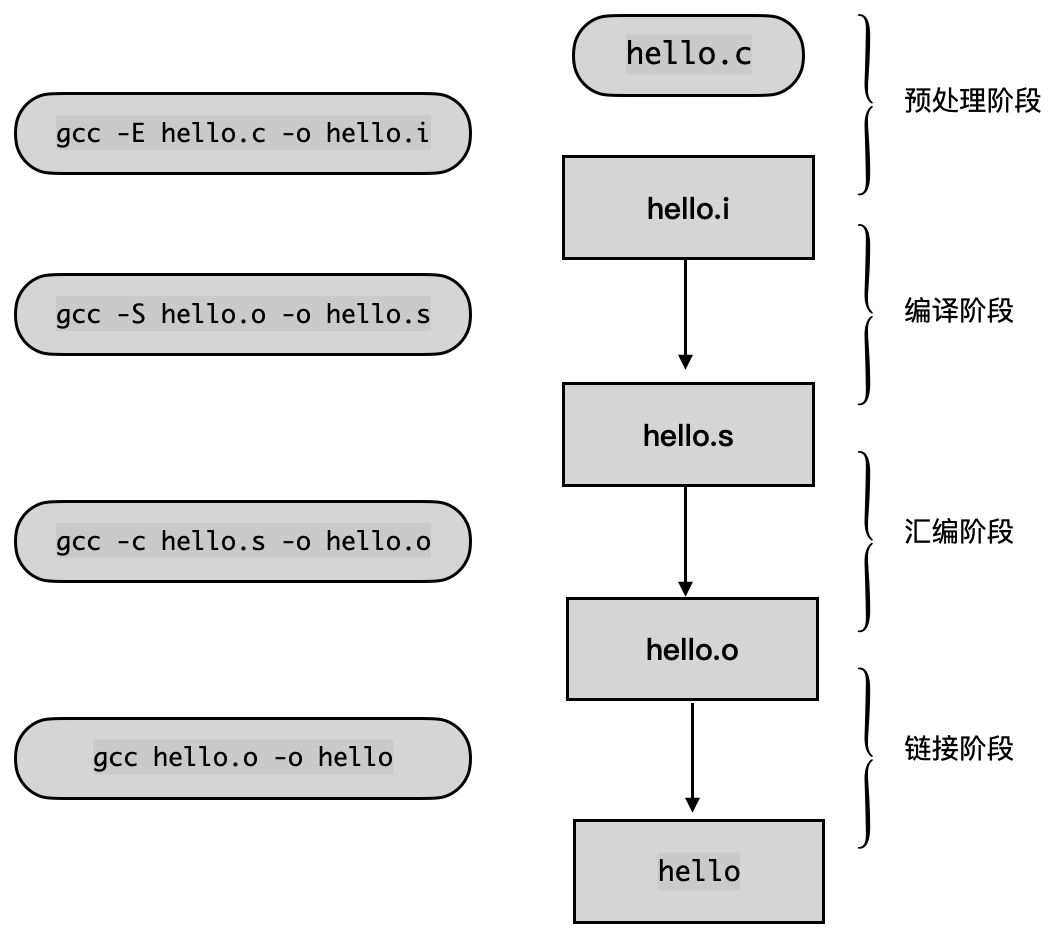
编译
在编译之前会有个预编译的过程,使用到的指令为:gcc -E hello.c hello.i
预编译主要做了如下的操作:
- 处理
#开头的指令,例如#define进行宏替换,#if、#ifdef,#elif,#else,#endif。 - 删除注释。
- 添加行号和文件名标识,用于编译时产生调试用的信息等。
- 保留
#pragma编译器指令。 - 包含的头文件展开。
预编译过后就是编译阶段,编译器就是将高级语言翻译成机器语言的一个工具,之所以使用高级语言,是因为它能使得程序员更加关注程序本身的逻辑,而不是计算机本身的限制(字长、内存大小、通信方式、存储方式等)。高级语言虽然提高了开发的效率,但是机器却无法识别,需要通过编译器,将其翻译成机器认识的语言,翻译的具体过程如下所示。
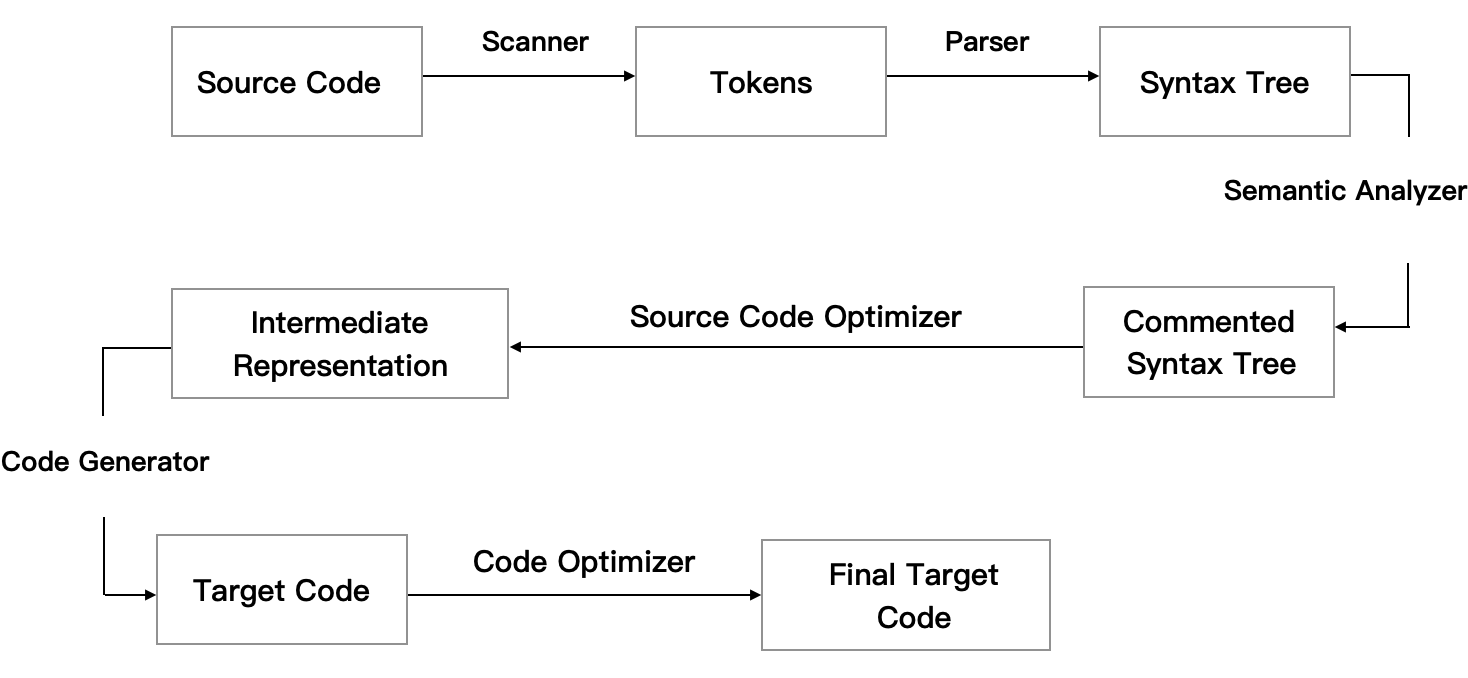
具体的过程分为 6 步: 扫描、语法分析、语义分析、源代码优化、代码生成和目标代码优化,现代的 gcc 会将预编译和编译合并成一个步骤 cc1。
编译使用的指令:gcc -S hello.i hello.s
gcc 这个命令只是一些后台程序的包装,它会根据不同的参数要求去调用预译编程序 cc1、汇编器 as、链接器 ld。
顺道我们回顾一下 Clang, Clang 是一个由 Apple 主动编写,是 LLVM 项目中的一个子项目。基于 LLVM 的轻量级编译器,之初是为了替代 GCC,提供更快的编译速度。他是负责编译 C、C++、OC 语言的编译器。
测试代码 CompilerExpression.c 如下:
void test() {
int index = 1;
int array[3];
array[index] = (index + 4) * (2 + 6);
}
词法分析
CompilerExpression.c 源代码输入到扫描器,运用一种类似于有限状态机的算法将源代码的字符序列分割成一系列的记号,记号分为关键字、标识符、字面量(数字、字符串)、特殊符号(加号、等号)等。
同时会将标识符号放入符号表,将数字、字符串常量放到文字表,以备后续使用。
针对上面 CompilerExpression.c 里面的代码,我们可以使用 clang 进行词法分析:clang -fmodules -fsyntax-only -Xclang -dump-tokens CompilerExpression.c ,打印如下:
void 'void' [StartOfLine] Loc=<CompilerExpression.c:1:1>
identifier 'test' [LeadingSpace] Loc=<CompilerExpression.c:1:6>
l_paren '(' Loc=<CompilerExpression.c:1:10>
r_paren ')' Loc=<CompilerExpression.c:1:11>
l_brace '{' [LeadingSpace] Loc=<CompilerExpression.c:1:13>
int 'int' [StartOfLine] [LeadingSpace] Loc=<CompilerExpression.c:2:5>
identifier 'index' [LeadingSpace] Loc=<CompilerExpression.c:2:9>
equal '=' [LeadingSpace] Loc=<CompilerExpression.c:2:15>
numeric_constant '1' [LeadingSpace] Loc=<CompilerExpression.c:2:17>
semi ';' Loc=<CompilerExpression.c:2:18>
int 'int' [StartOfLine] [LeadingSpace] Loc=<CompilerExpression.c:3:5>
identifier 'array' [LeadingSpace] Loc=<CompilerExpression.c:3:9>
l_square '[' Loc=<CompilerExpression.c:3:14>
numeric_constant '3' Loc=<CompilerExpression.c:3:15>
r_square ']' Loc=<CompilerExpression.c:3:16>
semi ';' Loc=<CompilerExpression.c:3:17>
identifier 'array' [StartOfLine] [LeadingSpace] Loc=<CompilerExpression.c:4:5>
l_square '[' Loc=<CompilerExpression.c:4:10>
identifier 'index' Loc=<CompilerExpression.c:4:11>
r_square ']' Loc=<CompilerExpression.c:4:16>
equal '=' [LeadingSpace] Loc=<CompilerExpression.c:4:18>
l_paren '(' [LeadingSpace] Loc=<CompilerExpression.c:4:20>
identifier 'index' Loc=<CompilerExpression.c:4:21>
...
上文有说过,词法分析的结果会将源代码分解成一个个小的 Token,标明了所在的行数和列数。
语法分析
对词法分析的结果进行语法分析,生成语法树(以表达式为节点的树),复杂的语句就是很多表达式的组合,编译器的开发者仅仅需要改变语法规则,即可适配多种编程语言。
上面的代码中的语句,就是由赋值表达式、加法表达式、乘法表达式、数组表达式、括号表达式组合成的复杂语句,经过语法分析之后,就会形成下图所示的语法树,在这个阶段如果出现表达式不合法(括号不匹配、表达式缺少操作符)编译器就会报告语法分析阶段的错误:
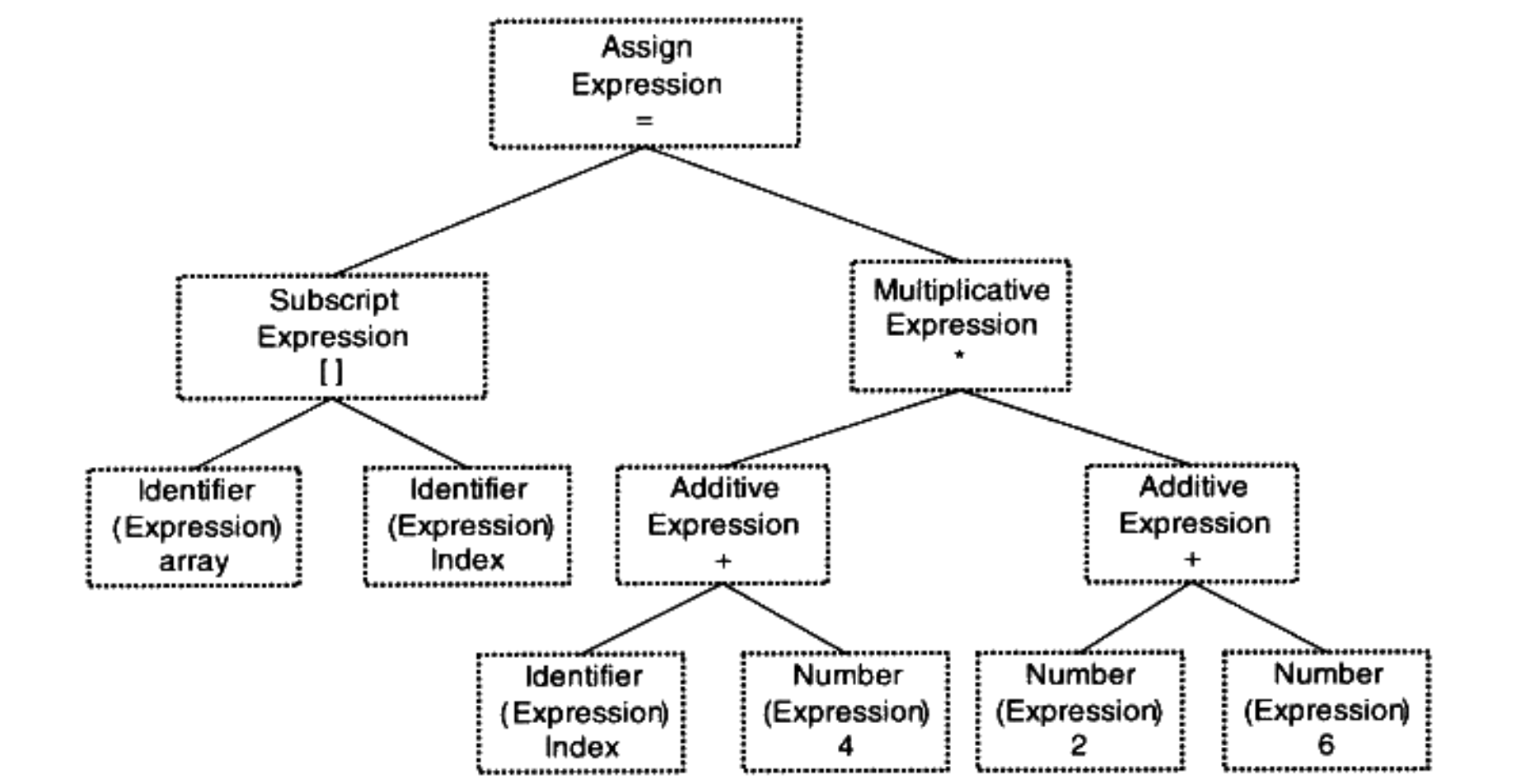
语法分析会形成抽象语法树 AST,我们继续使用 clang 命令进行语法分析 clang -fmodules -fsyntax-only -Xclang -ast-dump CompilerExpression.c,得到的结果如下:
TranslationUnitDecl 0x7fccdc822808 <<invalid sloc>> <invalid sloc>
|-TypedefDecl 0x7fccdc823048 <<invalid sloc>> <invalid sloc> implicit __int128_t '__int128'
| `-BuiltinType 0x7fccdc822dd0 '__int128'
`-FunctionDecl 0x7fccdd04d048 <CompilerExpression.c:1:1, line:5:1> line:1:6 test 'void ()'
`-CompoundStmt 0x7fccdd04d568 <col:13, line:5:1>
`-BinaryOperator 0x7fccdd04d548 <line:4:5, col:40> 'int' '='
|-ArraySubscriptExpr 0x7fccdd04d3f0 <col:5, col:16> 'int' lvalue
| |-ImplicitCastExpr 0x7fccdd04d3c0 <col:5> 'int *' <ArrayToPointerDecay>
| | `-DeclRefExpr 0x7fccdd04d320 <col:5> 'int[3]' lvalue Var 0x7fccdd04d2a0 'array' 'int[3]'
| `-ImplicitCastExpr 0x7fccdd04d3d8 <col:11> 'int' <LValueToRValue>
| `-DeclRefExpr 0x7fccdd04d358 <col:11> 'int' lvalue Var 0x7fccdd04d160 'index' 'int'
`-BinaryOperator 0x7fccdd04d528 <col:20, col:40> 'int' '*'
|-ParenExpr 0x7fccdd04d488 <col:20, col:30> 'int'
| `-BinaryOperator 0x7fccdd04d468 <col:21, col:29> 'int' '+'
| |-ImplicitCastExpr 0x7fccdd04d450 <col:21> 'int' <LValueToRValue>
| | `-DeclRefExpr 0x7fccdd04d410 <col:21> 'int' lvalue Var 0x7fccdd04d160 'index' 'int'
| `-IntegerLiteral 0x7fccdd04d430 <col:29> 'int' 4
`-ParenExpr 0x7fccdd04d508 <col:34, col:40> 'int'
`-BinaryOperator 0x7fccdd04d4e8 <col:35, col:39> 'int' '+'
|-IntegerLiteral 0x7fccdd04d4a8 <col:35> 'int' 2
`-IntegerLiteral 0x7fccdd04d4c8 <col:39> 'int' 6
上面的示例代码比较简单,我们来分析下这个 AST 中的几个节点:
- 对于
Clang来说,顶层结构是TranslationUnitDecl(translation unit declaration :翻译单元声明),对AST树的遍历,实际上是遍历整个TranslationUnitDec。 TypedefDecl类型描述,对应typedef。FunctionDecl代表 C/C++方法定义。CompoundStmt代表了像{ stmt stmt }这样的statement的集合。实际上就是用{}and{{}}包裹的代码块。- 之前说过语法分析的结果,会生成以表达式为节点的树,clang
AST中的所有表达式都由Expr的子类表示。 BinaryOperator类是Expr类的子类,其包括两个子节点。
上文也说过在这个阶段如果出现表达式不合法(括号不匹配、表达式缺少操作符)编译器就会报告语法分析阶段的错误,所以我将 CompilerExpression.c 中的 array[index] = (index + 4) * (2 + 6) 中的 ; 去掉试一下:
CompilerExpression.c:4:41: error: expected ';' after expression
array[index] = (index + 4) * (2 + 6)
^
;
...
1 error generated.
果然报告了一个错误,提示 array[index] = (index + 4) * (2 + 6) 后面应该加上 ;
语义分析
经过词法分析和语法分析之后,语句是否真的有意义呢,这时候就需要进行语义分析,查看语句在语法上是否合法,需要注意的是编译器只能查看静态语义,动态语义需要运行时才能进行确定。
如果过程中出现了类型不匹配,编译器就会报错,经过语义分析之后的语法树如下:
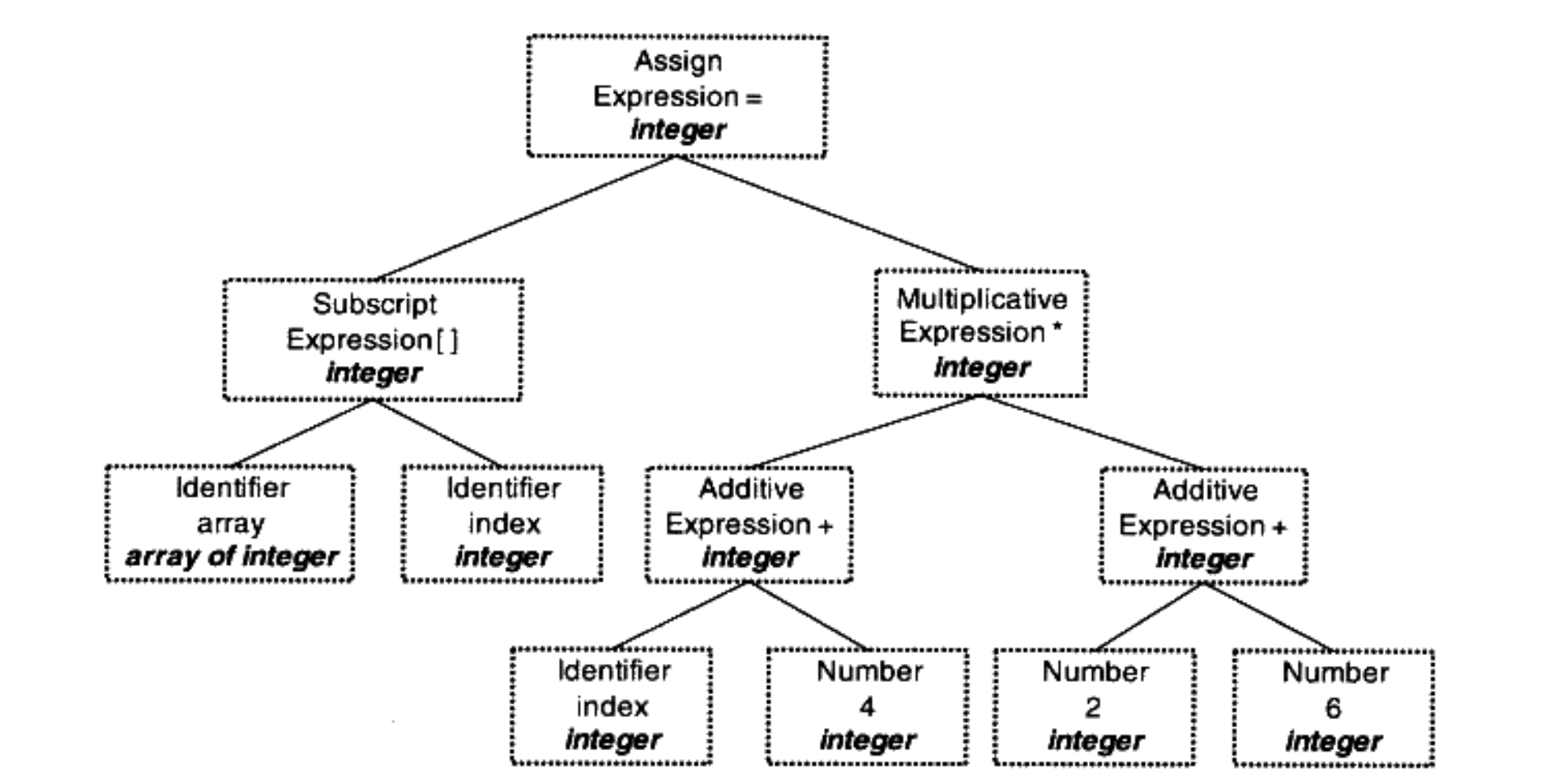
可以看出,编译期可以确定的表达式类型,都已经被确定好了(如果有隐式转换,语义分析会在语法树中插入转换节点),除此之外,符号表里面的类型也做了更新。
中间语言生成
编译器存在多个层次的优化行为,源代码级别的称之为源代码优化器,上述的经过语义分析之后的整个语法树,(2+6)会被优化成了8,其实并不是直接在语法树上进行优化,而是将整个语法树转化成中间代码,来顺序的标识语法树,常见三地址码和 P-Code 法两种方式。
中间代码层作为中间层的存在,使得编译器可以被分为前端和后端。编译器前端负责产生机器无关的中间代码,编译器后端将中间代码转换成目标机器代码。
针对上面代码采用三地址码法进行优化 :
最基本的三地址码长这样: x = y op z
表示变量 x 和变量 y 经过 op 操作后赋值给 x
例如函数内部的代码 array[index] = (index + 4) * (2 + 6);,经过中间层的源代码优化器 (Optimizer)优化后的代码最终为:
t2 = index + 4
t2 = t2 * 8
array[index] = t2
使用 clang 命令将语法树自顶向下遍历逐步翻译成 LLVM IR:clang -S -fobjc-arc -emit-llvm test.c -o test.ll
得到 .ll 文件,IR 代码如下:
; ModuleID = 'CompilerExpression.c'
source_filename = "CompilerExpression.c"
target datalayout = "e-m:o-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-apple-macosx12.0.0"
; Function Attrs: noinline nounwind optnone ssp uwtable
define void @test() #0 {
%1 = alloca i32, align 4
%2 = alloca [3 x i32], align 4
store i32 1, i32* %1, align 4
%3 = load i32, i32* %1, align 4
%4 = add nsw i32 %3, 4
%5 = mul nsw i32 %4, 8
%6 = load i32, i32* %1, align 4
%7 = sext i32 %6 to i64
%8 = getelementptr inbounds [3 x i32], [3 x i32]* %2, i64 0, i64 %7
store i32 %5, i32* %8, align 4
ret void
}
...
BitCode
这里简单提一下我们经常听说的 BitCode,BitCode 是 iOS 9 引入的新特性,官方文档解释 BitCode 是一种中间代码,包含 BitCode 的应用程序会在 App Store 上编译和链接, BitCode 允许苹果在后期对我们的应用程序的二进制文件进行优化。其实就是 LLVM IR 的一种编码形式,如下图我们可以看到 BitCode 在编译环节所处的位置:
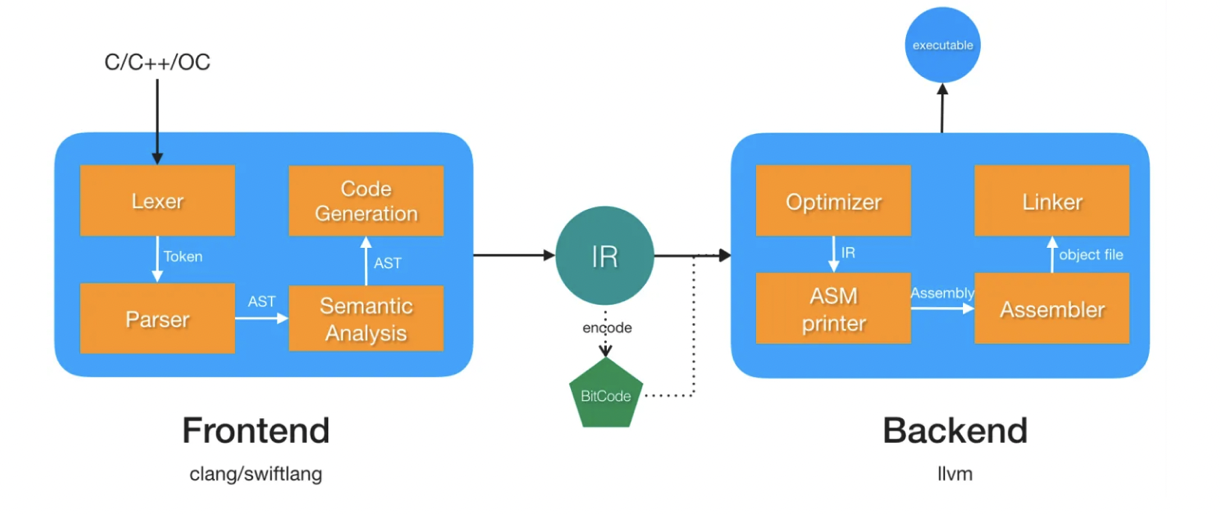
但是在 Xcode 14 中 BitCode 被废除,iOS、tvOS 以及 watchOS 应用程序默认将不再支持 BitCode,在未来的 Xcode 版本中,BitCode 将被移除,主要原因是 Bitcode 并不是一个稳定的格式,因为在 LLVM 的设计里,它只是一个临时产生的文件,并不期望被长期存储,这导致它的兼容性很差,几乎 LLVM 每次版本更新时都会修改它,其次是对生态的要求很高,如果应用的任何一个依赖没有支持 Bitcode,那最终就无法使用。
目标代码生成与优化
编译器的后端主要包含代码生成器和目标代码优化器。代码生成器依赖于目标机器的字长、寄存器、整数数据类型和浮点数数据类型等,将中间代码转换目标机器代码。
array[index] = (index + 4) * (2 + 6); 经过源代码优化器又经过代码生成器变成如下代码:
movl index, %ecx
addl $4, %ecx
mull $8, %ecx
movl index, %eax
movl %ecx, array(, eax, 4)
上面代码经过目标代码优化器,会选择合适的寻址方式,使用位移来代替乘法运算,删除多余指令等,经过目标代码优化器之后代码如下(其中乘法改用相对复杂的基地址比例变址寻址的指令完成):
movl index, %edx
leal 32(, %edx, 8), %eax
movl %eax, array(, %edx, 4)
还有,我们都知道 Xcode 是使用 Clang 来编译 Objective-C 语言的,而 Xcode 供给我们 7 个等级的编译选项,在 Xcode -> Build Setting -> Apple LLVM 9.0 - Code Generation -> Optimization Level 中进行设置。
- None [-O0]:不优化
- Fast [-O1]:大函数所需的编译时间和内存消耗都会稍微增加
- Faster [-O2]:编译器执行所有不涉及时间空间交换的所有的支持的优化选项
- Fastest [-O3]:在开启Fast [-O1]项支持的所有优化项的同时,开启函数内联和寄存器重命名选项
- Fastest, Smallest [-Os]:在不显着增加代码大小的情况下尽量提供高性能
- Fastest, Aggressive Optimizations [-Ofast]:与Fastest, Smallest [-Os]相比该级别还执行其他更激进的优化
- Smallest, Aggressive Size Optimizations [-Oz]:不使用LTO的情况下减小代码大小
设置不同优化选项,中间代码的大小会相应变化。
链接
代码经过标代码优化器,已经变成了最优的汇编代码结构,但是如果此时的代码里面使用到了别的目标文件定义的符号怎么办?这就引出了链接,之所以称之为链接,就是因为链接时需要将很多的文件链接链接起立,才能得到最终的可执行文件。
最开始的时候,程序员采用纸带打孔的方式输入程序的,然而指令是通过绝对地址进行寻址跳转的,指令修改过后,绝对的地址就需要进行调整,重定位的计算耗时又容易出错,于是就出现了汇编语言,采用符号的方式进行指令的跳转,每次汇编程序的时候修正符号指令到正确的地址。汇编使得程序的扩展更加方便,但是代码量开始膨胀,于是需要进行模块的划分,产生大量的模块,这些模块互相依赖又相对独立,链接之后模块间的变量访问和函数访问才有了真实的地址。模块链接的过程,本书的作者很形象生动的比作了拼图的过程,链接完成之后,才能产生一个可以真正执行的程序。
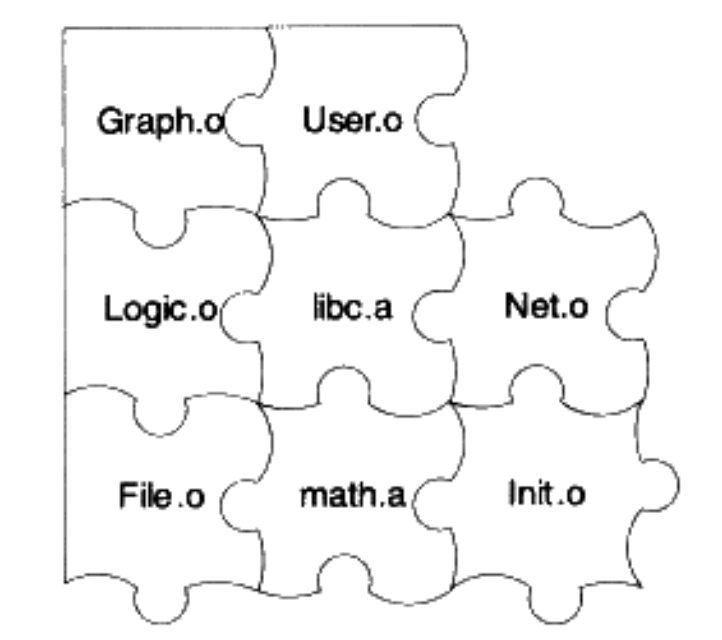
链接的原理无非是对一些符号的地址加以修正的过程,将模块间的互信引用的部分都处理好。具体包括地址和空间分配、符号决议、重定位等步骤。多数情况下,目标文件和库需要一起进行链接,常用的一些基本函数大多属于运行时库(Runtime Library),链接器会根据引用的外部模块的符号,自动的去查找符号的地址,进行地址修正。
空间地址分配
到了比较重要的静态链接,上面说的 “拼图” 的过程,其实就是静态链接的过程,即将多个目标文件链接起来,形成一个可执行文件。
有这样两个文件 a.c 和 b.c,gcc -c a.c b.c 经过编译后形成 a.o 和 b.o:
// a.c
extern int shared;
void swap(int* a, int* b);
int main() {
int a = 100;
swap(&a, &shared);
}
// b.c
int shared = 1;
void swap(int* a, int* b) {
*a ^= *b ^= *a ^= *b;
}
在 a.c 定义了两个外部符号 shared 和 swap ,b.c 中定义了一个 main 为全局符号,我们可以查看下通过clang进行编译,通过 MachOView 查看 a.o:
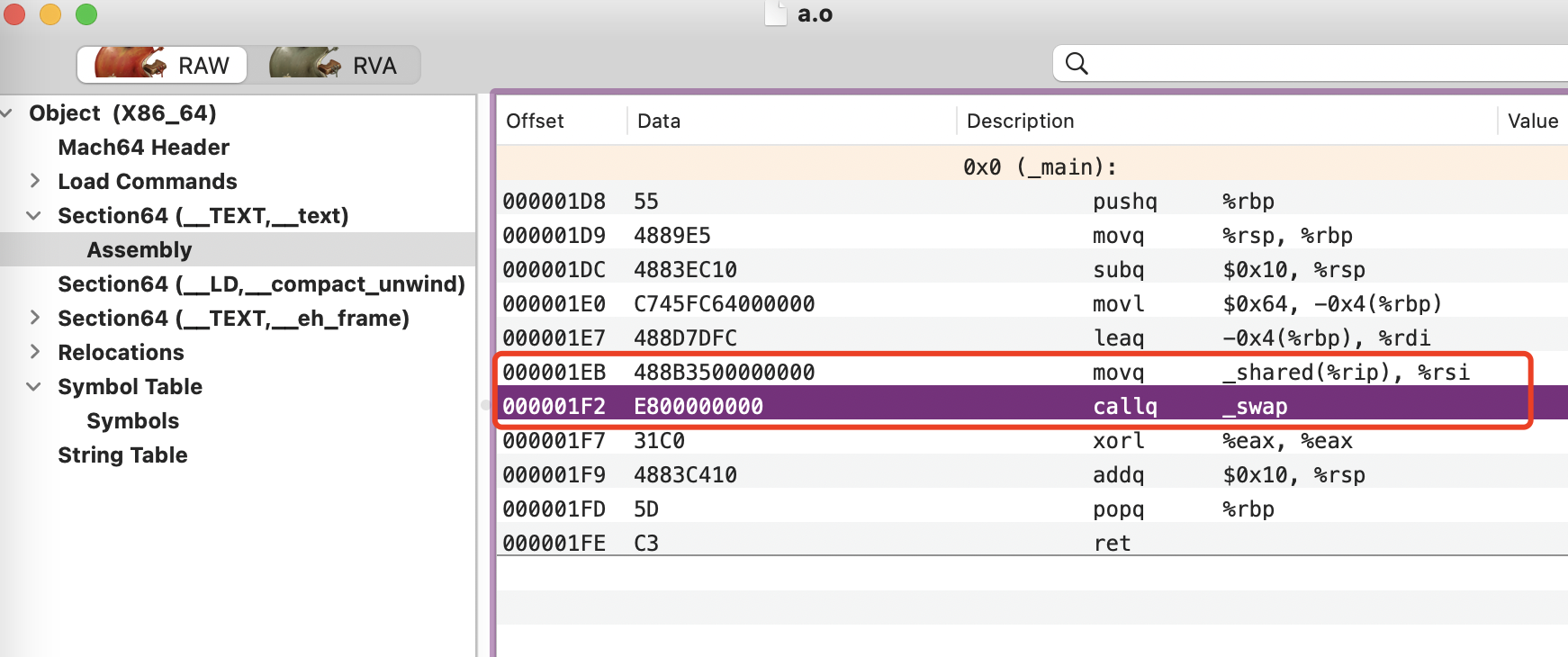
可见 mov 这条指令中,shared 的部分的地址为 0x00000000,swap 的地址也为 0x00000000 (其中0xE8 为操作码)。这部分只是用来代替,真正的地址计算留给链接器。
接下来就是将两个目标文件进行链接,两个目标文件怎么合并呢?
方式一:直接将目标文件拼接起来
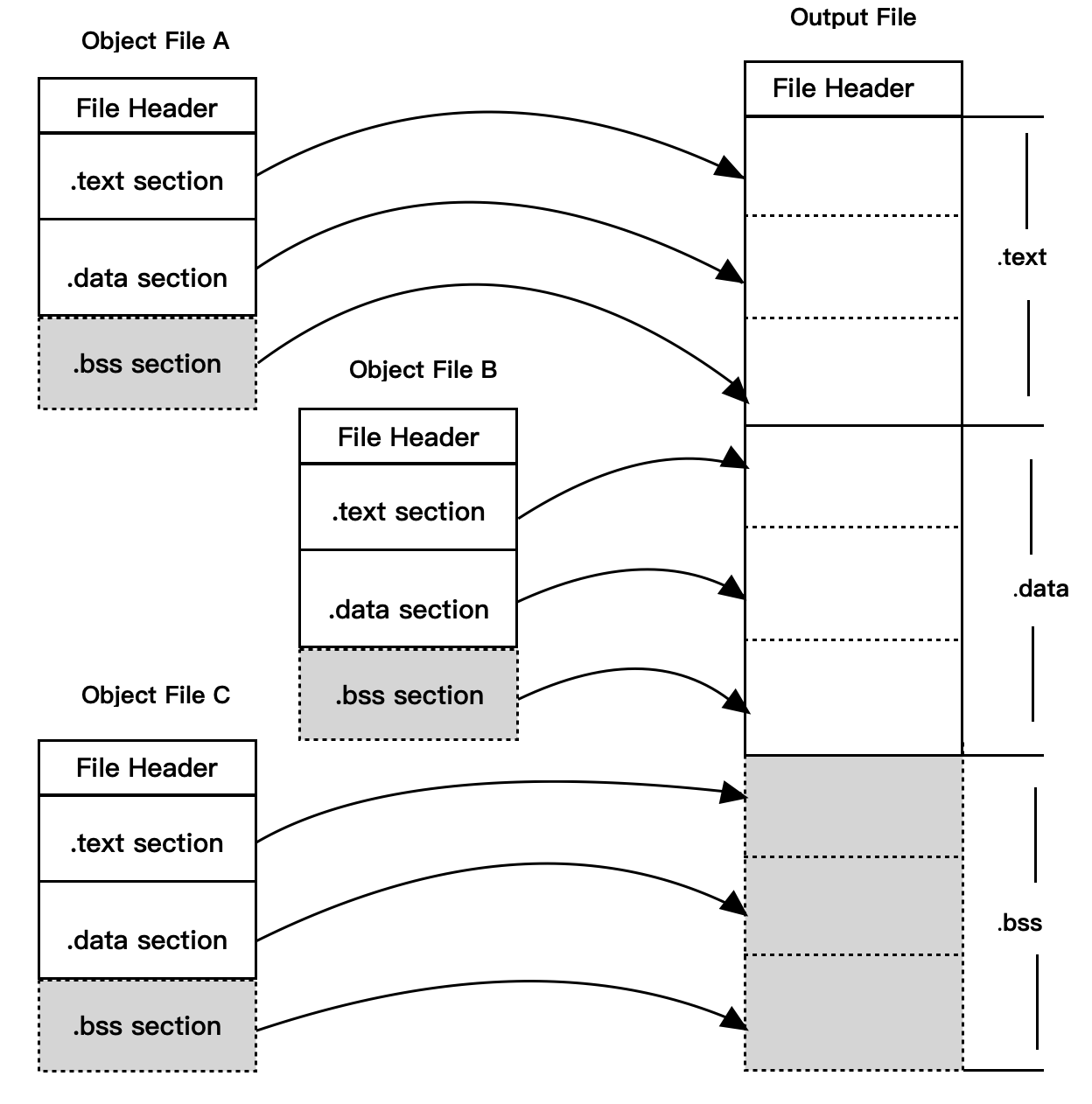
这种拼接方式虽然简单,但是缺点很明显,段数量太多了不说,由于 x86的硬件来说,段的装载和空间对齐的单位是页,4096个字节,这就会导致即便是仅有1个字节的段,在内存中也会被分配4096个字节。
方式二:相似段合并
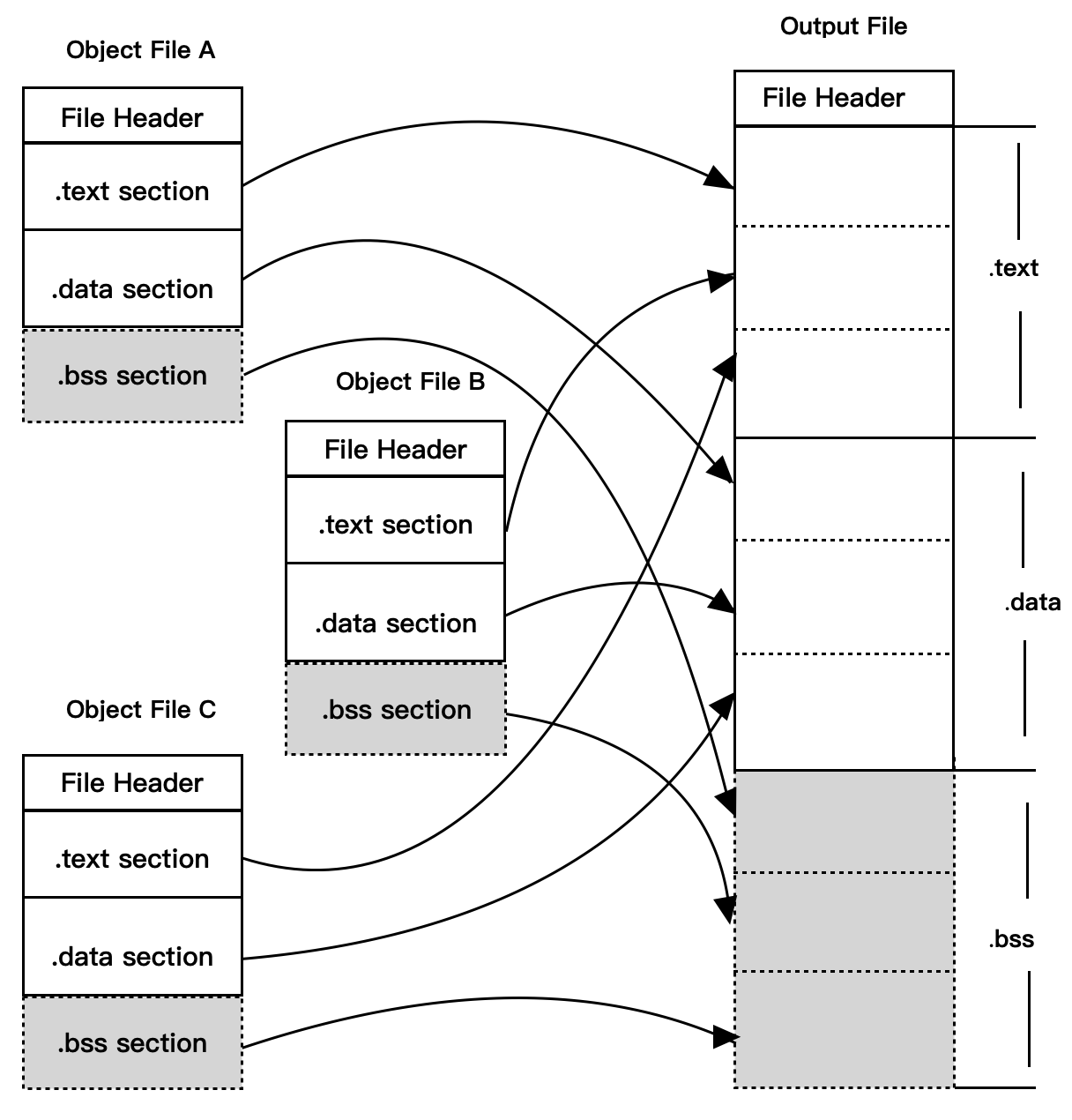
现在的链接器大多都是采用两步链接的方法:
- 空间与地址分配
- 扫描所有的目标文件
- 获取各个段的长度,属性和位置
- 收集符号表中的所有符号定义和符号引用,放入全局符号表
- 获得所有目标文件的长度,并且将其合并
- 建立合并后的文件的映射关系
- 符号解析和重定位
- 获取上一步收集的段数据和重定位信息
- 进行符号解析
- 重定位
- 调整代码中的地址
使用 ld 将 a.o 和 b.o 链接起来: ld a.o b.o -e main -o ab ,链接后使用的地址是进程中的虚拟地址。
小Tip:如果在 MacOS 系统中可直接使用 clang 命名链接目标文件 clang a.o b.o -o ab,如果直接使用 ld 进行链接可能会导致异常如下:
ld: dynamic executables or dylibs must link with libSystem.dylib for architecture x86_64
即便添加了指定 libSystem:ld a.o b.o -e _main -o ab -lSystem ,也会报如下错误:
ld: library not found for -lSystem
发现是因为指定库的地址,最后解决方案如下:
ld a.o b.o -e _main -o ab -macosx_version_min 12.6 -L /Library/Developer/CommandLineTools/SDKs/MacOSX.sdk/usr/lib -lSystem
我分析报错主要原因是因为,MacOS 系统在链接的时候,会默认使用 libSystem.dylib,在 Mach-O 中也能看到这个库的存在
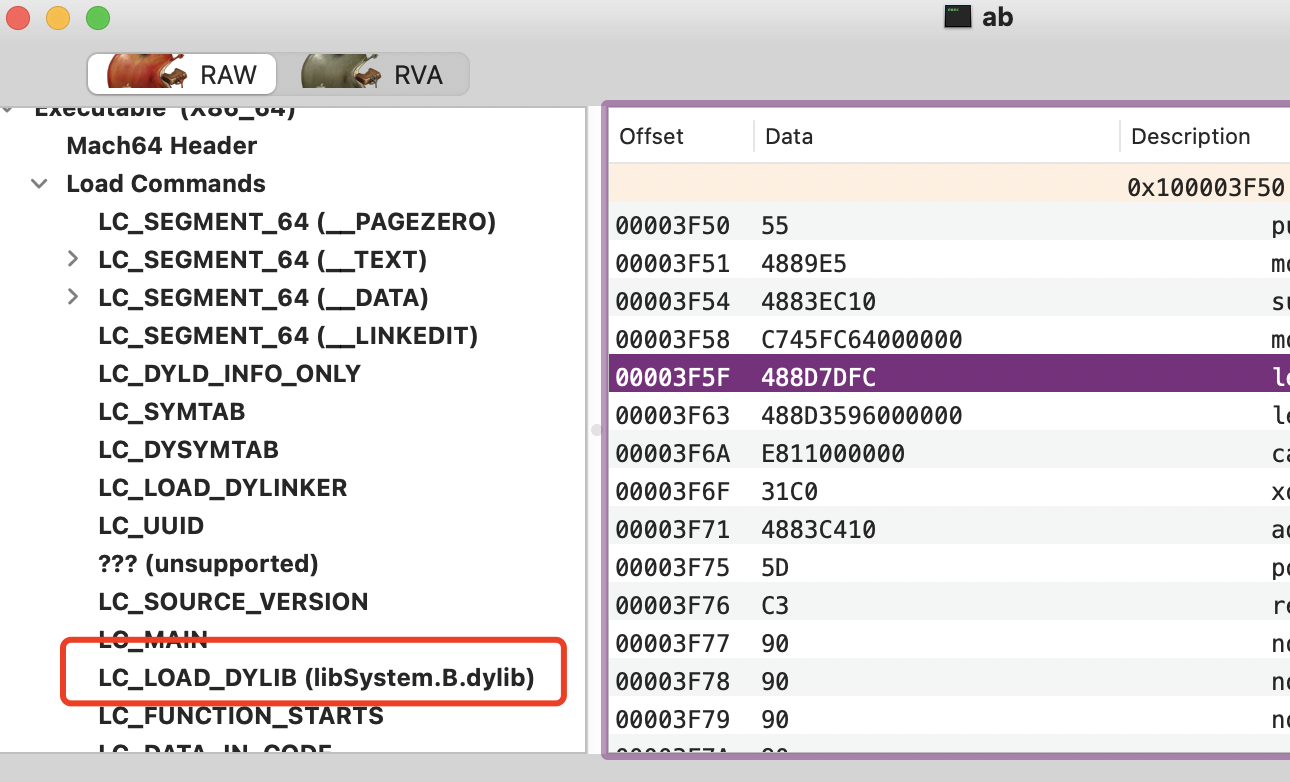
符号解析&重定位
何使用外部符号呢?比如 a.c 文件中就使用到了 shared 和 swap 两个外部符号,在 a.c 编译成目标文件的时候, shared 和 swap 两个的地址还不知道, 编译器会使用地址 0 当做 shared 的地址,函数的调用是一条叫 进址相对位移调用指令,这个我们放到最后来讲 swap 在目标文件中的地址也是一个临时的假地址 0xFFFFFFFC,在经过上一步的地址和空间分配之后,就已经可以确定所有符号的虚拟地址了。
我们看一下 a.o 和 经过链接之后的 ab,首先 objdump -d a.o 如下:
a.o: file format mach-o 64-bit x86-64
Disassembly of section __TEXT,__text:
0000000000000000 <_main>:
0: 55 pushq %rbp
1: 48 89 e5 movq %rsp, %rbp
4: 48 83 ec 10 subq $16, %rsp
8: c7 45 fc 64 00 00 00 movl $100, -4(%rbp)
f: 48 8d 7d fc leaq -4(%rbp), %rdi
13: 48 8b 35 00 00 00 00 movq (%rip), %rsi ## 0x1a <_main+0x1a>
1a: e8 00 00 00 00 callq 0x1f <_main+0x1f>
1f: 31 c0 xorl %eax, %eax
21: 48 83 c4 10 addq $16, %rsp
25: 5d popq %rbp
26: c3 retq
13行 和 1a行地址是临时给到的,需要进行重定位,再使用 objdump 看下 ab ,objdump -d ab :
ab: file format mach-o 64-bit x86-64
Disassembly of section __TEXT,__text:
0000000100003f50 <_main>:
100003f50: 55 pushq %rbp
100003f51: 48 89 e5 movq %rsp, %rbp
100003f54: 48 83 ec 10 subq $16, %rsp
100003f58: c7 45 fc 64 00 00 00 movl $100, -4(%rbp)
100003f5f: 48 8d 7d fc leaq -4(%rbp), %rdi
100003f63: 48 8d 35 96 00 00 00 leaq 150(%rip), %rsi ## 0x100004000 <_shared>
100003f6a: e8 11 00 00 00 callq 0x100003f80 <_swap>
100003f6f: 31 c0 xorl %eax, %eax
100003f71: 48 83 c4 10 addq $16, %rsp
100003f75: 5d popq %rbp
100003f76: c3 retq
...
可见经过链接 swap 和 shared 符号的地址已经确定。
对比上面的 a.o 的 MachOView 结果,我们查看一下 ab:
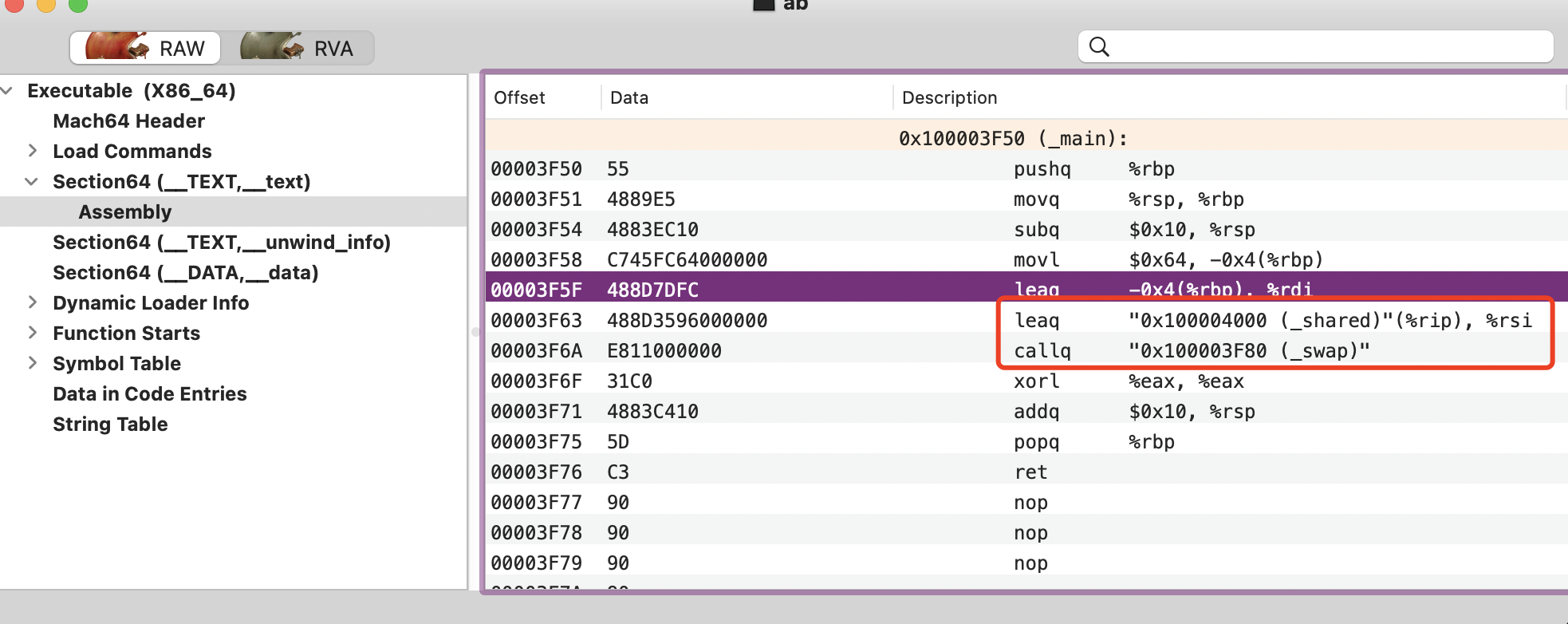
shared的地址修正属于绝对地址修正:
- 例如 b.o 文件中的
shared函数的段偏移是X - 合并后的段的 b.o 的代码段的虚拟地址假设为
0x08048094 - 那么合并后的
shared函数的地址为0x08048094 + X
swap是一条近址相对位移调用指令,它的地址是调用指令的下一条指令的偏移量,地址修正方式为:
- 首先找到下一条指令的偏移量
0x00000011 - 找到下一条指令的地址,由上图可以看到
callq指令的下一条指令地址为0x00003F6F - 所以
swap的地址可以计算得出0x00003F6F + 0x00000011 = 0x00003F80
至于链接器怎么就知道 shared 和 swap 是需要进行调整的指令呢?这里就涉及到了一个叫做重定位表的段,也叫做重定位段,其实上面也有说过,.rel.text 是针对代码段的重定位表,.rel.data 是针对数据段的重定位表, objdump -r a.o 结果如下:
a.o: file format mach-o 64-bit x86-64
RELOCATION RECORDS FOR [__text]:
OFFSET TYPE VALUE
000000000000001b X86_64_RELOC_BRANCH _swap
0000000000000016 X86_64_RELOC_GOT_LOAD _shared@GOTPCREL
RELOCATION RECORDS FOR [__compact_unwind]:
OFFSET TYPE VALUE
0000000000000000 X86_64_RELOC_UNSIGNED __text
a.o 中就存在了两个重定位入口,上图代表是代码段的重定位表,两个 offset 标识代码段中需要调整的指令的偏移地址。
C++相关问题
C++ 由于模板、外部内联函数、虚函数表等导致会产生很多重复的代码,目前的 GNU GCC 将每个模板代码放入一个段里,每个段只有一个模板的实例,当别的编译单元以相同的类型实例化模板函数的时候,也会生成和之前相同名称的段,最终在链接的时候合并到最后的代码段。C++ 还提供了一个叫做函数级别链接的编译选项,这个选项可以使所有函数都会被编译到单独的段里面,链接合并时,没有用到的函数就会被抛弃,减少了文件的长度,但是增加段的数量以及编译的时间。
C++ 的 main 之前需要初始化进程的执行环境等, main 之后需要做一些清理的工作,于是 ELF 文件还定义两个特殊的段 .init 和 .fini,一个放在main前由系统执行,一个放在main函数返回后执行。
目标文件可能是被两个不同的编译器产出的,那么两个目标文件能够进行链接的条件是:
- 采用相同的目标文件格式
- 拥有同样的符号修饰标准
- 变量的内存分布方式相同
- 函数调用方式相同
- …
其中 2,3,4 等是与可执行文件的二进制兼容性相关**(ABI)**
ABI稳定
人们总是希望二进制和数据不加修改能够得到重用,但是实现二进制级别的重用还是很困难的,因为影响 ABI 的因素非常多,硬件、编程语言、编译器、链接器、操作系统都会影响 ABI。
C 代码层面的 ABI 稳定
从 C 语言的目标代码来说,下面几个因素会影响二进制是否兼容:
- 内置类型的大小和在存储器中的放置方式(大端、小端、对齐方式)。
- 组合类型的存储方式和内存分布。
- 外部符号与用户定义的符号之间的命名方式和解析方式。
- 函数调用方式。
- 堆栈分布方式。
- 寄存器的使用约定。
C ++ ABI 稳定
到了 C++ 时代,做到二进制兼容更是不易,需要考虑:
- 继承类体系的内存分布。
- 指向成员函数的指针的内存分布。
- 如何调用虚函数,vtable 的内容和分布形式,vtable 指针在 object 中的位置。
- 模板如何实例化。
- 外部符号的修饰。
- 全局对象的构造和析构。
- 异常产生和捕获机制。
- 标准库的细节问题和 RTTI 如何实现。
- 内嵌函数访问细节等。
二进制的兼容,一直都是语言发展过程中的重要事务,比如还有很多人还在致力于 C++的标准的统一。
Swift ABI稳定
从16年就接触了 Swift3.0 的开发,当时当时的 Swift 语言还是在飞速迭代的过程中,每次一个小的版本的升级,就会有大量的代码需要改动,我甚至还误以为这个是由于 Swift 的 ABI 不稳定造成的,这其实是错的,直到 Swift 5 发布,Swift 5 最重要的变化就是 ABI Stability,ABI 稳定之后,OS 发行商就可以把 Swift 标准库和运行时作为操作系统的一部分嵌入。也就是说 Apple 会把 Swift runtime 放到 iOS 和 macOS 系统里,我们的 Swift App 包里就不需要包含应用使用的标准库 和 Swift runtime 拷贝了。同时在运行的时候,只要是用 Swift 5 (或以上) 的编译器编译出来的 Binary,就可以跑在任意的 Swift 5 (或以上) 的 runtime 上。
ABI & API
此外有个与之对应的有个概念叫做 API,实际上它们都是应用程序接口,只是接口所在层面不同:
- API 是指源代码级别的接口
- ABI 是指二进制层面的接口。
大端小端
-
就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。

-
就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。

静态库链接
静态库可以看做是一组目标文件的集合,举例几个 C 语言的运行的库:
| C运行库 | 相关 DLL | 相关 DLL |
|---|---|---|
| libcmt.lib | Multithreaded Static 多线程静态库 | |
| msvert.lib | msver90.dll | Multithreaded Dynamic 多线程动态库 |
| libcmtd.lib | Multitbreaded Static Debug 多线程静态调试库 | |
| msvertd.lib | msvert90d.dll | Multichreaded Dynamic Debug 多线程动态调试库 |
链接使用到静态库的过程如下所示,其实目标文件中使用了printf函数:
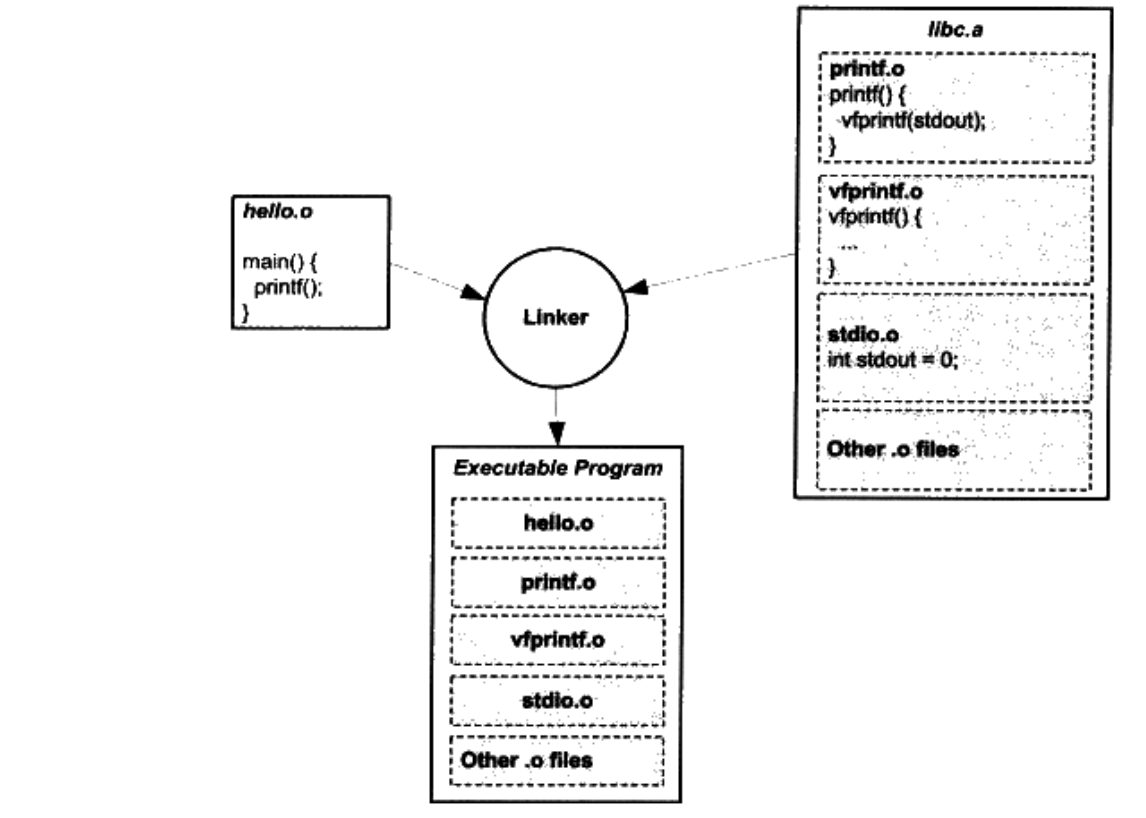
然而我们直接将 hello.o 和 printf.o 链接在一起 ld hello.o print.o,却报错了,其原因是 printf.o 中使用到了其他的库文件。
链接过程控制
特殊情况下我们需要控制链接规则,这就引出了链接过程控制。一共有三种办法做到控制:
- 指定链接器参数,-o -e 之类。
- 将链接指令放在目标文件里面。
- 使用链接控制脚本。
本身是存在默认的链接脚本的,例如在 Intel IA32下,我们使用 ld 链接生成可执行文件时,默认使用的 elf_i386.x 脚本,使用 ld 链接生成共享目标文件时,默认使用的是 elf_i386.xs 脚本。当然我们可以自己写脚本,来控制链接过程。
作者举了一个使用 ld 脚本干预链接的例子,程序代码结合的是 GCC 内嵌汇编,不借助库函数,可以打印 Hello World 程序,代码如下:
char* str = "Hello world! \n";
void print () {
asm("movl $13, %%edx \n\t"
"movl %0, %%ecx \n\t"
"movl $0, %%ebx \n\t"
"movl $4, %%eax \n\t"
"int $0x80 \n\t"
:: "r"(str): "edx", "ecx", "ebx");
}
void exit () {
asm("movl $42, %ebx \n\t"
"movl $1, %eax \n\t"
"int $0x80 \n\t");
}
void nomain () {
print();
exit();
}
编译:gcc -c -fno-builtin TinyHelloWorld.c
链接:ld -static -e nomain -o TinyHelloWorld TinyHelloWorld.o
这段代码的可执行代码一共会生成4个段,使用 ld 脚本可以合并部分段,并删除多余的段,脚本如下:
ENTRY (nomain)
SECTIONS {
. = 0x08048000 + SIZEOF_HEADERS;
tinytext : { *(.text) *(.data) *(.rodata) }
/DISCARD/ : { *(.comment) )
}
脚本一共做了几件事呢?
- 第一行执行了程序的入口为
nomain。 - SECTIONS 里面是变换规则,第一句的意思是设置 tinytext 的段的起始虚拟地址为
0x08048000 + SIZEOF_HEADERS。 - 第二句意思是将 .text 段、.data 段、.rodata 段合并为 tinytext 段。
- 第三句意思是将 .comment 段丢弃。
Note:除了 tinytext 段之外,其实还会同时存在 .shstrtab 段、.symtab 段、.strtab 段(段名字符串表、符号表、字符串表)
此外,现在的 GCC 都是通过 BFD 库来处理目标文件的,BFD 库会把目标文件抽象成一个统一的模型,然后就可以操作所有支持 BFD 支持的目标文件格式。
目标文件里有什么
整体结构
目前流程的可执行文件的格式分为两种,Windows 下的 PE 和 Linux 下的 ELF,均为 COFF 的变种,目标文件是源代码经过编译后但是没有进行链接的中间文件,结构和内容和可执行文件类似,Windows 下目标文件和可执行文件统称为 PE/COFF 文件格式,Linux 系统下统称为 ELF 的文件。
此外,除了可执行性文件,动态链接库(Linux 下的 .so)、静态链接库(Linux 下的 .a)都是按照可执行文件的格式存储,在 Linux 下可以通过 file 命令查看具体类型。
ELF 目标文件的总体结构如下,之所以 Section Table 和 .rel.text 与前一个段有间隔,是因为内存对齐的原因:
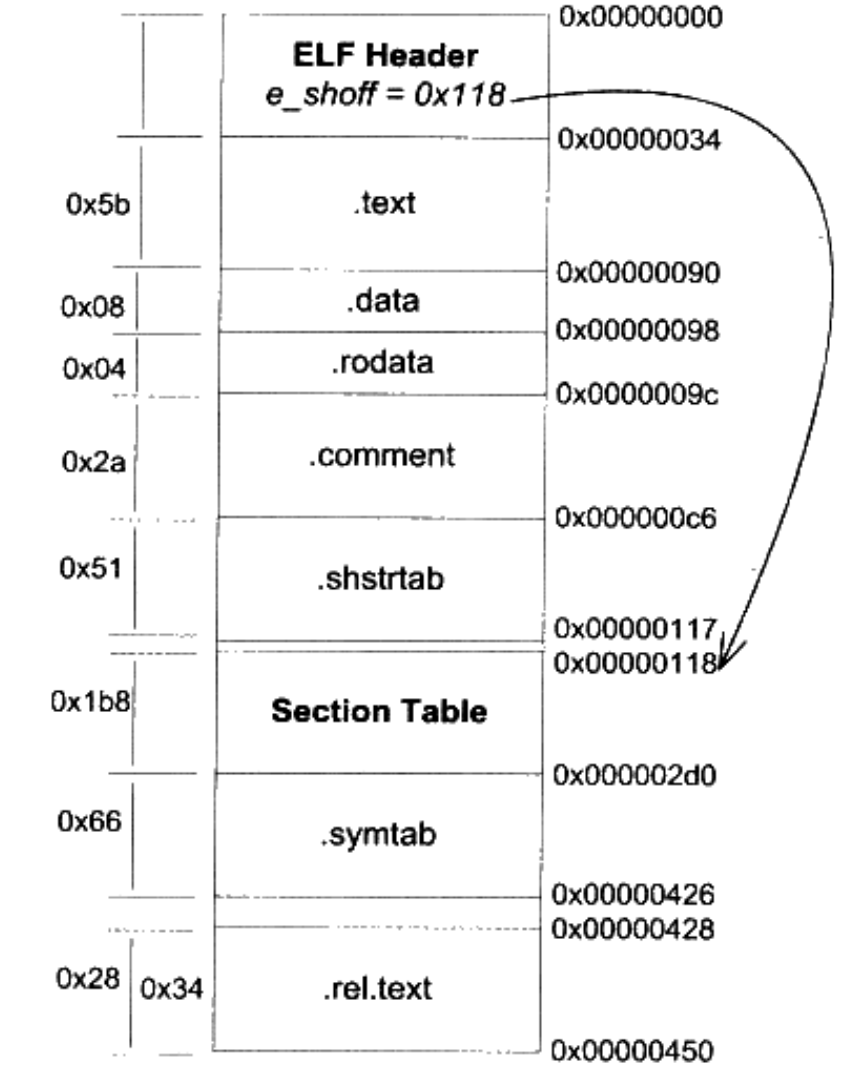
- ELF 开头是一个头文件,描述了整个文件的文件基本属性,了 ELF 魔数、文件机器字节长度、数据存储方式、版本、运行平台、ABI 版本、ELF 重定位类型、硬件平台、硬件平台版本、入口地址、程序头入口和长度、段表的位置和长度及段的数量等。
- 头文件还包括一个段表
Section Table,是一个描述各个段的数组,描述了段名、段的长度、在文件的偏移位置、读写权限以及段的其他属性。编译器、链接器和装载器都是依靠段表来定位和访问各个段的属性。 - 头文件后是各个段的内容。
- 执行语句编译成的机器代码在代码段(.text 段)。
- 已经初始化的全局变量和局部静态变量都在数据段(.data 段)。
- 未初始化的全局变量和局部静态变量一般放在一个叫 BSS 段中。(BSS 段只是预留位置,在文件中不会占据空间)
- 其他段…
总体说,程序代码被编译后主要分为两种,程序指令和程序数据,为什么指令和数据分开来放呢?
- 方便权限划分(只读和可读写等)。
- 划分了空间,提高 CPU 缓存的命中率。
- 方便指令或者数据的复用性,节省内存。比如说“共享指令”。
段表
段表 Section Header Table 用于保存 ELF 文件中的所有段的基本属性的结构,是除了文件头以外中重要的结构,描述了各个段的段名、段的长度、在文件中的偏移、读写权限、以及段的其他属性。编译器、链接器、装载器都是依靠段表来定位各个段的和访问各个段的,段表在 ELF 文件的位置是由 ELF 文件头中的 e_shoff 成员决定的。段表其实是一个 EIf32_Shdr 的结构体的数组,里面包含段名 sh_name、段类型 sh_type、段的标志位 sh_flags、段的虚拟地址 sh_addr、段的偏移 sh_offset、段的长度 sh_size、段的链接信息 sh_link 和 sh_info、段的地址对齐 sh_addralign 等等。
段的名字只是在链接和编译过程中有意义,但是不能真正标识段的类型,段的属性是由段的类型 sh_type 和段的标志位 sh_flag 共同来决定的。段的类型是由 SHT_ 开头的,例如 SHT_PROGBITS 代表代码段、数据段,SHT_SYMTAB 代表符号表,SHT_STRTAB 代表字符串表。
段的标志位 sh_flag 标识了段是否可写、可执行,以 SHF_ 开头,例如SHF_WRITE 代表段在进程空间中可写, SHF_ALLOC 代表进程空问中须要分配空间
下面列举几种常见的系统保留段的段类型和段标志如下:
| Name | sh_type | sh flag |
|---|---|---|
| .bss | SHT_NOBITS | SHF_ALLOC + SHF_WRITE |
| .data | SHT_PROGBITS | SHF_ALLOC + SHF_WRITE |
| .shstrtab | SHT_STRTAB | none |
| .strtab | SHT_STRTAB | 如果该 ELF 文件中有可装載的段须要用到该字符串表,那么该字符串表也将被装载到进程空问,则有 SHF_ALLOC 标志位 |
| .symtab | SHT_SYMTAB | 同字符串表 |
| .text | SHT_PROGBITS | SHF_ALLOC + SHF_EXECINSTR |
下面介绍段的链接信息,如果段是与链接有关的(静态链接或者动态链接),比如说重定位表、符号表,在 sh_link 和 sh_info 字段中会包含链接相关的信息。
| sh_type | sh_link | sh_info |
|---|---|---|
| SHT_DYNAMIC | 该段所使用的字符串表在段表中的下标 | 0 |
| SHT_HASH | 该段所使用的符号表在段表中的下标 | 0 |
| SHT_REL | 该段所使用的相应符号表在段表中的下标 | 该重定位表所作用的段在段表中的下标 |
| SHT_RELA | 该段所使用的相应符号表在段表中的下标 | 该重定位表所作用的段在段表中的下标 |
| SHT_SYMTAB | 操作系统相关的 | 操作系统相关的 |
| SHT_DYNSYM | 操作系统相关的 | 操作系统相关的 |
| other | SHN UNDEF | 0 |
常见段
| 常用的段名 | 说明 |
|---|---|
| .text | 程序指令 |
| .data | 已经初始化的全局静态变量和局部静态变量 |
| .rodata | 程序里的只读数据 |
| .bss | 未初始化的全局变量和局部静态变量 |
| .comment | 注释信息段 |
| .note.GNU-stack | 堆栈提示段 |
| .rodata1 | Read only Data,这种段里存放的是只读数据,比如字符串常量、全局 const变量。跟 “.rodata” 一祥 |
| .comment | 存放的是编译器版本信息,比如字符串:“GCC: (GNU) 4.2.0” |
| .debug | 调试信息 |
| .dynamic | 动态链接信息 |
| .hash | 符号哈希表 |
| .line | 调试时的行号表,即源代码行号与编译后指令的对应表 |
| .note | 额外的编译器信息。比如程序的公司名、发布版本号等 |
| .strtab | String Table 字符串表,用于存储ELF文件中用到的各种字符串 |
| .symtab | Symbol Tabie 符号表 |
| .shstrtab | Section String Table 段名表 |
| .plt .got | 动态链接的跳转表和全局入口表 |
| .init .fini | 程序初始化与终结代码段 |
为了了解常见的段,我们先自己编译一段代码 SimpleSection.c:
int printf (const char* format, ...);
int global_init_var = 84;
int global_uninit_var;
void func1(int i) {
printf( "%d\n",i);
}
int main(void) {
static int static_var = 85;
static int static_var2;
int a = 1;
int b;
func1(static_var + static_var2 + a + b);
return a;
}
只编译不链接该 SimpleSection.c 文件: gcc -c SimpleSection.c
得到 SimpleSection.o,SimpleSection.o 即为目标文件。
我们使用 objdump -h SimpleSection.o 查看其内部结构:
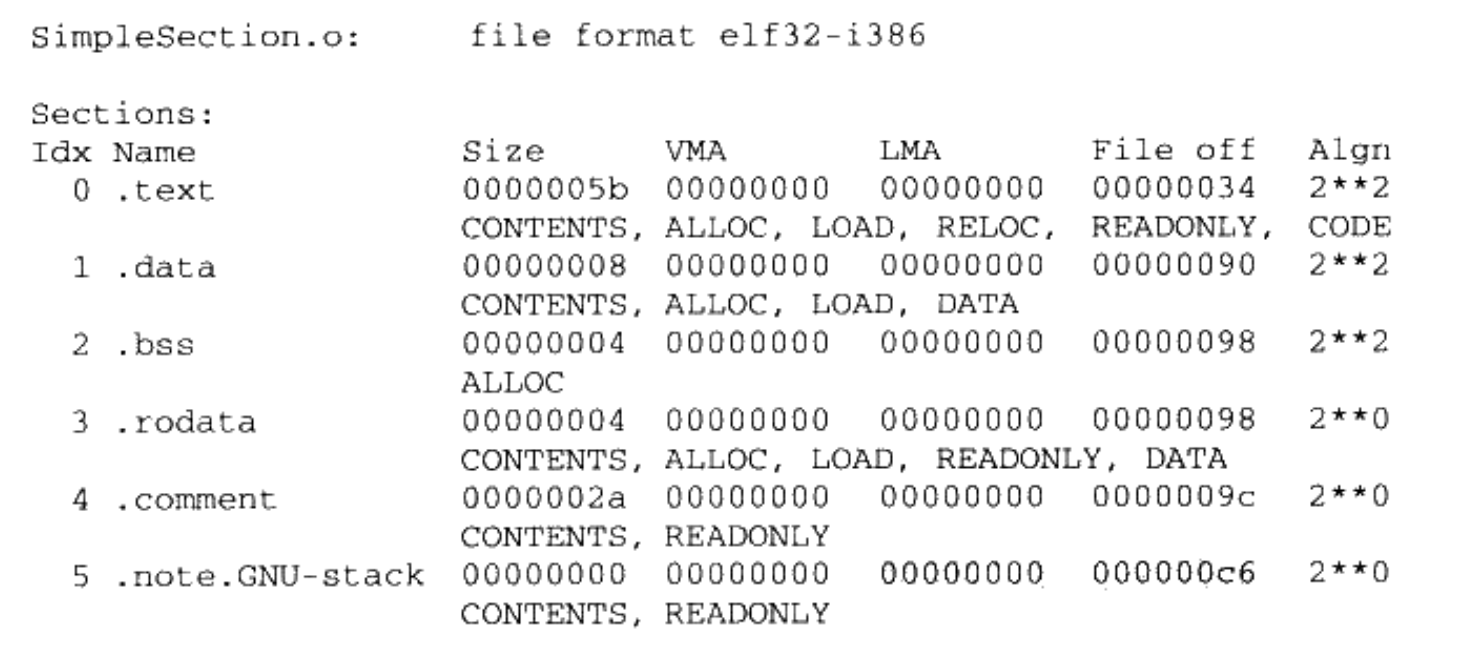
除了上面我们提到过的代码段,数据段,BSS 段之外,还有三个段分别为只读数据段(.rodata 段),注释信息段(.comment 段),堆栈段(.note.GNU-stack),首先 BSS 段和堆栈段认为在文件中不存在,实际存在的段的分布情况如下:
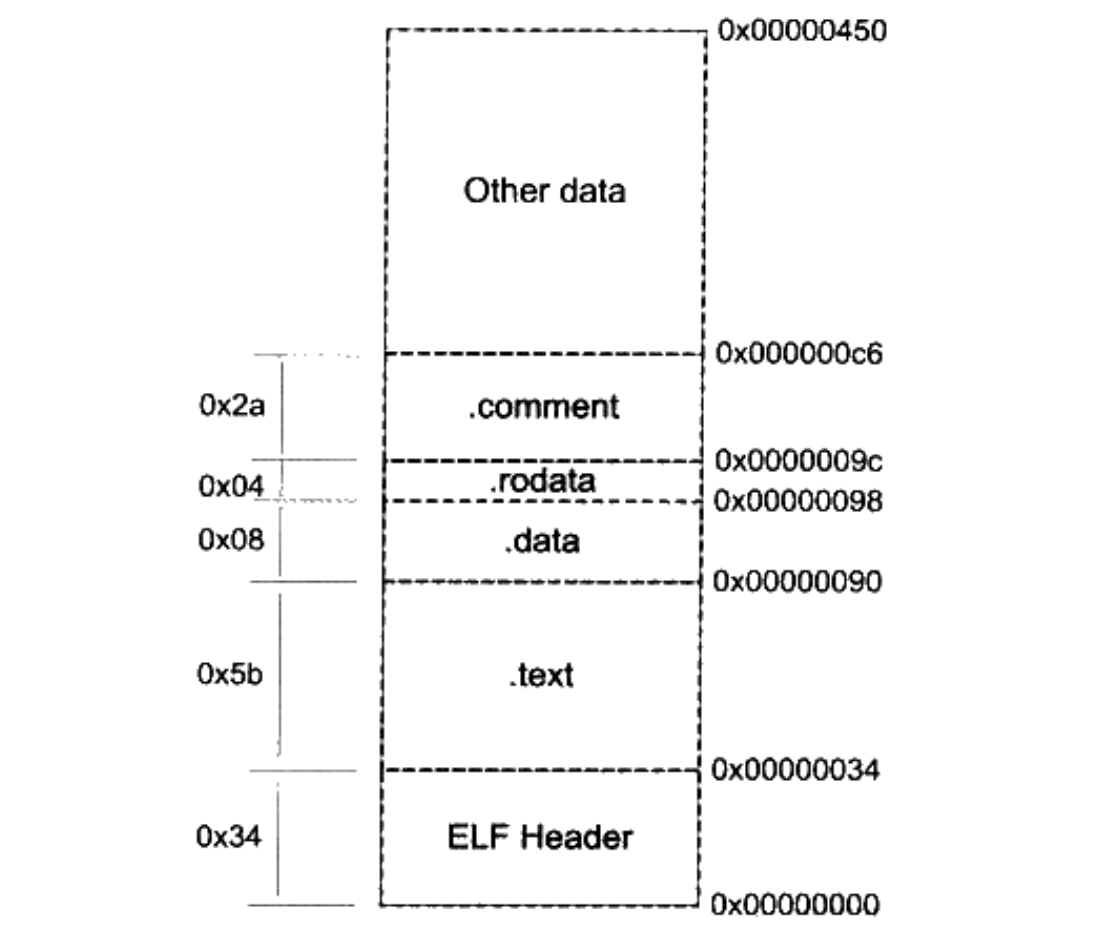
使用 size 命令可以查看各个段的长度:size SimpleSection.o
text data bss dec hex filename
95 8 4 107 6b SimpleSection.o
代码段
使用 objdump -s -d SimpleSection.o 可以查看所有段的十六进制内推以及所有包含指令的反汇编,我们着重看下代码段的内容:

可见代码段里面包含就是两个函数 func1() 和 main() 函数的指令。
数据段和只读数据段
中存放的是已经初始化的全局静态变量和局部静态变量,上述代码中的中的 global_init_var 和 static_var 为全局静态变量和局部静态变量,加一起一共是 8 个字节,在调用 printf 函数的时候,用到了一个字符串常量,是一种只读数据,放入了 .rodata 段,刚好是 4 个字节。
BSS段
编译单元内部可见的未初始化的静态变量的确放到了BSS 段,但是未初始化的全局变量却不一定放在 BSS 段,例如上述代码中的 global_uninit_var 和 static_var2 就应该放在了BSS 段,但是我们看到该段只有四个字节的大小,其实只有 static_var2 放在了BSS 段,而 global_uninit_var 却没有放进任何段,只是一个未定义的 COMMON 符号,具体的原因我们放到下面关于符号的位置来讲解。
重定位表
链接器在处理目标文件的时候,需要对代码段和数据段中绝对地址的引用位置进行重定位,重定位的信息会记录在 ELF 文件的重定位表里,对于需要进行重定位的代码段或者数据段,都会需要一个重定位表,.rel.text 是针对代码段的重定位表,.rel.data 是针对数据段的重定位表,重定位表的 sh_type 为 SHT_REL,而 sh_link 字段记录该段所使用的相应符号表在段表中的下标,sh_info 表示该重定位表所作用的段在段表中的下标。
字符串表
ELF 文件中有许多类似于段名、变量名之类的字符串,使用字符串表,通过定义在表中的偏移来引用。字符串表在 ELF 中也是以段的形式存在.
.strtab字符串表.shstrtab段表字符串表
结合 ELF 头文件中的 e_shstrndx 即可找到段表和段表字符串表的位置,从而解析 ELF 文件。
自定义段
我们可以自己插入自定的段,做一些特定的事情,但是自定义段不能使用 . 开头,我们在全局变量或者函数加上 __attribute__((section("name"))) 就可以将相应的变量或者函数放到 name 为名的段中。
符号
链接的本质是将不同的目标文件互相 “粘” 到一起,还记得上文中的拼图吗,很形象生动,而链接中需要使用到的就是符号的名字,我们将函数和变量统称为符号 Symbol,函数名和变量名即符号名。每个目标文件中都会有一个符号表 Symbol Table,每个符号都有对应的符号值,对于变量和函数,符号值就是它们的地址。
常见的符号类型
- 定义在本目标文件的全局符号,可以被其他目标文件引用。
- 外部符号,即在本目标文件中引用的全局待号,却没有定义在本目标文件。
- 段名,这种符号往往由编译器应生,它的值就是该段的起始地址。
- 局部符号,这类符号只在编译单元内部可见。
- 行号信点。
使用 nm 可以查看目标文件的符号表: nm SimpleSection.o 打印的所有符号如下:
00000000 T funcl
00000000 D global_init_var
00000004 C global_uninit_var
0000001b T main
U printf
00000004 d static_var.1286
00000000 b static_var2.1287
符号表结构
符号表也是属于 ELF 文件中的一个段, 段名叫 .symtab,它是一个结构体的数组,结构体里面有几个重要的元素。
我们查看下 64 位的 Elf64_Sym 结构定义如下:
typedef struct {
Elf64_Word st_name;
unsigned char st_info;
unsigned char st_other;
Elf64_Half st_shndx;
Elf64_Addr st_value;
Elf64_Xword st_size;
} Elf64_Sym; //64位
st_info符号类型和绑定信息,低4位表示符号类型,高28位表示符号绑定信息。st_shndx这个值如果符号在目标文件中,这个符号就是表示符号所在的段在段表中的下标,如果符号不在目标文件中,sh_shndx可能会有些特殊,例如SHN_ABS表示该符号包含一个绝对的值,SHN_COMMON表示该符号是一个COMMON块类型的符号,SHN_UNDEF表示符号未定义,可能定义在其他的目标文件中。st_value符号值。- 如果段不是
COMMON块(即st_shndx不为SHN_COMMON),则符号对应的函数或者变量位于由st_shndx指定的段经过st_value偏移所在的位置,这种是目标文件中定义全局变量的最常见的情况。 - 如果是
COMMON块(即st_shndx不为SHN_COMMON),st_value表示符号对齐属性。 - 如果在可执行文件中,
st_value表示符号的虚拟地址,对于动态链接器十分有用。
- 如果段不是
- 此外还有一些特殊符号,例如
__executable_start为程序起始地址,__etext或_etext或etext标识代码段结束地址等等。
我们使用 readelf 查看 ELF 文件的符号: readelf -s SimpleSection.o:
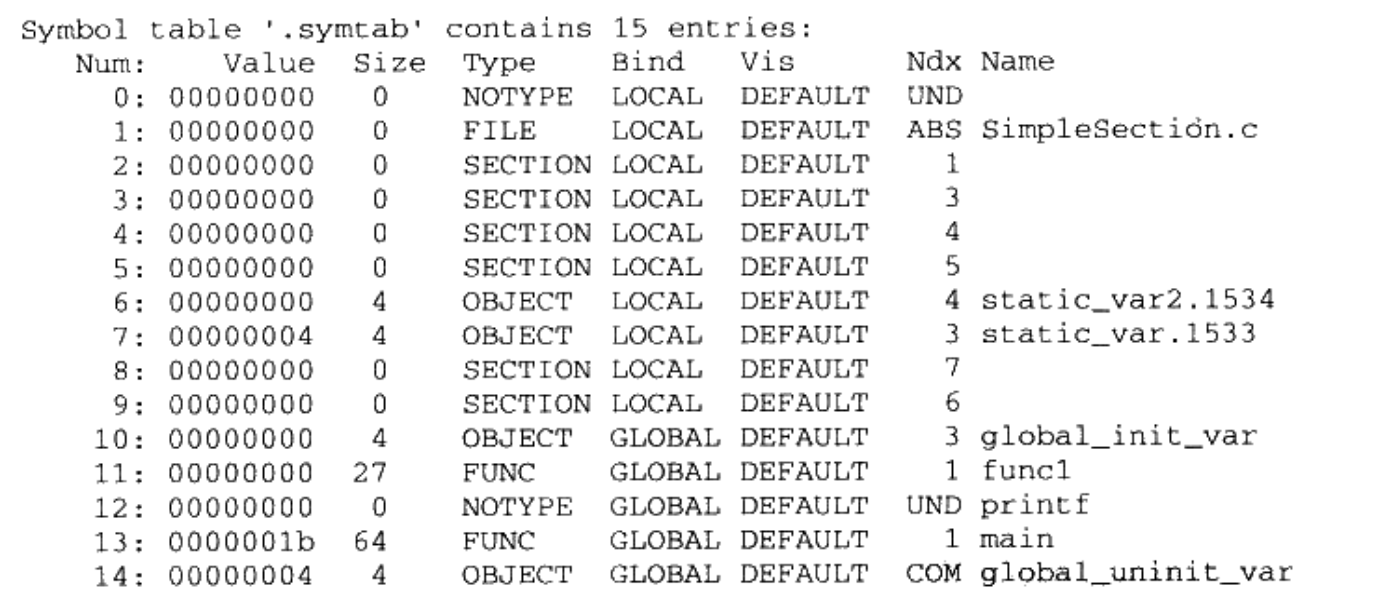
Num 表示符号数组的下标,Value 是符号值,Size 为符号大小,st_info 为符号类型和绑定信息,Ndx 即 st_shndx 表示符号所属的段,举几个例子:
func1和main位置在代码段,Ndx是1,类型为 STT_FUNC,由于是全局可见的,所以是 STB_GLOBAL, Size 表示指令所占字节数, Value表示函数相对于代码段的起始位置的偏移。printf这个符号,在 SimpleSection.c 中被引用,,但是没有定义,所以Ndx是SHN_UNDEF。global_init_var是已初始化的全局变量,定义在 BSS 段,下标为 3.global_uninit_var是未初始化的全局变量,是一个 SHN_COMMON 类型的符号,本身未存在于 BSS 段。static_var和static_var2绑定属性是STB_LOCAL,编译内部单元可见。STT_SECTION,表示下标为Ndx的段的段名,符号名没有显示,其实符号名即为段名。
符号修饰和函数签名
为了防止符号的冲突,Unix系统规定 C 语音源代码的所有的全局变量和函数经过编译后,会在符号前面加上下划线。C++ 为了符号命名冲突的问题,增加了命名空间。
C++ 拥有类、继承、虚机制、重载、命名空间等特性,使得符号管理更为复杂,于是引入了函数签名,函数签名包含函数名。参数类型,所在类以及命名空间等一些列信息,用于识别不同的函数,即便函数名相同,编译器也会更具修饰后的名称,认为它们是不同的函数,修饰后的名称如表:
| 函数签名 | 修饰后名称(符号名) |
|---|---|
| int func(int) | __Z4funci |
| float func(float) | __Z4funcf |
| int C::func(int) | __ZN1C4funcEi |
| int C::C2::func(int) | __ZN1C2C24funcEi |
| int N::func(int) | __ZNIN4funcEi |
| int N::C::func(int) | __ZNINICAfuncEi |
变量的类型没有加入到修饰后的名称中。
C++ 为了和 C 兼容, 还引入了 extern “C” 关键字:
extern "C" {
int func(int);
int var;
}
在 {} 中的代码会被 C++ 编译器当做 C 的代码来处理, 当然 C++ 的名称机制也将不起作用。
如果是单独的某个函数或者变量定义为 C 语言的符号也可以使用 extern:
extern "C" int func(int);
extern "C" int var;
强符号和弱符号
开发中我们经常会遇到符号被重复定义的错误,比如说我们在两个目标文件中都定义了相同的全局整形变量 global,并将它们同时初始化,那么链接器将两个目标文件链接的时候就会报错,对于 C/C++ 语言来说,这种已初始化的全局符号可以称之为强符号,有些符号的定义称之为弱符号,比如说未初始化的全局符号,强符号和弱符号是针对定义来说的,而不是针对符号的引用。我们也可以使用 __attribute__((weak)),来定义强符号为弱符号,下面我们看一段代码:
extern int ext; // 非强符号也非弱符号
int weak; // 弱符号
int strong = 1; // 强符号
__attribute__((weak)) weak2 = 2; // 弱符号
int main() { // main 强符号
return 0;
}
上段代码的强弱符号已经进行了标注,ext 由于是一个外部变量的引用,非强符号也非弱符号。
链接器会按照下面的三个规则处理与选择多次定义的全局符号:
- 不允许强符号被定义多次(不同的目标文件中不能有同名的强符号,否则链接报错)。
- 如果有一个是强符号其余的是弱符号,则选择强符号。
- 如果不同的目标文件中都是弱符号,则选择占用空间最大的一个。
现在的链接器在处理弱符号的时候,采用的 COMMON 块一样的机制来处理,编译器将未初始化的局部静态变量定义为弱符号,还记得上面我留了一个问题,编译器将未初始化的局部静态变量 static_var2 放在 BSS 段,而 global_uninit_var 属于未初始化的全局符号,没有直接放入 BSS 段,先是标记了 COMMON,按照 COMMON 链接规则,global_uninit_var 的大小以输入文件中最大的那个为准,最终确认了符号的大小,就能放入 BSS 段了。但是有种情况,如果是同时存在强符号和弱符号,那么输出文件和强符号相同,但是如果链接过程中有弱符号大于强符号,那么 ld 就会报出警告。
对于目标文件被链接成可执行文件的阶段,如果是强符号没有被定义将会报错,如果弱符号没有被定义,链接器对于该引用不会报错,一般都会被赋予一个默认值,便于程序代码识别到。但是在运行阶段,可能会发生非法地址访问的错误。
强符号和弱符号的设计对于库来说十分有用,比如:
- 库中定义的弱符号可以被强符号进行覆盖,从而使用自定义的库函数。
- 程序的某些扩展功能模块定义为弱引用,扩展模块和程序一起链接的时候就能使用模块功能,去掉模块功能也能正确链接,只是缺少部分功能。这个设计使得程序的设计更为灵活,我们可以对大的功能模块进行自由的组合和裁切。
调试信息
调试信息似使得我们进行源代码级别的调试,可以设置断点,监测变量的变化,单步运行,确定目标代码的地址对应源代码中的哪一行、函数和变量的类型等等。
ELF 文件中采用一个叫做 DWARF 标准的调试信息格式,调试信息占用空间比较大,我们再发布程序的时候,往往需要使用 strip 命令来去掉 ELF 文件中的调试信息。
DWARF
一种通用的调试文件格式,支持源码级别的调试,调试信息存在于 对象文件中,一般都比较大。Xcode 调试模式下一般都是使用 DWARF 来进行符号化的。
通过 DWARF 清晰的看到函数的描述、行号、所在文件、虚拟地址等重要信息,有了这些信息,就可以实现单步调试以及查看 Crash 堆栈等能力。
说到 DWARF 可能我们还不是很熟悉,但是有一个文件,iOS 的程序员应该不陌生,那就是 dSYM 文件,日常开发时会遇到 Crash,Crash 里面有很多的堆栈信息,以及 Crash 时所执行的代码的行号,这些信息对定位问题非常重要,这个能力就是依赖 DWARF 和 dSYM 实现的。当然 DWARF 和 dSYM 是公共的标准,并不是只有苹果特有的,只不过主要是苹果在用而已。
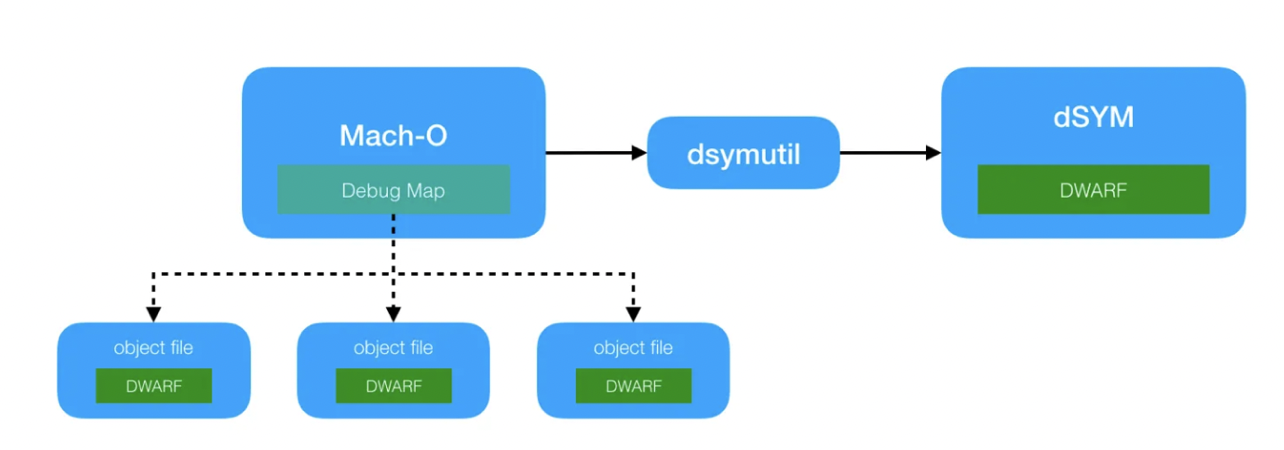
使用 Xcode 编译打包的时候会先通过可执行文件的 Debug Map 获取到所有对象文件的位置,然后使用 dsymutil 来将对象文件中的 DWARF 提取出来生成 dSYM 文件。
Strip
上文说到可以使用 Strip 命令来去掉 ELF 文件中的调试信息,在 Xcode 中其实已经给我们提供了 Strip 编译选项,之所以要在 Release 环境中去掉符号信息,主要是因为调试信息占用的空间太大了,需要进行 App 的瘦身操作。
Strip 命令就是为了去除调试信息,其中符号占据了绝大部分,而可执行文件中的符号是指程序中的所有的变量、类、函数、枚举、变量和地址映射关系,以及一些在调试的时候使用到的用于定位代码在源码中的位置的调试符号,符号和断点定位以及堆栈符号化有很重要的关系。
Xcode 编译实际的操作步骤是:生成带有 DWARF 调试信息的可执行文件 -> 提取可执行文件中的调试信息打包成 dSYM -> 去除符号化信息。去除符号是单独的步骤,使用的是 strip 命令,下面介绍两个有关于 strip 命令的 Xcode 编译选项:
Strip Style
Strip Style 表示的是我们需要去除的符号的类型的选项,其分为三个选择项:
| All Symbols | Non-Global Symbols | Debug Symbols |
|---|---|---|
| 去除所有符号,一般是在主工程中开启 | (保留全局符号,Debug Symbols 同样会被去除),链接时会被重定向的那些符号不会被去除,此选项是静态库/动态库的建议选项。 | 去除调试符号,去除之后将无法断点调试。 |
Strip Linked Product
Xcode 提供给我们 Strip Linked Product 来去除不需要的符号信息(Strip Style 中选择的选项相应的符号),去除了符号信息之后我们就只能使用 dSYM 来进行符号化了,所以需要将 Debug Information Format 修改为 DWARF with dSYM file。
去除符号之后,调试阶段怎么办
去除符号化信息之后我们只能使用 dSYM 来进行符号化,那我们怎么使用 Xcode 来进行调试呢?
Strip Linked Product 选项在 Deployment Postprocessing 设置为 YES 的时候才生效,而在 Archive 的时候 Xcode 总是会把 Deployment Postprocessing 设置为 YES 。所以我们可以打开 Strip Linked Product 并且把 Deployment Postprocessing 设置为 NO,而不用担心调试的时候会影响断点和符号化,同时打包的时候又会自动去除符号信息。
Mach-O 文件
经过 ELF 文件的学习,我们重温一下 iOS 里的 Mach-O 文件格式,Mach-O 是 Mach object 文件格式的缩写,是一种可执行文件、目标代码、共享程序库、动态加载代码和核心 dump,它类似于 Linux 和大部分 UNIX 的原生格式 ELF 以及 Windows 上的 PE。
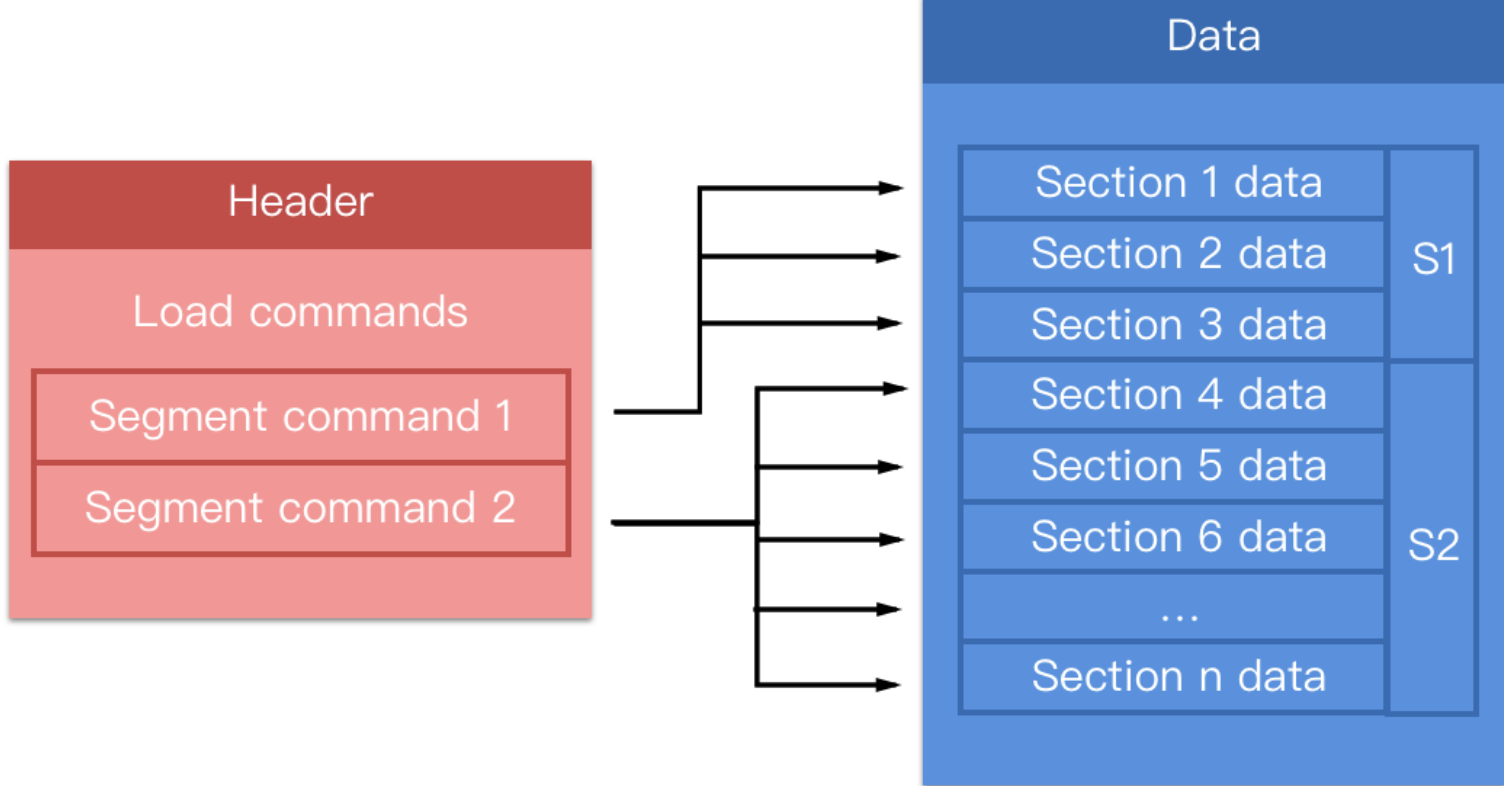
可见其主要包含三个部分:
Header:记录了Mach-O文件的基本信息,包括CPU架构、文件类型和Load Commands等信息。
Load Commands:加载命令部分描述了需要内核加载器或动态连接器等进行的操作指令,如加载数据段、加载动态库等。
Section Data:每一个Segment的数据都保存在此,描述了段名、类型、段偏移,段大小等信息,每个 Segment 拥有一个或多个 Section ,用来存放数据和代码。
Mach-O文件中 中 Data 段之后就都是 __LINKEDIT 部分,具体如下:
| Dynamic Loader Info | 动态加载信息 |
|---|---|
| Function Starts | 函数起始地址表 |
| Symbol Table | 符号表信息 |
| Data in Code Entries | 代码入口数据 |
| Dynamic Symbol Table | 动态符号表 |
| String Table | 字符串表信息 |
| Code Signature | 代码签名 |
String Table 字符串表所有的变量名、函数名等,都以字符串的形式存储在字符串表中。
Symbol Table 符号表,这个是重点中的重点,符号表是将地址和符号联系起来的桥梁。符号表并不能直接存储符号,而是存储符号位于字符串表的位置。
Header
struct mach_header_64 {
uint32_t magic; /* 标识当前 Mach-O位32位(0xfeedface)/ 64位 (0xfeedfacf) */
cpu_type_t cputype; /* CPU 类型 */
cpu_subtype_t cpusubtype; /* CPU 子类型 */
uint32_t filetype; /* 文件类型 */
uint32_t ncmds; /* Load Commands 数量 */
uint32_t sizeofcmds; /* Load Commands 的总大小 */
uint32_t flags; /* 标识位,记录文件的详细信息 */
uint32_t reserved; /* 64位文件特有的保留字段 */
}
Load Commands
Load command描述了文件中数据的具体组织结构,不同的数据类型使用不同的加载命令。它的大小和数目在header中已经被提供。
struct load_command {
uint32_t cmd; /* cmd 类型 */
uint32_t cmdsize; /* cmd size */
};
Load Commands 的部分信息如下:
| LC_SEGMENT_64 | 将文件中的段映射到进程地址空间中 |
|---|---|
| LC_DYLD_INFO_ONLY | 动态链接相关信息 |
| LC_SYMTAB | 符号表地址 |
| LC_DYSYMTAB | 动态符号地址 |
| LC_LOAD_DYLINKER | 指定内核执行加载文件所需的动态连接器 |
| LC_UUID | 指定图像或其对应的dSYM文件的128位UUID |
| LC_VERSION_MIN_MACSX | 文件最低支持的操作系统版本 |
| LC_SOURCE_VERSION | 源代码版本 |
| LC_MAIN | 程序main函数加载地址 |
| LC_LOAD_DYLIB | 依赖库路径 |
| LC_FUNCTION_STARTS | 函数起始表地址 |
| LC_CODE_SIGNATURE | 代码签名 |
几种常见的命令简介如下:
使用最多的是 LC_SEGMENT_64 命令,该命令表示将相应的 segment 映射到虚拟地址空间中,一个程序一般会分为多个段,每一个段有唯一的段名,不同类型的数据放入不同的段中,LC_SEGMENT_64 中包含了五种类型:
PAGEZERO:可执行文件捕获空指针的段TEXT:代码段和只读数据DATA_CONST:常态变量DATA:全局变量和静态变量LINKEDIT:包含动态链接器所需的符号、字符串表等数据
动态链接相关信息:LC_DYLD_INFO_ONLY:
Rebase:进行重定向的位置信息。当 Mach-O 加载到内存里,系统会随机分配一个内存偏移大小ASLR,和rebase里面的offset,对接(位置相加)获取代码在内存中的实际位置。再根据 size 开辟实际内存。Binding:绑定的位置信息Weak Binding:弱绑定的位置信息Lazy Binding:懒加载绑定的位置信息Export:对外的位置信息
LC_SYMTAB 标识了 Symbol Table 和 String Table 的位置。
LC_LOAD_DYLINKER 标识了动态连接器的位置,用来加载动态库等。
Mach-O 程序入口:设置程序主线程的入口地址和栈大小 LC_MAIN,反编译后根据 LC_MAIN 标识的地址可以找到入口 main 代码,dyld 源码中 dyld::_main 可以看到 LC_MAIN 的使用,获取入口和调用。
LC_LOAD_DYLIB 是比较重要的加载动态库的指令,Name 标识了具体的动态库的路径,对一个 Mach-O 注入自定义的动态库时就是在 Load Commands 和 Data 中间添加 LC_LOAD_DYLIB 指令和信息进去。
Data
Data 分为 Segment 和 Section 两个部分,存放代码、数据、字符串常量、类、方法等。
Segment 结构体定义如下:
struct segment_command_64 { /* for 64-bit architectures */
uint32_t cmd; /* Load Commands 部分中提到的cmd类型 */
uint32_t cmdsize; /* cmd size */
char segname[16]; /* 段名称 */
uint64_t vmaddr; /* 段虚拟地址(未偏移),真实虚拟地址要加上 ASLR 的偏移量 */
uint64_t vmsize; /* 段的虚拟地址大小 */
uint64_t fileoff; /* 段在文件内的地址偏移 */
uint64_t filesize; /* 段在文件内的大小 */
vm_prot_t maxprot; /* maximum VM protection */
vm_prot_t initprot; /* initial VM protection */
uint32_t nsects; /* 段内 section数量 */
uint32_t flags; /* 标志位,用于描述详细信息 */
};
而对于__TEXT 和 __DATA 这两个 Segment,则可以继续分解为 Section,从而形成 Segment -> Section 的结构。之所以要这样设计,是因为在同一个 Segment 下的 Section 可以拥有相同的控制权限,并且可以不完全按照 Page 的大小进行内存对齐,从而达到节约内存的效果。
Section 结构体定义如下:
struct section_64 { /* for 64-bit architectures */
char sectname[16]; /* section名称 */
char segname[16]; /* 所属的segment名称 */
uint64_t addr; /* section在内存中的地址 */
uint64_t size; /* section大小 */
uint32_t offset; /* section在文件中的偏移*/
uint32_t align; /* 内存对齐边界 */
uint32_t reloff; /* 重定位入口在文件中的偏移 */
uint32_t nreloc; /* 重定位入口数量 */
uint32_t flags; /* flags (section type and attributes)*/
uint32_t reserved1; /* reserved (for offset or index) */
uint32_t reserved2; /* reserved (for count or sizeof) */
uint32_t reserved3; /* reserved */
};
常见的__TEXT Segment 的 Section 如下:
__text: 可执行文件的代码区域__objc_methname: 方法名__objc_classname: 类名__objc_methtype: 方法签名__cstring: 类 C 风格的字符串
常见的__DATA Segment 的 Section 如下
__nl_symbol_ptr: 非懒加载指针表,dyld 加载会立即绑定__ls_symbol_ptr: 懒加载指针表__mod_init_func: constructor 函数__mod_term_func: destructor 函数__objc_classlist: 类列表__objc_nlclslist: 实现了 load 方法的类__objc_protolist: protocol 的列表__objc_classrefs: 被引用的类列表__objc _catlist: Category 列表
我们可以使用系统自带查看 Mach-O 的工具:
file: 查看 Mach-O 的文件类型nm: 查看 Mach-O 文件的符号表otool: 查看 Mach-O 特定部分和段的内容lipo: 常用于多架构 Mach-O 文件的处理
总结
-
编译过程主要是分为 词法分析、语法分析、语义分析、生成中间代码、目标代码的生成与优化。
-
链接的过程主要涉及到空间地址的分配、符号的解析、重定位等过程,我们可以对链接的过程通过脚本等加以控制,合并部分段,忽略个别段等。
-
ELF 文件的主要构成,文件头、段表、各种常见段(代码段、数据段、BSS 段、只读数据段等)。
-
关于符号大家也有了基本的认知,常见符号类型(全局符号、外部符号、段名等)。
-
符号表提供的值得关注的信息(符号类型和绑定信息,符号所占位置、符号值),为了解决符号的冲突,C 编译后会在符号前加上下划线,C++ 编译器提供了修饰后的名称。
-
符号分为强符号和 弱符号,对于 C/C++ 语言来说,已初始化的全局符号可以称之为强符号,未初始化的全局符号为弱符号。
-
DWARF一种通用的调试文件格式,支持源码级别的调试,但是所占体积较大,我们可以使用Strip命令来去掉 ELF 文件中的调试信息。 -
Mach-O 是 MacOS/iOS 系统下的执行文件等的格式,有
Header、Load Command、Data组成。