
继续学习《程序员的自我修养 - 链接、装载与库》的第三个大的部分,前两篇内容参见:
《程序员的自我修养(链接、装载与库)》学习笔记一(温故而知新)
《程序员的自我修养(链接、装载与库)》学习笔记二(编译和链接)
这一篇包含本书的六、七章节,这两个章节中作者给我们讲解了可执行文件的装载以及动态链接的过程,操作系统是如何将程序装载到内存中运行,如何为程序的代码、数据、堆、 栈在进程地址空间中分配,分布。动态链接是如何有效的利用内存和磁盘资源,如何让程序代码的重用变得更加可行和有效等等。
经过上面几个章节章节的学习,我们已经知道了什么是可执行文件,以及可执行文件的静态链接过程,下面我们思考几个问题:
- 为什么有了静态链接,还需要动态链接?静态链接和动态链接有什么区别呢?
- 可执行文件只有被装载到内存以后才能被 CPU 执行,装载的基本过程是什么样的呢?
- 共享对象根据模块位置和引用方式的不同分为:模块内跳转、模块内数据访问、模块外跳转、模块外数据访问,这四种类型的寻址方式有何不同?
- 装载时重定位和地址无关代码是解决绝对地址引用问题的两个方法,这两种方式的利弊都是什么?
下面我们带着这些问题进行第六七章节的学习。首先看下这两个章节的知识点分布:
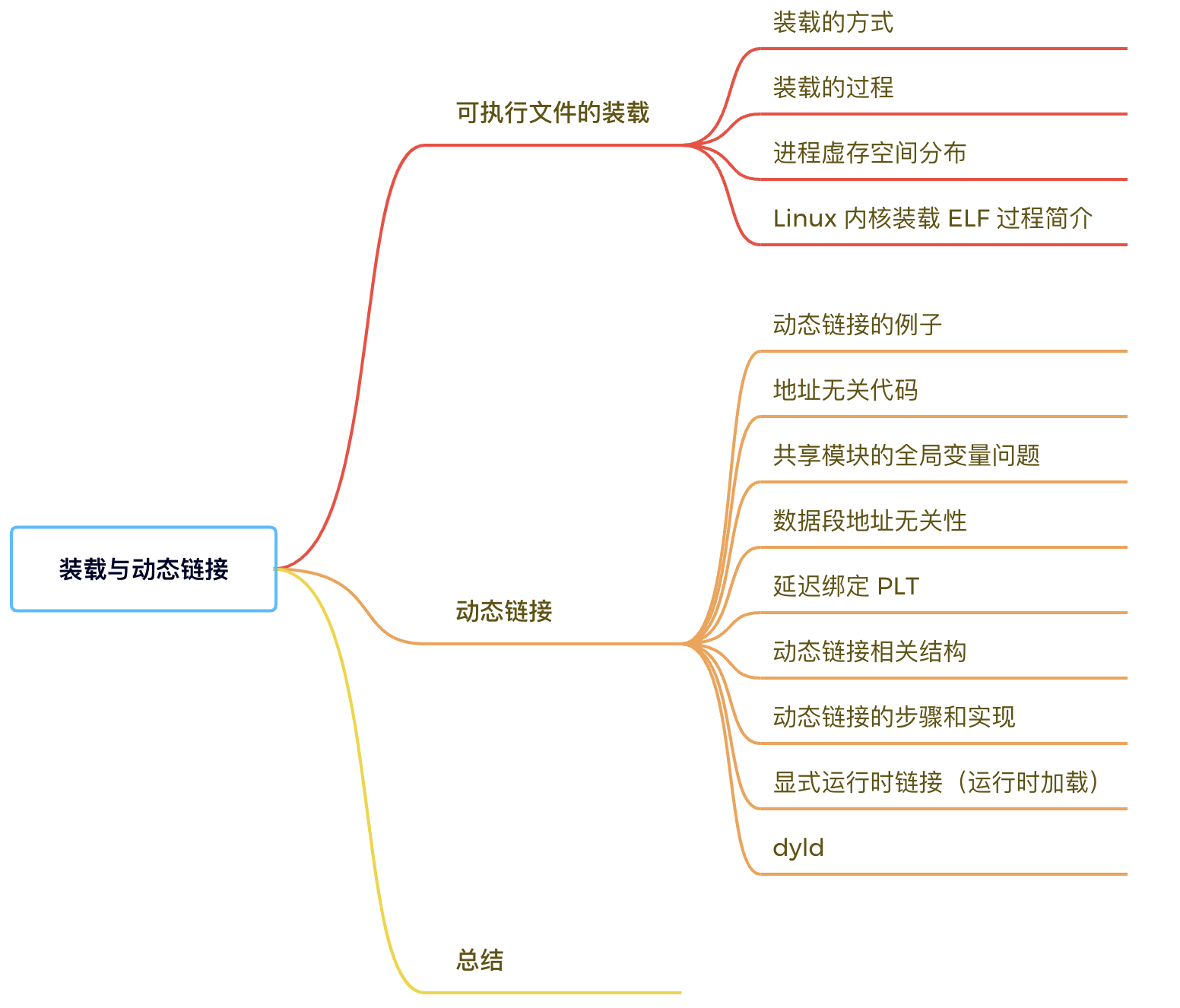
可执行文件的装载
装载的方式
- 全部载入内存
程序执行时所需要的指令和数据必须在内存中才能够正常运行,最简单的办法就是将程序运行所需要的指令和数据全装入内存中。
- 根据局部性原理进行载入
程序运行时是有局部性原理的,所以可将程序最常用的部分驻留在内存中,不太常用的数据存放在磁盘里面,这就是动态装入的基本原理,**覆盖装入(Overlay)和页映射(Paging)**是两种很典型的动态装载方法。
覆盖装入
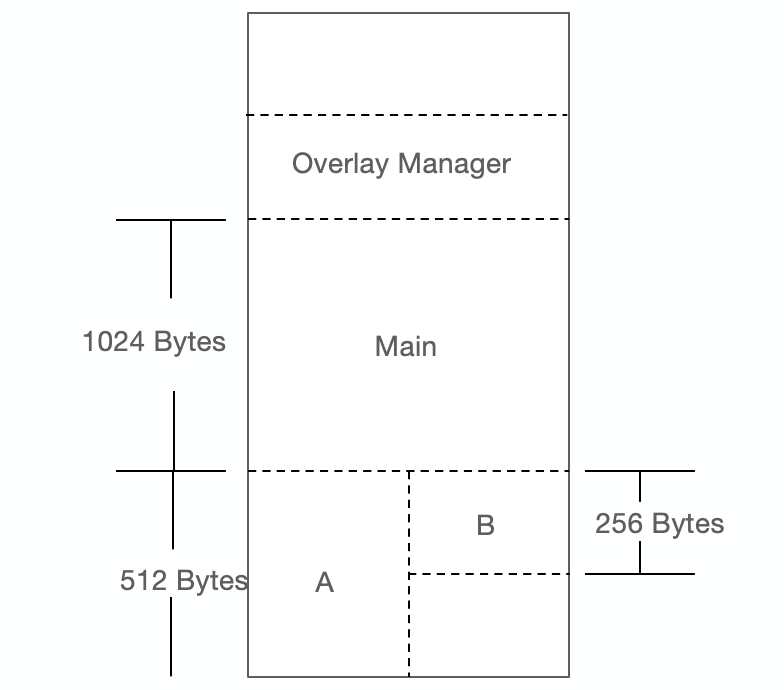
一个程序有主模块 main,main 分别会调用到模块 A 和模块 B,但是 A 和 B 之 间不会相互调用,这三个模块的大小分别是 1024 字节、512 字节和 256 字节。假设不考虑内存对齐、装载地址限制的情况,理论上运行这个程序需要有 1792 个字节的内存,当采用内存覆盖装入的办法,会按照下图的方式安排内存,我们可以把模块 A 和模块 B 在内存中相互覆盖,即两个模块共享块内存区域,除了覆盖管理器,整个程序运行只需要 1536 个字节,比原来的方案节省了 256 字节的空间。
在多个模块的情况下,程序员需要手工将模块按照它们之间的调用依赖关系组织成树状结构。例如下图,模块 main 依赖于模块 A 和 B,模块 A 依赖于 C 和 D,模块 B 依赖于 E 和 F,则它们在内存中的覆盖方式如下图:
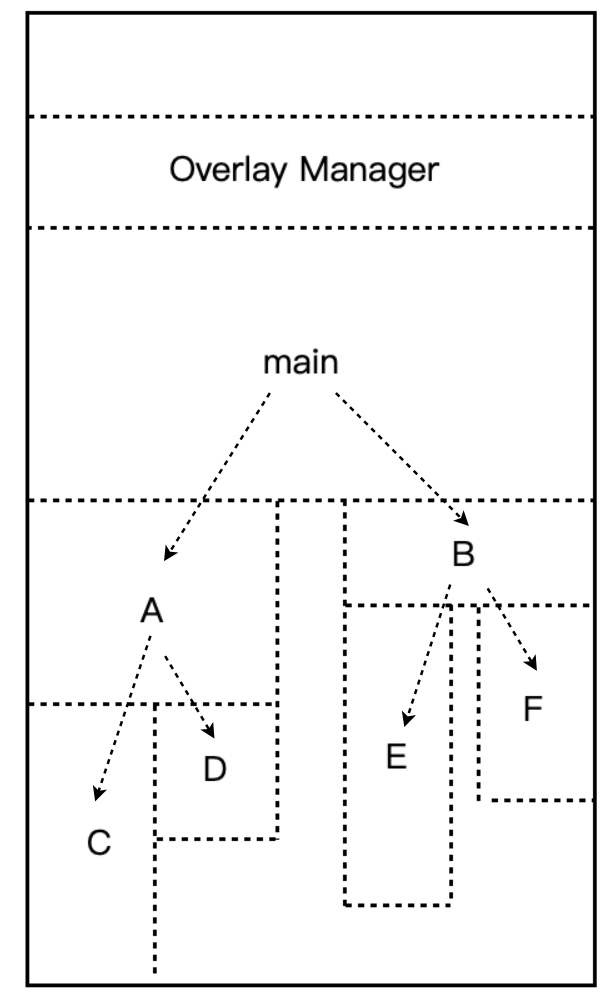
覆盖管理器需要保证两点:
- 这个树状结构中从任何一个模块到树的根模块都叫调用路径。当该模块被调用时,整个调用路径上的模块必须都在内存中。
- 禁止跨树间调用。任意一个模块不允许跨过树状结构进行调用。
覆盖装入的方法把挖掘内存潜力的任务交给了程序员,程序员在编写程序的时候必须手工将程序分割成若干块,然后编写一个小的辅助代码来管理这些模块何时应该驻留内存而何时应该被替换掉,一旦模块没有在内存中,还需要从磁盘或其他存储器读取相应的模块,所以覆盖装入的速度肯定比较慢,不过这也是一种折中的方案,是典型的利用时间换取空间的方法,现在已经几乎被淘汰了。
页映射
页映射是将内存和所有磁盘中的数据和指令按照页**(Page)**为单位划分成若干个页,装载和操作的单位就是页。假设我们的 32 位机器有 16 KB 的内存,每个页大小为 4096 字节,共有 4 个页,假设程序所有的指令和数据总和为 32 KB,那么程序总共被分为 8 个页。我们将它们编号为 P0~P7。16 KB 的内存无法同时将 32 KB 的程序装入,于是我们将按照动态装入的原理来进行装入。如果程序刚开始执行时的入口地址在 P0,这时装载管理器发现程序的 P0 不在内存中,于是将内存 F0 分配给 P0,并且将 P0 的内容装入 F0,运行一段时间以后,程序需要用到 P5,于是装载管理器将 P5 装入F1,当程用到 P3 和 p6 的时候,它们分别被装入到了 F2 和 F3,映射关系如下图:
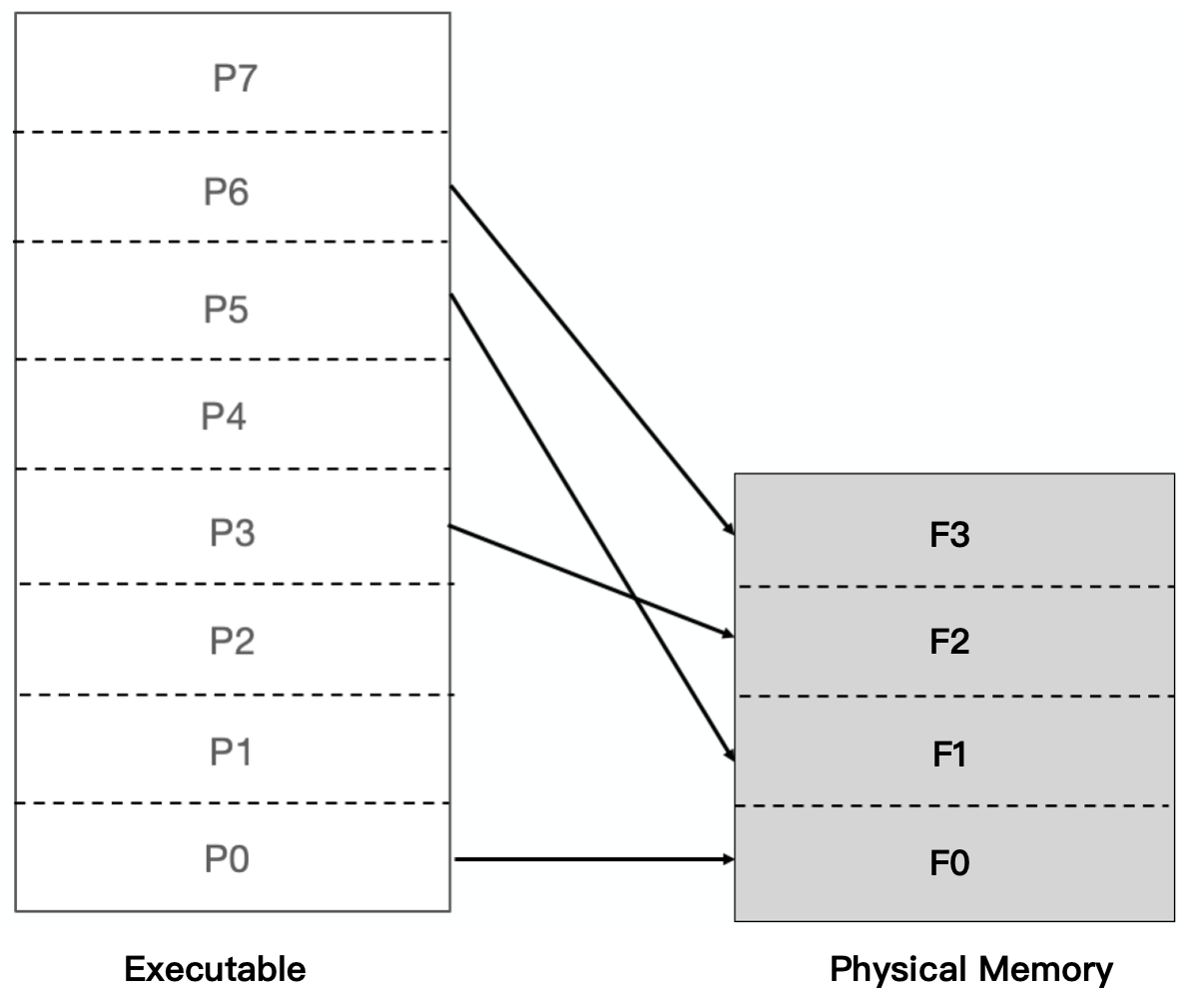
但如果这时候需要访问第 5 个页,那么装载管理器必须做出抉择,它必须放弃目前正在使用的 4 个内存页中的其中一个来装载新的页。至于选择哪个页,我们有很多种算法可以选择:
- 使用 FIFO 先进先出算法选择第一个被分配掉的内存页。
- 使用 LRU 最少使用算法选择很少被访问到的页。
装载的过程
进程建立
- 创建一个独立的虚拟地址空间。
- 创建一个虚拟空间实际上是创建映射函数所需要的相应的数据结构。
- 创建虚拟地址实际只是创建页目录,甚至不设置页映射关系,这些映射关系等到后面程序发生页错误的时候再进行设置。
- 读取可执行文件头,并且建立虚拟空间与可执行文件的映射关系。
-
当程序执行发生页错误时,操作系统将从物理内存中分配一个物理页,然后将该缺页从磁盘中读取到内存中,再设置缺页的虚拟页和物理页的映射关系,这样程序才得以正常运行。当操作系统捕获到缺页错误时,它应知道程序当前所需要的页在可执行文件中的哪一个位置。
-
这种映射关系只是保存在操作系统内部的一个数据结构。Linux 中将进程虚拟空间中的一个段叫做虚拟内存区域
VMA,在 Windows 中将这个叫做虚拟段Virtual Section。
-
- 将 CPU 的指令寄存器设置成可执行文件的入口地址,启动运行。
- 从进程的角度看这一步可以简单地认为操作系统执行了一条跳转指令,直接跳转到可执行文件的入口地址。
页错误
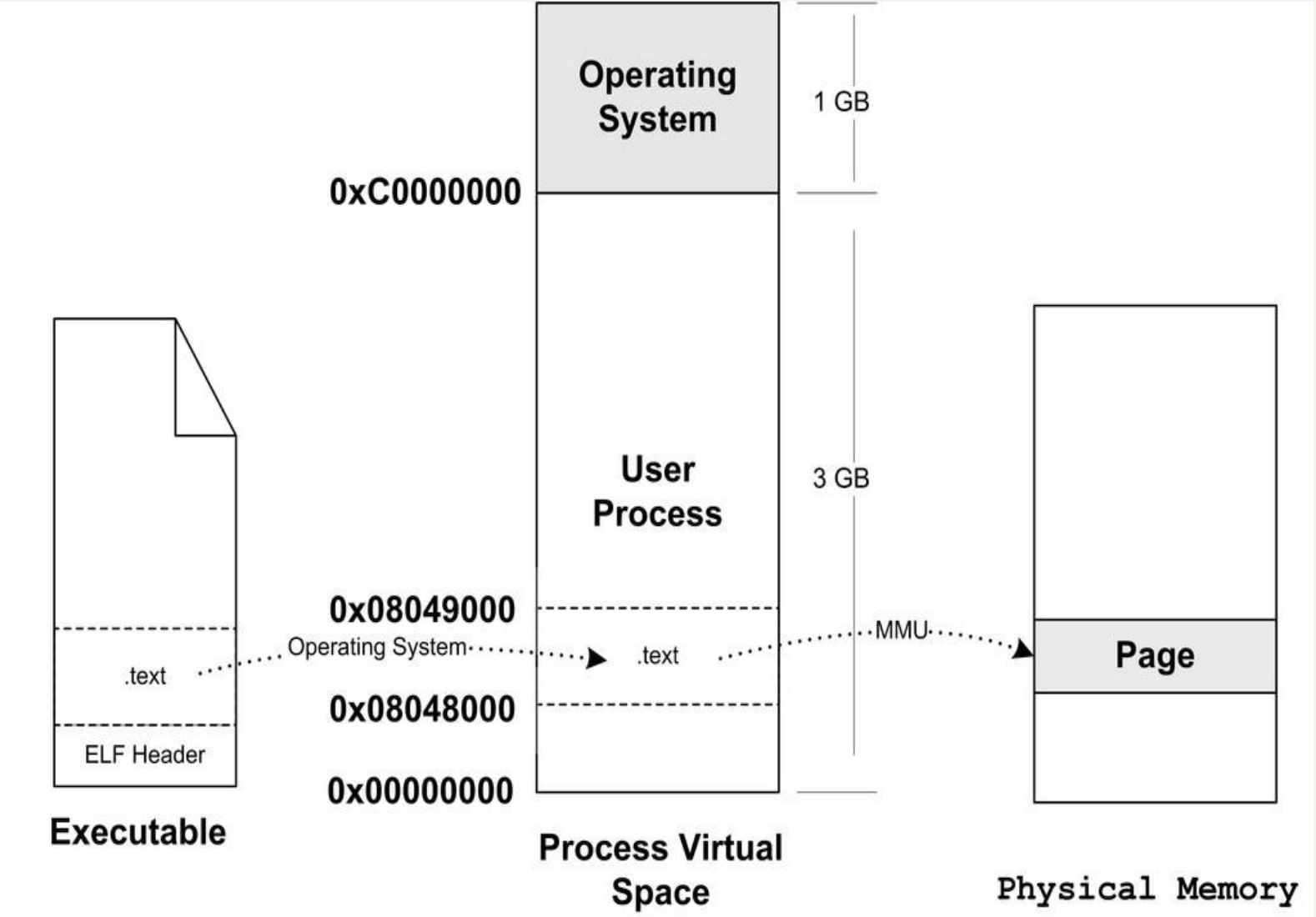
上面的步骤执行完以后,其实可执行文件的真正指令和数据都没有被装入内存中。操作系统只是通过可执行文件头部的信息建立起可执行文件和进程虚拟之间的映射关系而已。
当 CPU 开始打算执行这个地址的指令时,发现是个空页面,于是它就认为这是一个页错误(Page Fault)。
CPU 将控制权交给操作系统,操作系统有专门的页错误处理例程来处理这种情况。操作系统将查询这个数据结构,然后找到空页面所在的 VMA,计算出相应的页面在可执行文件中的偏移,然后在物理内存中分配一个物理页面,将进程中该虚拟页与分配的物理页之间建立映射关系,然后把控制权再还给进程,进程从刚才页错误的位置重新开始执行。
随着进程的执行,页错误会不断的产生,操作系统也会为进程分配相应的物理页面来满足进程执行的需求,如下图所示:
缺页本身是一种中断,与一般的中断一样,需要经过 4 个处理步骤:
1. 保护 CPU 现场。 1. 分析中断原因。 1. 转入缺页中断处理程序进行处理。 1. 恢复 CPU 现场,继续执行。
页面错误会降低系统性能并可能导致抖动,程序或操作系统的性能优化通常涉及减少页面错误的数量。优化的两个主要重点是减少整体内存使用量和改进内存局部性。为了减少页面错误,开发人员必须使用适当的页面替换算法来最大化页面命中率。
进程虚存空间分布
ELF 文件的装载
ELF 文件被映射时,是以系统的页长度作为单位的,那么每个段在映射时的长度应该都是系统页长度的整数倍,如果不是,那么多余部分也将占用一个页。一个 ELF 文件中往往有十几个段,那么内存空间的浪费是可想而知的。而操作系统只关心一些跟装载相关的问题,最主要的是段的权限(可读、可写、可执行):
- 以代码段为代表的权限为可读可执行的段。
- 以数据段和 BSS 段为代表的权限为可读可写的段。
- 以只读数据段为代表的权限为只读的段。
相同权限的段可合井到一起当作一个段进行映射。 比如有两个段分別叫 .text 和 .init,它们包含的分别是程序的可执行代码和初始化代码,并且它们的权限相同,都是可读并且可执行的。假设 .text 为 4097 字节,.init 为 512 字节,这两个段分别映射的话就要占用三个页面,但是如果将它们合并成一起映射的话只须占用两个页面,如下图所示:
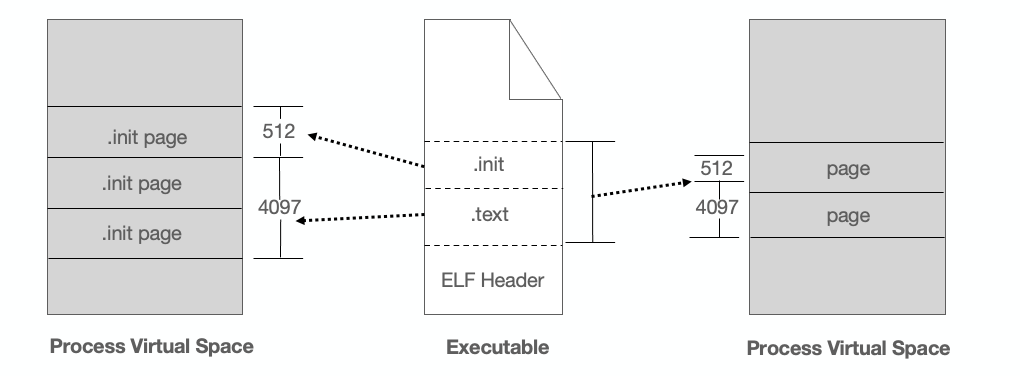
ELF 可执行文件引入了一个概念叫做 Segment,一个 Segment 包含一个或多个 Section,如果将 .text 段和 .init 段合并在一起看作是一个 Segment ,那么装载的时候就可以将它们看作一个整体一起映射,也就是说映射以后在进程虚存空间中只有一个相对应的 VMA,而不是两个,这样做的好处是可以减少页面内部碎片,节省了内存空间。 Segment 的概念实际上是从装载的角度重新划分了 ELF 的各个段。
Segment 和 Section 是从不同的角度来划分同一个 ELF 文件。这个在 ELF 中被称为不同的视图 View:
- 从
Section的角度来看 ELF 文件就是链接视图LinkingView - 从
Segment的角度来看就是执行视图ExecutionView。
当我们在谈到 ELF 装载时,段专门指 Segment,而在其他的情况下,段指的是 Section,ELF 可执行文件与进程虚拟空间映射关系如下图所示:
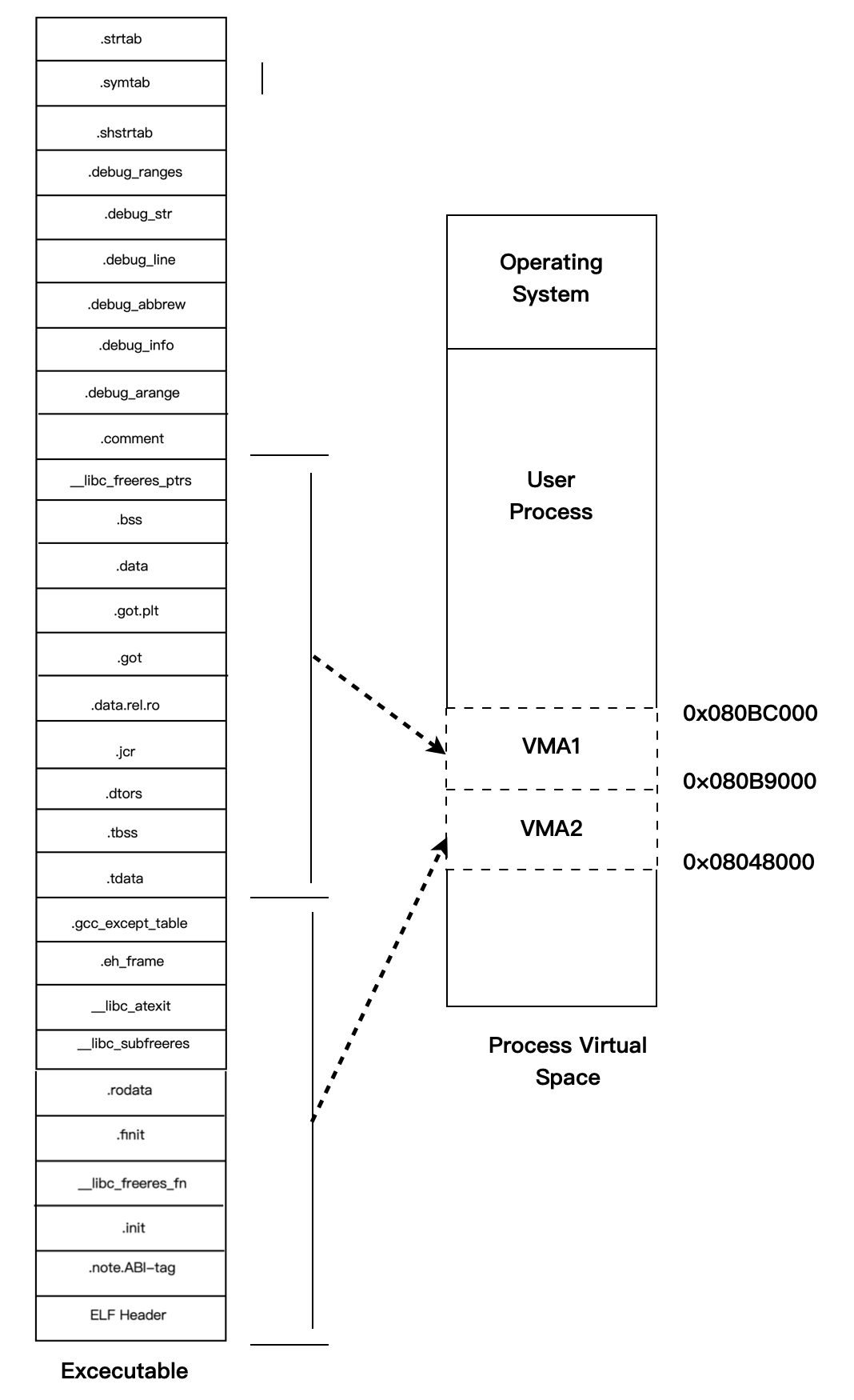
ELF 可执行文件中有一个专门的数据结构叫做程序头表**(Program Header Table)**用来保存 Segment 的信息。因为 ELF 目标文件不需要被装载,所以它没有程序头表,而 ELF 的可执行文件和共享库文件都有。它的结构体以及各个成员的含义如下:
typedef struct {
Elf32_Word p_type; // 类型,基本上我们在这里只关注 LOAD 类型的 Segment
Elf32_Off p_offset; // Segment 在文件中的偏移
Elf32_Addr p_vaddr; // Segment 第一个字节进程虚拟地址空间的起始位置
Elf32_Addr p_paddr; // Segment 的物理装载地址
Elf32_Word p_filesz;// 在 ELF 文件中所占空间的长度
Elf32_Word p_memsz; // Segment 在进程虚拟地址空间中所占用的长度
Elf32_Word p_flags; // Segment 权限属性(可读 R、可写 W、可执行 X)
Elf32_Word p_align; // Segment 对齐属性(2 的 p _align 次方字节)
} Elf32_Phdr
堆和栈
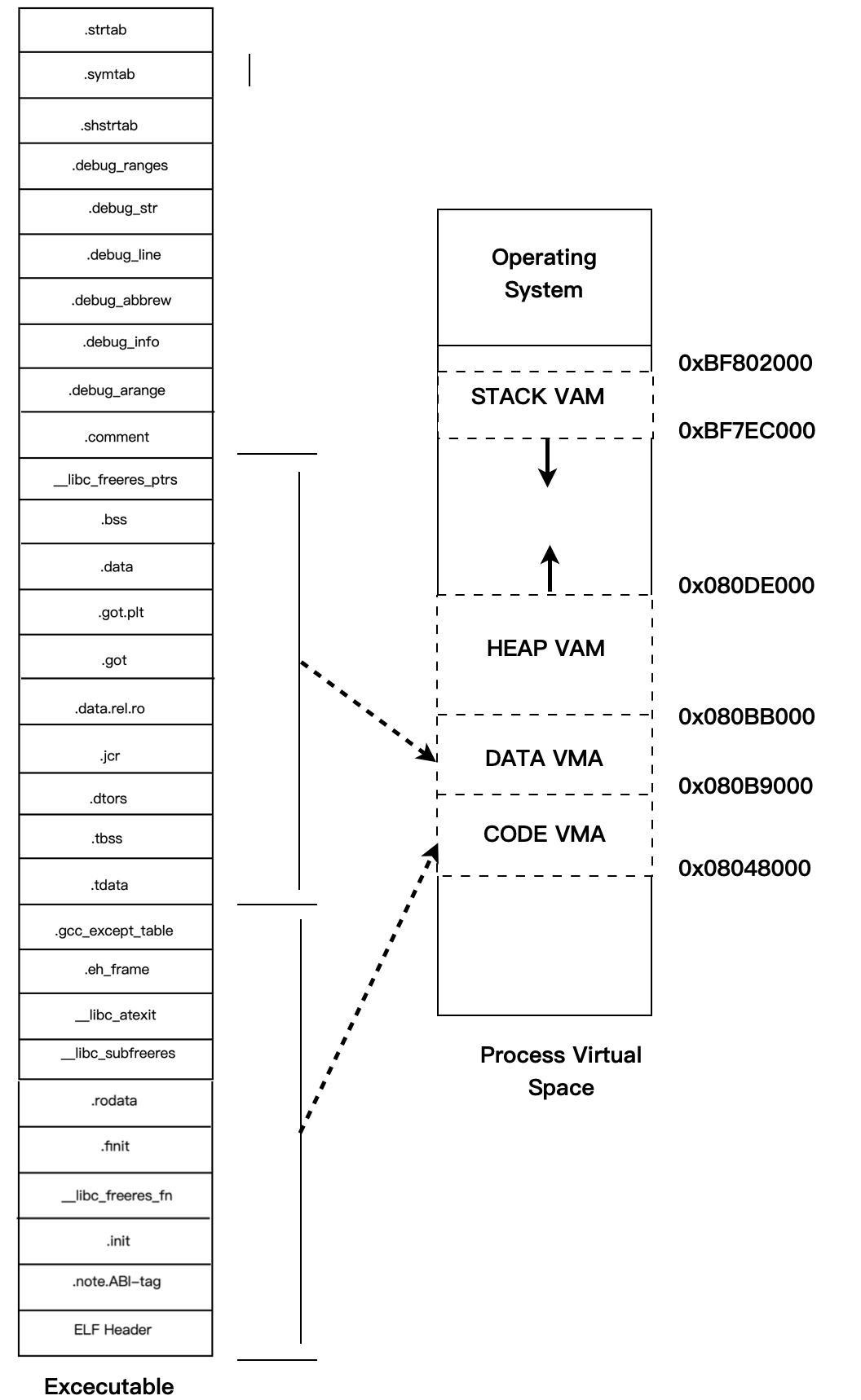
在操作系统里面,VMA 除了被用来映射可执行文件中的各个 Segment ,还使用 VMA 来对进程的地址空间进行管理。我们知道进程在执行的时候它还需要用到堆和栈等空间,事实上它们在进程的虚拟空间中的表现也是以 VMA 的形式存在的,很多情况下,一个进程中的堆和栈分别都有一个对应的 VMA。
Linux 下,我们可以通过查看 /proc 来查看进程的虚拟空间分布:cat /proc/21963/maps
08048000-080b9000 r-xp 00000000 08:01 2801887 ./SectionMapping.elf
080b9000-080bb000 rwxp 00070000 08:01 2801887 ./SectionMapping.elf
080bb000-080de000 rwxp 080bb000 00:00 0 [heap]
bf7ec000-bf802000 rw-p bf7ec000 00:00 0 [stack]
ffffe000-fffff000 r-xp 00000000 00:00 0 [vdso]
- 第一列是 VMA 的地址范围。
- 第二列是 VMA 的权限,
r表示可读,w表示可写,x表示可执行,p表示私有 (COW, Copy on Write) ,s表示共享。 - 第三列是偏移, 表示
VMA对应的Segment在映像文件中的偏移。 - 第四列表示映像文件所在设备的主设备号和次设备号。
- 第五列表示映像文件的节点号。
- 最后一列是映像文件的路径。
操作系统通过给进程空间划分出一个个 VMA 来管理进程的虚拟空间,基本原则是将相同权限属性的、有相同映像文件的映射成一个 VMA,一个进程基本上可以分为如下几种 VMA 区域:
- 代码
VMA,权限只读,可执行,有映像文件。 - 数据
VMA,权限可读写,可执行,有映像文件。 - 堆
VMA,权限可读写,可执行,无映像文件,匿名,可向上扩展。 - 栈
VMA,权限可读写,不可执行,无映像文件,匿名,可向下扩展。
常见进程的虚拟空间如下图所示:
堆的最大的申请数量也就是 malloc 的最大申请数量会受到哪些因素的影响呢?
- 具体的数值会受到操作系统版本,程序本身大小,用到的动态共享库数量、大小,程序栈数量、大小等。
- 有可能每次运行的结果都会不同,因为有些操作系统使用了一种叫做随机地址空间分布的技术 (主要是出于安全考虑, 防止程序受恶意攻击) ,使得进程的堆空间变小。
ASLR
在计算机科学中,地址空间配置随机加载称为 ASLR,又称地址空间配置随机化或地址空间布局随机化,是一种防范内存损坏漏洞被利用的计算机安全技术,通过随机放置进程关键数据区域的地址空间来防止攻击者跳转到内存特定位置来利用函数。
Linux 已在内核版本 2.6.12 中添加 ASLR。
Apple 在 Mac OS X Leopard 10.5 中某些库导入了随机地址偏移,但其实现并没有提供 ASLR 所定义的完整保护能力。而 Mac OS X Lion 10.7 则对所有的应用程序均提供了 ASLR 支持。
Apple 在 iOS 4.3 内导入了 ASLR。
段地址对齐
可执行文件最终是要被操作系统装载运行的,这个装载的过程一般是通过虚拟内存的页映射机制完成的。在映射过程中,页是映射的最小单位。
假设我们有一个 ELF 可执行文件,它有三个段需要装载,我们将它们命名为 SEG0、SEG1 和 SEG2。每个段的长度、在文件中的偏移如表所示:
| 段 | 长度 (字节) | 偏移 (字节) | 权限 |
|---|---|---|---|
| SEG0 | 127 | 34 | 可读可执行 |
| SEG1 | 9899 | 164 | 可读可写 |
| SEG2 | 1988 | 只读 |
这属于大多常见的情况,就是每个段的长度都不是页长度的整数倍,一种最简单的映射办法就是每个段分开映射,对于长度不足一个页的部分则占一个页。通常 ELF 可执行文件的起始虚拟地址为 0x08048000,所以这三个段的虚拟地址和长度如表所示:
| 段 | 起始虚拟地址 | 大小 | 有效字节 | 偏移 | 权限 |
|---|---|---|---|---|---|
| SEG0 | 0x08048000 | 0x1000 | 127 | 34 | 可读可执行 |
| SEG1 | 0x08049000 | 0x3000 | 9899 | 164 | 可读可写 |
| SEG2 | 0x0804C000 | 0x1000 | 1988 | 只读 |
三个段的总长度只有 12014 字节,却占据了 5 个页,即 20480 字节,空间使用率只有 58. 6 %。导致文件段的内部会有很多碎片,浪费磁盘空间。
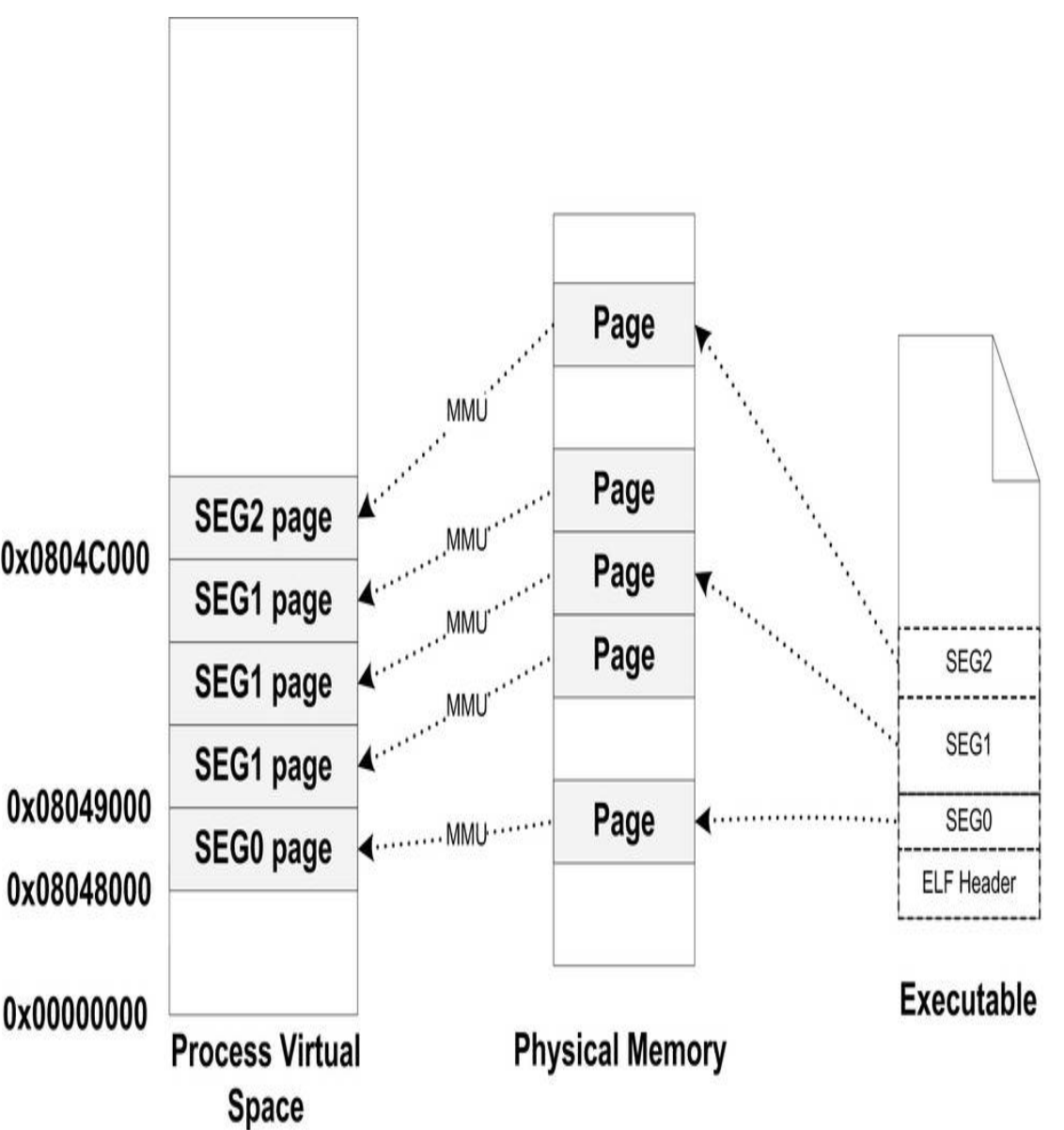
为了解决这种问题,就是让那些各个段接壤部分共享一个物理页面,然后将该物理页面分别映射两次,如下图:
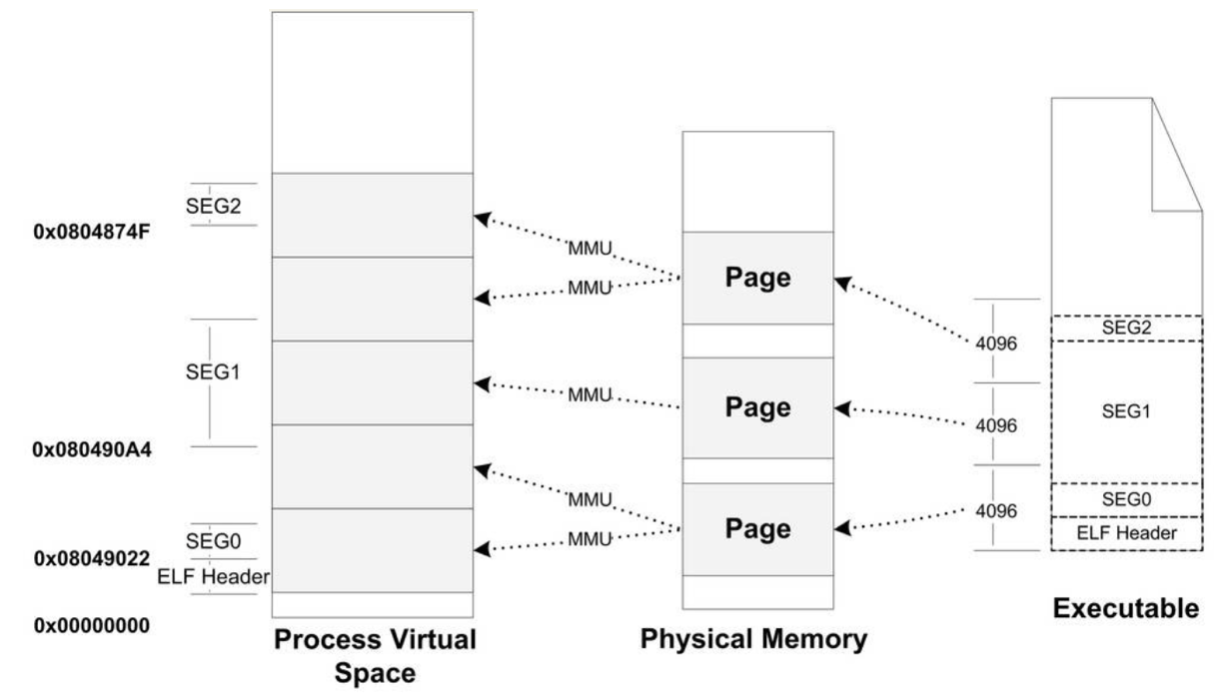
这样映射的话,不仅进程中的某一段区域就是整个ELF 的映像,对于一些须访问 ELF 文件头的操作可以直接通过读写内存地址空间进行,而且内存空间得到了充分的利用,ELF 文件的映射方式如下表所示:
| 段 | 起始虚拟地址 | 大小 | 偏移 | 权限 |
|---|---|---|---|---|
| SEG0 | 0x08048022 | 127 | 34 | 可读可执行 |
| SEG1 | 0x080490A4 | 9899 | 164 | 可读可写 |
| SEG2 | 0x0804C74F | 1988 | 可读可写 |
进程栈初始化
操作系统在进程启动前将系统环境变量和进程的运行参数等提前保存到进程的虚拟空间的栈中,进程启动后,程序的库部分会把堆栈里的初始化信息中的参数信息传递给 main 函数,并通过函数的两个参数 argc 和 argv,传递命令行参数数量和命令行参数字符串指针数组。
Linux 内核装载 ELF 过程简介
首先,用户层面,bash 进程会调用 fork 系统调用创建一个新的进程,然后新的进程调用 execve 系统调用执行指定的 ELF 文件,原先的 bash 进程继续返回等待刚才启动的新进程结束,然后继续等待用户输入命令。
execve 系统调用被定义在 unistd.h,它的原型如下:
int execve(const char *filename,char *const argv[],char *const envp[]);
它的三个参数分别是被执行的程序文件名,执行参数和环境变量,相关函数执行顺序如下:
- 在内核中
execve系统调用相应的入口是sys_execve。 sys_execve进行一些参数的检查复制之后,调用do_execve。do_execve会首先查找被执行的文件,如果找到文件,则读取文件的前 128 个字节,判断文件的格式,每种可执行文件的格式的开头几个字节都是很特殊的,特别是开头 4个字节,常常被称做魔数。- 调用
search_binary_handle通过判断文件头部的魔数确定文件的格式去搜索和匹配合适的可执行文件装载处理过程。 - 调用ELF 可执行文件的装载处理过程
load_elf_binary。 - 当
load_elf_binary执行完毕,返回至do_execve再返回至sys_execve时已经把系统调用的返回地址改成了被装载的 ELF 程序的入口地址了。
load_elf_binary这个函数的代码比较长,它的主要步骤是:
-
检查 ELF 可执行文件格式的有效性,比如魔数,程序头表中段的数量。
-
寻找动态链接的
.interp段,设置动态链接器路径。 -
根据 ELF 可执行文件的程序头表的描述,对 ELF 文件进行映射,比如代码、数据、只读数据。
-
初始化 ELF 进程环境,比如进程启动时
edx寄存器的地址应该是DT_FINI的地址。 -
将系统调用的返回地址修改成 ELF 可执行文件的入口点,这个入口点取决于程序的链接方式,对于静态链接的 ELF 可执行文件,这个程序入口就是 ELF 文件的文件头中
e_entry所指的地址. 对于动态链接的 ELF 可执行文件,程序入口点是动态链接器。
动态链接
静态链接的方式对于计算机内存和磁盘的空间浪费非常严重,作者讲了一个静态链接的例子,Program1 和Program2 分別包含 Program1.o 和 Program2.o 两个模块,并且它们还共用 Lib.o 这个模块,静态链接下,当同时运行 Program1 和Program2 时,Lib.o 在磁盘中和内存中都有两份副本,想象如果是静态链接的库,很多程序共用的情况下,那么将会有大量的内存空间被浪费。除此之外,如果是使用静态链接,假设 Lib.o 修改了一个 bug,那么 Program1 和 Program2 的厂家都需要拿到最新的 Lib.o,然后再与 Program1.o 或者 Program2.o 重新链接后,将最新的程序发布给用户,以至于每个小的改动,都会导致整个程序重新下载。动态链接的出现就是要解决空间浪费和更新困难这两个问题的。
把链接这个过程推迟到了运行时再进行,这就是动态链接的基本思想。工作的原理与静态链接类似,包括符号解析、地址重定位,回到上面的例子,如果改成动态链接,Lib.o 在磁盘和内存中只存在一份,这么做不仅仅减少内存的使用,还可以减少物理页面的换入换出,也可以增加 CPU 缓存的命中率,因为不同进程间的数据和指令访问都集中在了同一个共享的模块上。升级变得更加容易只要简单地将旧的目标文件覆盖掉,而无须将所有的程序再重新链接一遍。
除了上述优点外,动态链接还可以被拿来做插件,为程序增加动态的功能扩展,也可以通过动态链接库给程序和操作系统之间增加了一个中间层,消除程序对不同平台之间依赖的差异性,虽然有很多优点,动态链接也是存在着一些缺点的,例如某个模块更新后,会产生新的模块与旧的模块之间接口不兼容的问题,这个问题也经常被称为 DLL Hell 。
动态链接的例子
/*Program1.c */
#include "Lib.h"
int main() {
foobar(1);
return 0;
}
/*Program2.c*/
#include "Lib.h"
int main() {
foobar(2);
return 0;
}
/*Lib.c*/
#include <stdio.h>
void foobar(int i) {
printf("Printing from Lib.so %d\n",i);
}
/*Lib.h*/
#ifndef LIB_H
#define LIB_H
void foobar(int i);
#endif
两个程序的主要模块 Program1.c 和 Program2.c 分别调用了 Lib.c 里面的 foobar 函数。
使用 GCC 将 Lib.c 编译成一个共享对象文件:gcc - fPIC -shared -o Lib.so Lib.c
两个程序 Program1 和 Program2,这两个程序都使用了 Lib.so 里面的 foobar 函数 。 从 Program1 的 角度看 ,整个编译和链接过程如下图所示:
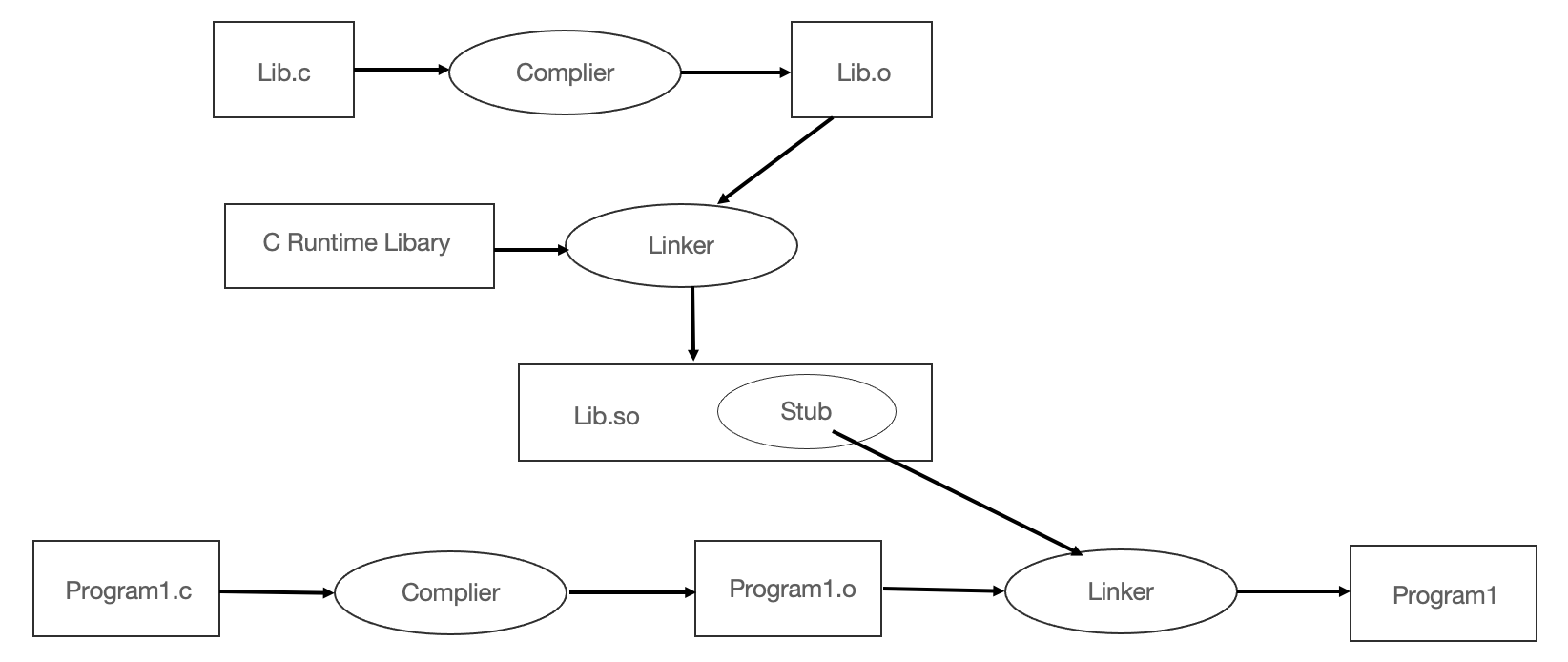
上图的步骤中只有一个步骤与静态链接不一致,那就是 Program1.o 被链接成可执行文件的这一步,在静态链接中,会把 Program1.o 和 Lib.o 链接到一起,并且产生输出可执行文件 Program1,但是这里,Lib.o 没有被链接进来,链接的输入目标文件只有 Program1.o。
当链接器将 Program1.o 链接成可执行文件时,这时候链接器必须确定 Programl.o 中所引用的 foobar 函数的性质。如果 foobar 是一个定义于其他静态目标模块中的函数,那么链接器将会按照静态链接的规则,将 Programl.o 中的 foobar 地址引用重定位,如果 foobar 是一个定义在某个动态共享对象中的函数,那么链接器就会将这个符号的引用标记为一个动态链接的符号,不对它进行地址重定位,把这个过程留到装载时再进行。
动态链接下,程序分为可执行文件和程序依赖的共享对象 Lib.so,Lib.so 中保存了完整的符号信息,通过将 Lib.so 作为链接的输入之一,就能够知道 foobar 的引用是一个静态符号还是一个动态符号。
地址无关代码
共享对象的最终地址在装载时确定,装载器根据当前地址空间的空闲情况,动态分配一块足够大小的虚拟地址空间给相应的共享对象。那么装载地址是怎么获取的呢?在早期,有种做法叫静态共享库(将程序的各种模块统一交给操作系统来管理,操作系统在某个特定的地址划分出一些地址块,为那些已知的模块预留足够的空间)。
这种做法现在已经被淘汰了,之所以被淘汰,主要原因就是升级时,必须保持共享库中全局函数和变量地址的不变,如果应用程序在链接时己经绑定了这些地址,一但更改就必须重新链接应用程序。
为了能够使共享对象在任意地址装载,基本思路是在链接时,对所有绝对地址的引用不作重定位,而把这一步推迟到装载时再完成。假设函数 foobar 相对于代码段的起始地址是 0x100,当模块被装载到 0x10000000 时,我们假设代码段位于模块的最开始,即代码段的装载地址也是 0x10000000,那么我们就可以确定 foobar 的地址为 0x10000100。这时系统遍历模块中的重定位表,把所有对 foobar 的地址引用都重定位至0x10000100,这种装载时重定位义被叫做基址重置 Rebasing。
装载时重定位是解决动态模块中有绝对地址引用的方法之一,但是指令部分无法再多个进程之间共享,就失去了节省内存的优势。我们希望程序模块中共享的指令部分在装载时不需要因为装载地址的改变而改变,所以实现的基本想法就是把指令中那些需要被修改的部分分离出来,跟数据放在一起,这样指令部分就可以保持不变,而数据部分可以在每一个进程中拥有一个副本。这种方案称之为地址无关代码 PIC 技术。
共享对象模块中的地址引用按照是否为跨模块分成两类:
-
模块内部引用。
-
模块外部引用
按照不同的引用方式又可以分成两类:
-
指令引用。
-
数据访问。
于是我们就得到了 4 中情况:
- 第一种是模块内部的函数调用、跳转。
- 第二种是模块内部的数据访问,比如模块中定义的全局变量、静态变量。
- 第三种是模块外部的函数调用、跳转。
- 第四种是模块外部的数据访问,比如其他模块中定义的全局变量。
示例代码如下:
static int a;
extern int b;
extern void ext();
void bar() {
a = 1;
b = 2;
}
void foo() {
bar();
ext();
}
类型一 模块内部调用或跳转
例如上面例子中 foo 对 bar 的调用,属于模块内部的调用,会产生如下代码:
8048344 <bar>:
8048344: 55 push %ebp
....
8048349 <foo>:
8048357: e8 e8 ff ff ff call 8048344<bar>
804835C: ...
对于模块内部调用,因为被调用的函数和调用者在同一个模块,他们之间的相对位置是固定的。模块内部的跳转和函数调用都可以是相对地址调用,或者基于寄存器的相对调用,这些指令是不需要重定位的。
0xFFFFFFE8 是 -24 的补码形式
bar 的地址为 0x804835c + (-24) = 0x8048344
类型二 模块内部数据访问
例如上面例子中 bar 访问内部变量 a,属于模块内部的数据访问,会产生如下代码:
0000044c <bar>:
.....
44f: e8 40 00 00 00 call 494<__i686.get_pc_thunk.cx>
454: 81 c1 8c 11 00 00 add $0x118c,%ecx
45a: c7 81 28 00 00 00 01 movl %0x1,0x28(%ecx)
461: 00 00 00
.....
494: <__i686.get_pc_thunk.cx>:
494: 8b 0c 24 mov (%esp),%ecx
497: c3 ret
一个模块前面一般是若干个页的代码,后面紧跟着若干个页的数据,这些页之间的相对位置是固定的,也就是说,任何一条指令与它需要访问的模块内部数据之间的相对位置是固定的,那么只需要相对于当前指令加上固定的偏移量就可以访问模块内部数据了,现代的体系结构中,数据的相对寻址往往没有相对与当前指令地址 PC 的寻址方式,所以 ELF 用了一个很巧妙的办法来得到当前的 PC 值。
__i686.get_pc_thunk.cx 这个函数的作用就是把返回地址的值放到 ecx 寄存器,即把 call 的下一条指令的地址放到 ecx 寄存器。
变量 a 的地址,是 add 指令地址加上两个偏移量 0x118c 和 0x28,即如果模块被装载到 0x10000000 这个地
址的话,变量 a 的实际地址将是 0x10000000 + 0x454 + 0x118c + 0x28 = 0x10001608
例外: 对于全局变量来说,无论是在模块内部还是模块外部,都只能使用 GOT 的方式来访问,因为编译器无法确定对全局变量的引用是跨模块的还是模块内部的,关于 GOT 下面会介绍。
类型三 模块间数据访问
例如上面例子中 bar 访问内部变量 b,属于模块间的数据访问,会产生如下代码:
0000044c <bar>:
.....
44f: e8 40 00 00 00 call 494 <__i686.get_pc_thunk.cx>
454: 81 c1 8c 11 00 00 add $0x118c,%ecx //%ecx=0x454 + 0x118C,GOT表地址
45a: c7 81 28 00 00 00 01 movl $0x1,0x28(%ecx) //a = 1
461: 00 00 00
464: 8b 81 f8 ff ff ff mov 0xfffffff8(%ecx),%eax
46a: c7 00 02 00 00 00 movl $0x2,(%eax) //b = 2
.....
494: <__i686.get_pc_thunk.cx>:
494: 8b 0c 24 mov (%esp),%ecx
497: c3 ret
ELF 的做法是在数据段里面建立一个指向这些变量的指针数组,也被称为全局偏移表 (Global Offset Table,GOT) ,当代码需要引用该全局变量时,可以通过 GOT 中相对应的项间接引用,基本机制如下图:
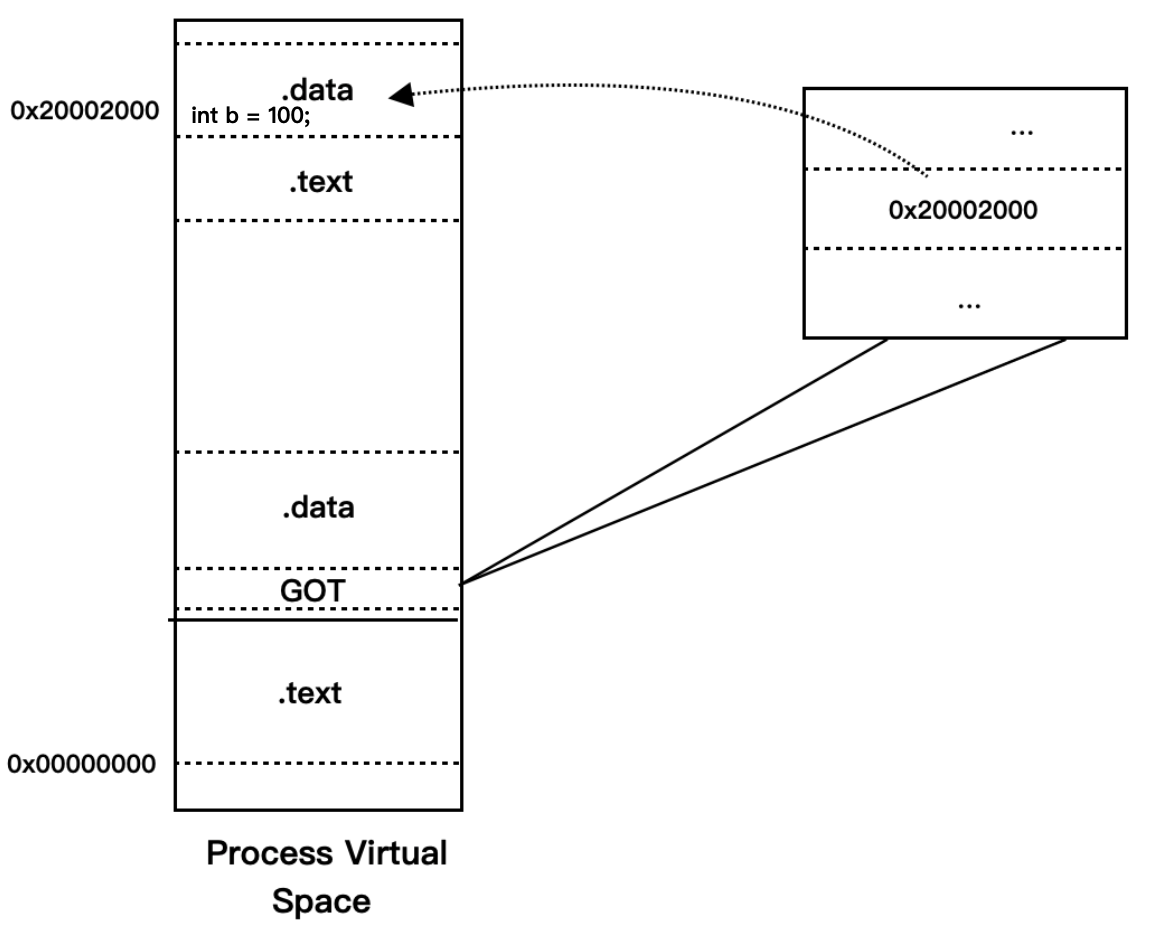
当指令中需要访问变量 b 时,程序会先找到 GOT,然后根据 GOT 中变量所对应的项找到变量的目标地址。每个变量都对应一个 4 个字节的地址,链接器在装载模块的时候会查找每个变量所在的地址,然后填充 GOT 中的各个项,以确保每个指针所指向的地址正确。由于 GOT 本身是放在数据段的,所以它可以在模块装载时被修改,并且每个进程都可以有独立的副本,相互不受影响。
GOT 如何做到指令的地址无关性:
模块在编译时可以确定模块内部变量相对与当前指令的偏移,那么我们也可以在编译时确定 GOT 相对于当前指令的偏移。确定 GOT 的位置跟上面的访问变量 a 的方法基本一样,通过得到 PC 值然后加上一个偏移量,就可以得到 GOT 的位置,然后我们根据变量地址在 GOT 中的偏移就可以得到变量的地址。
我们的程序首先计算出变最 b 的地址在 GOT 中的位置,即 0x10000000 + 0x454 + 0x118c + (-8) = 0x100015d8 ,(0xfffffff8 为 -8 的补码表示,也就是 在 GOT 中偏移 8),然后使用寄存器间接寻址方式给变最 b 赋值 2。
这边解释下寄存器的直接寻址和间接寻址:
寄存器寻址:指令所要的操作数已存储在某寄存器中,或把目标操作数存入寄存器。
寄存器间接寻址:寄存器内存放的是操作数的地址,而不是操作数本身,即操作数是通过寄存器间接得到的。
因为上面我们在 GOT 拿到的是变量 b 在外部模块的地址,所以更改变量 b 的值的过程是通过间接寻址来做的。
类型四 模块间调用、跳转
例如上面例子中 foo 对 ext 的调用 ,属于模块间的函数调用,会产生如下代码:
call 494 <__i686.get_pc_thunk.cx>
add $0x118c,%ecx //%ecx=0x454 + 0x118C,GOT表地址
mov 0xfffffffc(%ecx),%eax
call *(%eax)
.....
494: <__i686.get_pc_thunk.cx>:
494: 8b 0c 24 mov (%esp),%ecx
497: c3 ret
模块需要调用目标函数时,可以通过 GOT 中的项进行间接跳转,调用 ext 函数的方法与上面访问变量 b 的方法基本类似,先得到当前指令地址 PC,然后加上一个偏移得到函数地址在 GOT 中的偏移,然后一个间接调用,如下图:
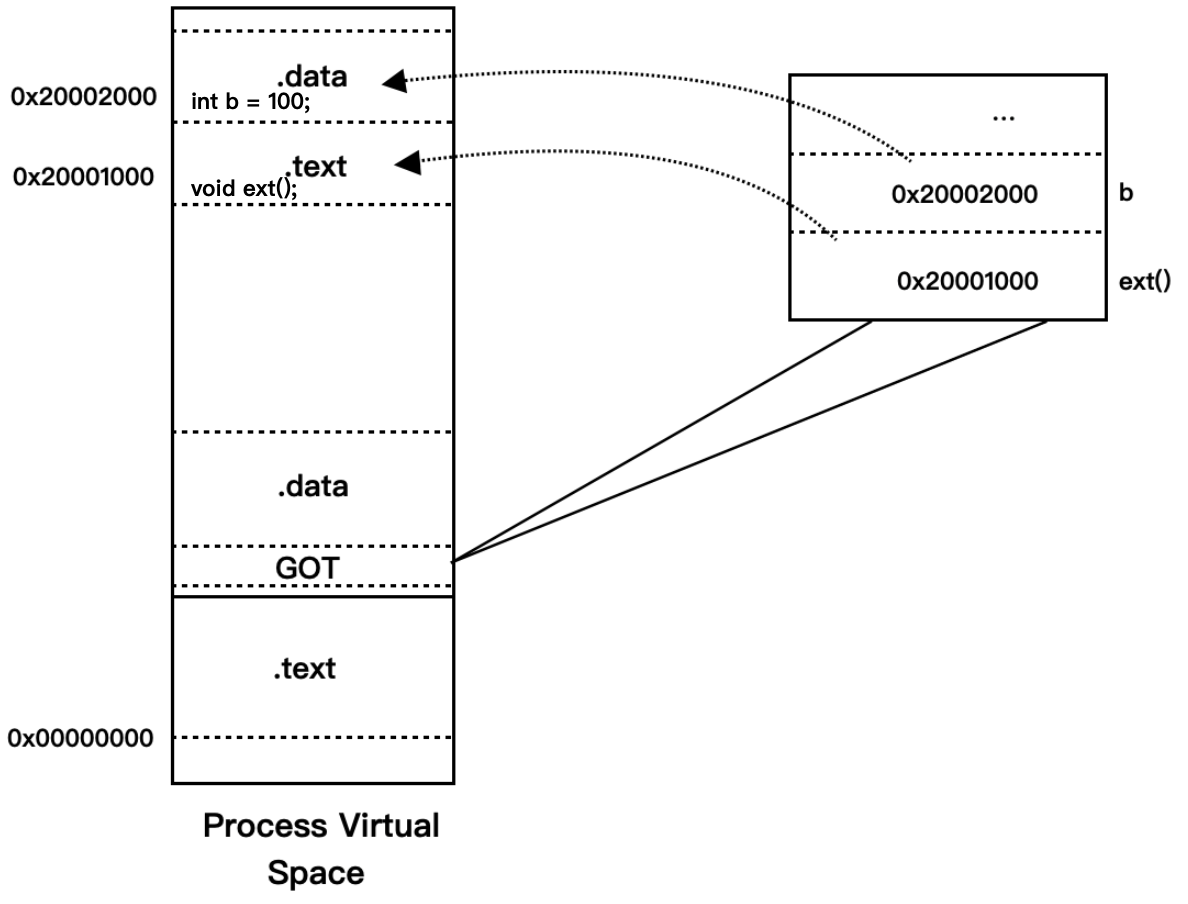
4 种地址引用方式在理论上都实现了地址无关性,总结如下:
| 指令跳转、调用 | 数据访问 | |
|---|---|---|
| 模块内部 | (1)相对跳转和调用 | (2)相对地址访问 |
| 模块外部 | (3)间接跳转和调用(GOT) | (4)直接访问(GOT) |
共享模块的全局变量问题
当一个模块引用了一个定义在共享对象的全局变量的时候,比如一个共享对象定义了一个全局变量 global,下面这块代码我们将它定义在 module.c 中,当编译时它无法根据这个上下文判断 global 是定义在同一个模块的其他目标文件还是定义在另外一个共享对象之中,即无法判断是否为跨模块间的调用。
extern int global;
int foo() {
global = 1;
}
假设 module.c 是程序可执行文件的一部分,由于可执行文件在运行时并不进行代码重定位,所以变量的地址必须在链接过程中确定下来。为了能够使得链接过程正常进行,链接器会在创建可执行文件时,在它的 bss 段创建一个 global 变量的副本,然而由于 global 是定义在共享对象中的,那么这个 global 变量会同时存在于多个位置中,这显然是不行的。
解决的办法那就是所有的使用这个变量的指令都指向位于可执行文件中的那个副本。
-
ELF 共享库在编译时,默认都把定义在模块内部的全局变量当作定义在其他模块的全局变量,通过
GOT来实现变最的访问。 -
当共享模块被装载时,如果某个全局变量在可执行文件中拥有副本,那么动态链接器就会把
GOT中的相应地址指向该副本,这样该变量在运行时实际上最终就只有一个实例。 -
如果变最在共享模块中被初始化,那么动态链接器还需要将该初始化值复制到程序主模块中的变量副本,如果该全局变量在程序主模块中没有副本,那么
GOT中的相应地址就指向模块内部的该变量副本。
假设 module.c 是一个共享对象的一部分,那么 GCC 编译器在 -fPIC 的情况下,就会把对 global 的调用按照跨模块模式产生代码。原因是编译器无法确定对 global 的引用是跨模块的还是模块内部的。即使是模块内部的,还是会产生跨模块代码,因为 global 可能被可执行文件引用,从而使得共享模块中对 global 的引用要执行可执行文件中的 global 副本。
数据段地址无关性
static int a;
static int *p = &a;
如果某个共享对象里面有这样一段代码的话,那么指针 p 的地址就是一个绝对地址,它指向变量 a,而变量 a 的地址会随着共享对象的装载地址改变而改变。对此,我们可以选择装载时重定位的方法来解决数据段中绝对地址引用问题,如果数据段中有绝对地址引用,那么编译器和链接器就会产生一个重定位表,表中包含重定位的入口,当动态链接器装载共享对象时,如果发现该共享对象有这样的重定位入口,那么动态链接器就会对该共享对象进行重定位。
那问题来了,为什么数据段可以采用装载时重定位,而代码段不可以呢?
原因其实很简单,因为对于数据段来说,它在每个进程都有一份独立的副本,所以并不担心被进程改变,而代码段则没有独立的副本,如果让代码段也使用这种装载时重定位的方法,而不使用地址无关代码的话,它就不能被多个进程之间共享,于是也就失去了节省内存的优点。
如果可执行文件是动态链接的,那么 GCC 会使用 PIC 的方法来产生可执行文件的代码段部分,以便于不同的进程能够共享代码段,节省内存。
延迟绑定 PLT
首先我们需要认清一个问题,那就是动态链接比静态链接要慢,还会减慢程序的启动速度,主要原因是:
-
动态链接下对于全局和静态的数据访问都要进行复杂的
GOT定位,然后间接寻址。 -
对于模块间的调用也要先定位
GOT,然后再进行间接跳转。 -
动态链接的链接工作在运行时完成,即程序开始执行时,动态链接器都要进行一次链接工作(动态链接器会寻找并装载所需要的共享对象,然后进行符号查找地址重定位等工作等)。
在一个程序运行过程中,可能很多函数在程序执行完时都不会被用到,如果一开始就把所有函数都链接好实际上是一种浪费。所以 ELF 采用了一种叫做延迟绑定的做法,基本的思想就是当函数第一次被用到时才进行绑定 (符号查找、重定位等),这样可以加快程序的启动速度。ELF 使用 PLT (Procedure Linkage Table) 的方法来实现。
例如 liba.so 需要调用 libc.so 中的 bar 函数,第一次调用时首先会需要调用动态链接器中的某个函数来完成地址绑定工作,这个函数的名字是 _dl_runtime_resolve具体过程如下(解析符号仅执行一次):
bar@plt
jmp *(bar@GOT)
push moduleID
jump _dl_runtime_resolve
- 调用函数并不直接通过
GOT跳转,而是通过一个叫作PLT项的结构来进行跳转,bar两数在PLT中的项的地址我们称之为bar@plt。 bar@plt指令通过GOT进行间接跳转指令,bar@GOT表示GOT中保存bar这个函数相应的项。- 如果链接器初始化阶段并未将
bar的地址填入该项,而是将push n(n 为bar这个符号引用在重定位表.rel.plt中的下标)的地址填入到bar@GOT中。。 - 接着又是一条
push指令将模块的ID压入到堆栈,然后跳转到_dl_runtime_resolve。 _dl_runtime_resolve函数来完成符号解析和重定位工作。_dl_runtime_resolve在进行一系列工作以后将bar的真正地址填入到bar@GOT。bar这个函数被解析完,当我们再次调用bar@plt时,第一条jmp指令就能够跳转到真正的bar函数中。
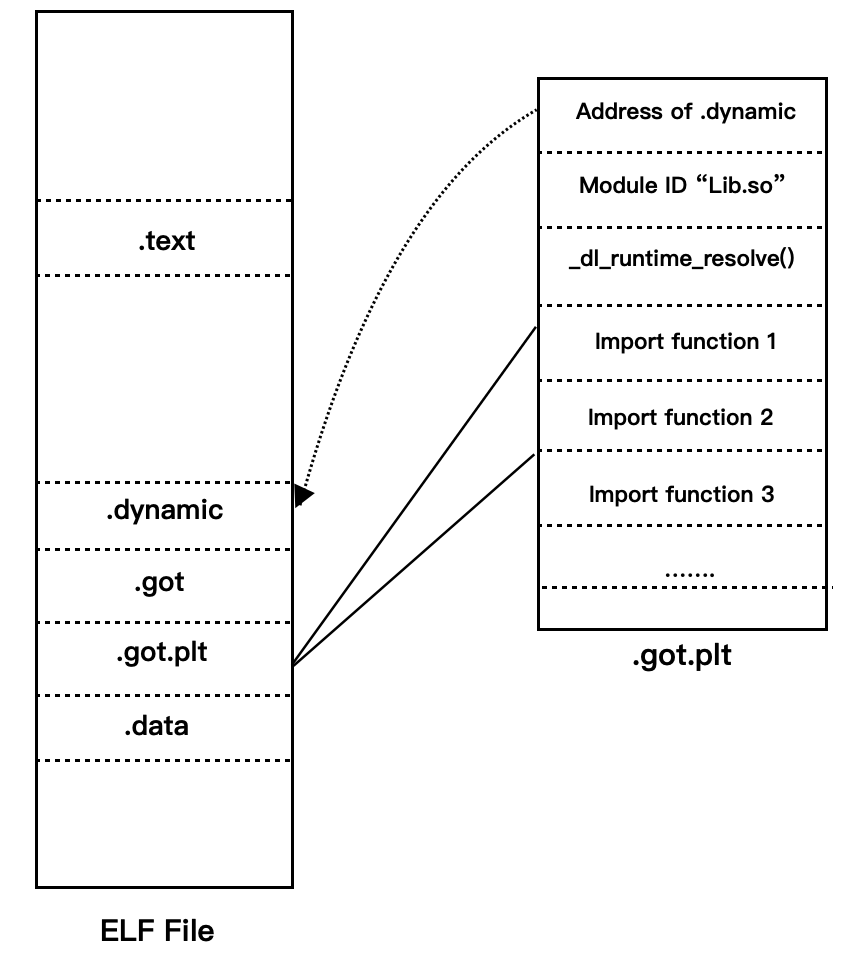
ELF 将 GOT 拆分成了两个表叫做 got 和 got.plt 。其中 got 用来保存全局变量引用的地址,.got.plt 用来保存函数引用的地址,所有对于外部函数的引用全部被分离出来放到了 got.plt 中,got.plt 还有一个特殊的地方是它的前三项:
- 第一项保存的是
.dynamic段的地址,描述了本模块动态链接相关的信息。 - 第二项是本模块的
ID(在动态链接器在装载共享模块的时候初始化)。 - 第三项是保存的
_dl_runtime_resolve的地址(在动态链接器在装载共享模块的时候初始化)。 .got.plt的其余项分别对应每个外部函数的引用,整体结构如下图。
动态链接相关结构
动态链接步骤:
- 在动态链接情况下,操作系统会先加载一个动态链接器(实际上是一个共享对象)。
- 加载完成后就将控制权交给动态链接器的入口地址( 与可执行文件一样,共享对象也有入口地址)。
- 当动态链接器得到控制权之后,它开始执行一系列自身的初始化操作。
- 根据当前的环境参数,开始对可执行文件进行动态链接工作。
- 当所有动态链接工作完成以后,动态链接器会将控制权转交到可执行文件的入口地址,程序开始正式执行。
下面开始介绍一些动态链接中比较重要的段。
.interp 段
动态链接器的位置不是由系统配置指定的,也不是由环境变量决定的,而是由 ELF 可执行文件的 .interp 段指定的。里面保存的就是一个字符串,这个字符串就是可执行文件所需要的动态链接器的路径。
.dynamic 段
.dynamic 段保存了动态链接所需要的基本信息(依赖于哪些共享对象、动态键接符号表的位置、动态链接重定位表的 位置、共享对象初始化代码的地址等)。也是动态链接 ELF 中最重要的结构。.dynamic 段里面保存的信息有点像 ELF 文件头,只是我们前面看到的 ELF 文件头中保存的是静态链接时相关的内容,比如静态链接时用到的符号表、重定位表等,这里换成了动态链接下所使用的相应信息,具体结构如下:
typedef struct {
Elf32_Sword d_tag;
union {
Elf32_Word d_val;
Elf32_Addr d_ptr;
} d_un;
} Elf32_Dyn;
我们这里列举几个比较常见的类型值,如下表:
| d_tag 类型 | d_un 的含义 |
|---|---|
| DT_SYMTAB | 动态链接符号表的地址,d_ptr 表示 .dynsym 的地址 |
| DT_STRTAB | 动态链接字符串表地址,d_ptr 表示 .dynstr 的地址 |
| DT_STRSZ | 动态链接字符串表大小,d_val 表示大小 |
| DT_HASH | 动态链接哈希表地址,d_ptr 表示 .hash 的地址 |
| DT_SONAME | 本共享对象的 SO_NAME |
| DT_RPATH | 动态链接共享对象搜索路径 |
| DT_INIT | 初始化代码地址 |
| DT_FINIT | 结束代码地址 |
| DT_NEED | 依赖的共享对象文件,d_ptr 表示所依赖的共享对象文件名 |
| DT_REL | 动态链接重定位表地址 |
| DT_RELA | 动态链接重定位表地址 |
| DT_RELENT | 动态重读位表入口数量 |
| DT_RELAENT | 动态重读位表入口数量 |
动态符号表
ELF 为了表示动态链接的模块之间的符号导入导出关系,使用了 .dynsym 段,也称为动态符号表,用来保存这些符号的信息,动态符号表也需要一些辅助的表,比如用于保存符号名的字符串表 .dynstr,为了加快符号的查找过程,往往还有辅助的符号哈希表 .hash。
动态链接重定位相关结构
对于动态链接来说,共享对象不是以 PIC 模式编译的,那么它需要在装载时被重定位的。
共享对象是以 PIC 模式编译的,也需要重定位,因为数据段还包含了绝对地址的引用。
| 装载时的重定位和静态链接中的重定位区别 | 时机不同 | 重定位表 |
|---|---|---|
| 共享对象的重定位 | 装载时 | .rel.text 和 .rel.data |
| 静态链接的目标文件的重定位 | 链接时 | .rel.dyn 和 .rel.plt |
.rel.dyn 实际上是对数据引用的修正,它所修正的位置位于 .got 以及数据段,而 .rel.plt 是对函数引用的修正,它所修正的位置位于 .got.plt
.got.plt 的前三项是被系统占据的,从第四项开始才是真正存放函数地址的地方。
而第四项刚好是 0x000015c8 + 4* 3 = 0x000015d4 即 __gmon_start__,第五项是 printf,第六项是 sleep,第七项是 __cxa_finalize,结构如下图所示:
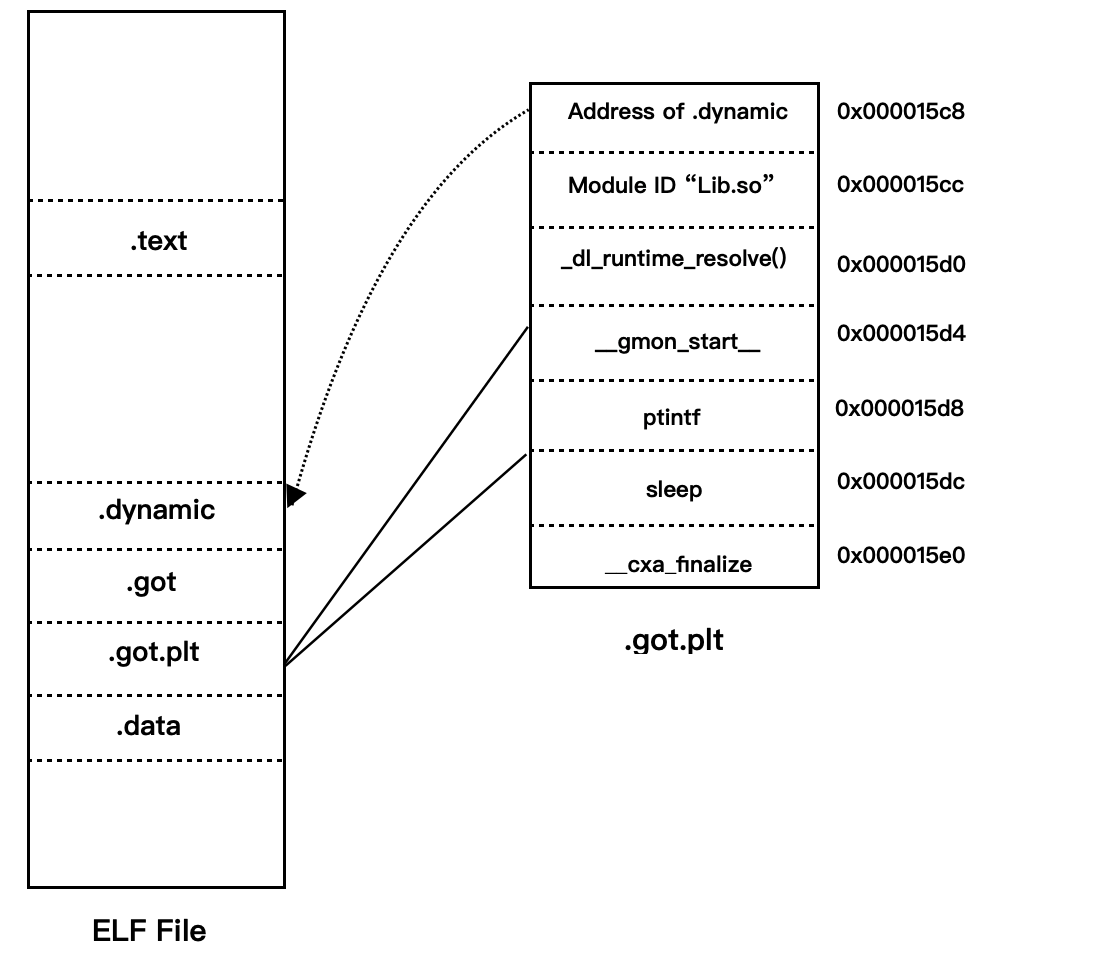
当动态链接器需要进行重定位时 ,它先查找 printf 的地址,printf 位于 libc-2.6.1.so。 假设链接器在全局符号表里面找到 printf 的地址为 0x08801234,那么链接器就会将这个地址填入到 .got.plt 中的偏移为0x000015d8 的位置中去,从而实现了地址的重定位,即实现了动态链接最关键的一个步骤。
稍微麻烦点的是,共享对象的数据段是没有办法做到地址无关的,它可能会包含绝对地址的用,对于这种绝对地址的引用,我们必须在装载时将其重定位。
例如上面的这段代码
static int a;
static int *p = &a;
在编译时, 共享对象的地址是从 0 开始的,我们假设该静态变量 a 相对于起始地址 0 的偏移为 B,即 p 的值为 B。一旦共享对象被装载到地址 A,那么实际上该变量 a 的地址为 A+B。
| ELF 文件的编译方式 | 外部函数的重定位入口的位置 |
|---|---|
| PIC 方式 | .rel.plt |
| 共享对象方式 | .rel.dyn |
动态链接时进程堆栈初始化信息
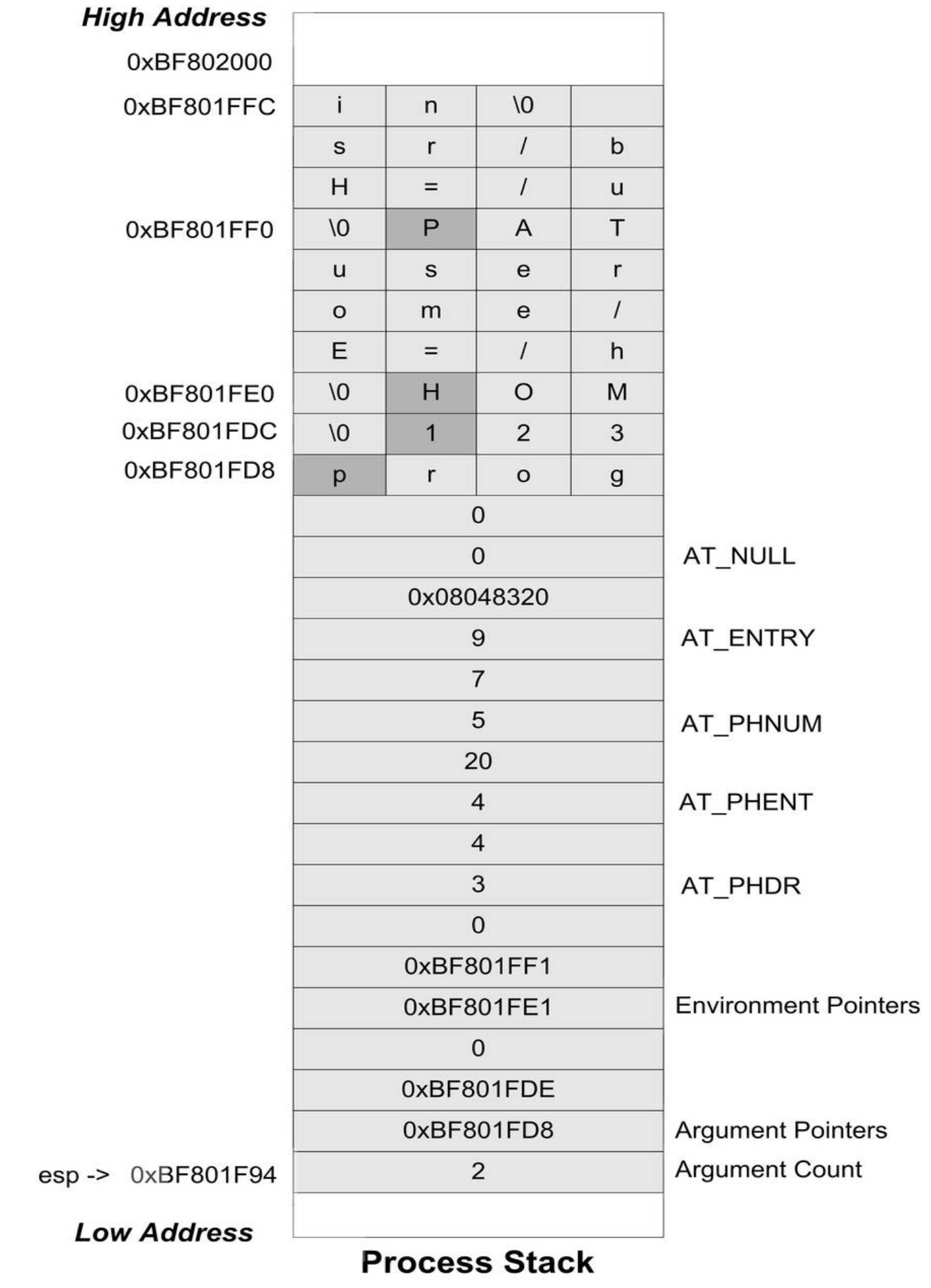
操作系统通过进程的堆栈传递给动态链接器可执行文件和本进程的一些信息,堆栈里面保存了关于进程执行环境和命令行参数等信息。事实上,堆栈里面还保存了动态链接器所需要的一些辅助信息数组。
typedef struct {
uint32_t a_type;
union
{
uint_32_t a_val;
} a_un;
} Elf32_auxv_t;
结构与前面的 .dynamic 段里面的结构如出一辙,32 位的类型值,常见的类型如下:
| a_type 定义 | a_type 值 | a_val 的含义 |
|---|---|---|
| AT_NULL | 0 | 表示辅助信息数组结束 |
| AT_EXEFD | 2 | 表示可执行文件的句柄 |
| AT_PHDR | 3 | 可执行文件中程序头表 |
| AT_PHENT | 4 | 可执行文件中程序头表中每一个入口(Entry)的大小 |
| AT_PHNUM | 5 | 可执行文件中程序头表中入口(Entry)的数量 |
| AT_BASE | 7 | 表示动态链接器本身的装载地址 |
| AT_ENTRY | 9 | 可执行文件入口地址,即启动地址 |
它们在进程堆栈位于环境变量指针的后面:
动态链接的步骤和实现
动态链接的步骤基本上分为 3 步:
- 启动动态链接器本身。
- 装载所有需要的共享对象。
- 重定位和初始化。
Bootstrap
动态链接器本身不可以依赖于其他任何共享对象,其次是动态链接器本身所需要的全局和静态变量的重定位工作由它本身完成。这种具有一定限制条件的启动代码往往被称为自举 (Bootstrap)。
动态链接器入口地址即自举代码的入口,自举代码首先会找到他自己的 GOT。而 GOT 的第一个入口是 .dynamic 段的偏移地址,通过 .dynamic 中的信息,自举代码便可以获得动态链接器本身的重定位表和符号表等,从而得到动态链接器本身的重定位入口,先将它们全部重定位。从这一步开始动态链接器代码才可以使用自己的全局变量和静态变量。动态链接器实际上使用 PIC 模式编译的共享对象,对于模块内部的函数调用也是采用跟模块外部函数调用一样的方式,即使用 GOT/PLT 的方式,所以在 GOT/PLT 没有被重定位之前,自举代码不可以使用任何全局变量,也不可以调用函数。
装载共享对象
完成自举后,动态链接器将可执行文件和链接器本身的符号都合并到全局符号表,然后链接器通过 .dynamic 段找到可执行文件依赖的所有共享对象,并将这些对象放入一个装载集合中,然后把这些对象映射到进程中,如果这些共享对象还依赖其他共享对象,那么将所依赖的共T享对放到装载集合中。如此反复,直到所有依赖的共享对象都被装载进来。装载时符号的优先级是按照加入全局符号表的先后来排序的,当一个符号需要被加入全局符号表时,如果相同的符号名己经存在,则后加入的符号被忽路。
**小 Tip: **为了提高模块内部函数调用的效率,可使用 static 定义函数编译单元私有函数,就可以使用模块内部调用指令,可以加快函数的调用速度,前提是编译器要确保函数不被其他模块覆盖。
重定位和初始化
当上面的步骤完成之后,链接器开始重新遍历可执行文件和每个共享对象的重定位表, 将它们的 GOT/PLT 中的每个需要重定位的位置进行修正。因为此时动态链接器己经拥有了进程的全局符号表。重定位完成后如果某个共享对象有 .init 段,那么动态链接器会执行 .init 段中的代码,用以实现动态共享对象特有的初始化过程,相应地,共享对象中还可能有 .finit 段, 当进程退出时会执行 .finit 段中的代码。
Linux动态链接器实现
对于静态链接的可执行文件来说,程序的入口就是 ELF 文件头里面的 e_entry 指定的入口。
对于动态链接的可执行文件来说,内核会分析它的动态链接器地址,将动态链接器映射至进程地址空间,然后把控制权交给动态链接器。
关于动态链接器有个值得思考的问题:
-
动态链接器本身是动态链接的还是静态链接的? 动态链接器本身应该是静态链接的,它不能依赖于其他共享对象。
-
动态链接器本身必须是
PIC的吗? 动态链接器可以是PIC的也可以不是,但往往使用PIC会更加简单一些。原因如下:
-
不是
PIC的动态链接器,代码段无法共享,浪费内存。 -
不是
PIC的动态链接器本身初始化会更加复杂,因为自举时还需要对代码段进行重定位 。
- 动态链接器可以被当作可执行文件运行,那么的装载地址应该是多少? 动态链接器作为一个共享库,内核在装载它时会为其选择一个合适的装载地址。
显式运行时链接(运行时加载)
一般支持动态链接的系统,都支持程序的运行时加载,也就是让程序自己在运行时控制加载指定的模块,并且可以在不需要该模块时将其卸载。满足运行时装载的共享对象往往被叫做动态装载库。
动态装载库的好处如下:
- 使得程序的模块组织变得很灵活,可以用来实现一些诸如插件、驱动等功能。
- 不需要从一开始就将他们全部装载进来,从而减少了程序启动时间和内存使用。
- 可以在运行的时候重新加载某个模块,程序本身不必重新启动就可以实现模块的增加、删除、更新等, 这对于很多需要长期运行的程序来说是很大的优势。
动态库和一般的共享对象主要区别是:
共享对象是由动态链接器在程序启动之前负责装载和链接的,这一系列步骤都由动态链接器自动完成,对于程序本身是透明的。
动态库的装载则是通过一系列由动态链接器提供的 API: dlopen、dlsym、 dlerror 、dlclose 进行操作。
dlopen
这个函数用来打开一个动态库,并将其加载到进程的地址空间,完成初始化过程。函数的原型如下:
void * dlopen(const char *filename, int flag);
第一个参数 filename 是动态库的路径,路径可能是绝对路径也可能是相对路径,不同的路径存在不同的加载顺序。
如果将 filename 设置为 0 的话,dlopen 返回的是全局符号表的句柄,也就是说我们可以在运行时找到全局符号表里面的任何一个符号,并且可以执行它们。
第二个参数 flag 表示函数符号的解析方式,可以是 PLT 方式(也就是延迟绑定的机制),也可以是加载时即完 成所有的函数的绑定工作,两种方式必须二选其一。
函数的返回值是被加载的模块的句柄,这个向柄在 dlsym 或者 dlclose 时需要用到。
此外 dlopen 中还会执行模块中初始化部分的代码。
dlsym
这个函数是运行时装载的核心部分,我们可以通过这个函数找到所需要的符号。函数的原型如下:
void * dlsym(void *handle, char *symbol);
第一个参数是由 dlopen 返回的动态库的句柄
第二个参数即所要查找的符号的名字
如果 dlsym 找到了相应的符号,则返回该符号的值,没有找到相应的符号则返回 NULL。
符号的优先级
是当多个同名符号冲突时,先装入的符号优先,我们把这种优先级方式称为装载序列,由动态链接器装入和由 dlopen 装入的共享对象,动态链接器在进行符号的解析以及重定位时,都是采用装载序列,然而使用 dlsym 进行查找时,优先级却分两种类型:
- 如果我们是在全局符号表中进行符号查找,那么由于全局符号表使用的是装载序列,所以
dlsym使用的也是装载序列。 - 如果我们是对某个通过
dlopen打开的共享对象进行符号查找的话,那么采用的是一种叫做依赖序列的优先级。它是以被dlopen打开的那个共享对象为根节点,对它所有依赖的共享对象进行广度优先遍历,直到找到符号为止。
dlerror
监听 dlopen dlsym dlclose 是否成功执行,如果返回 NULL,则表示上一次调用成功,如果不是则返回相应的错误消息。
dlclose
函数作用与 dlopen 相反,系统对于已经加载的模块会存在一个计数,当计数为 0 时,会对模块进行卸载,之后执行模块的 .finit 段的代码,然后将相应的符号从符号表中去除,取消进程空间跟模块的映射关系,然后关闭模块文件。
dyld
关于 dyld (The dynamic link editor) 网上介绍的博客非常多,这里简单提一下,感兴趣的可以看下源码。
它是 Apple 的动态链接器, Mach-O 可执行文件会交由 dyld 负责链接 ,装载。目前发展了好几个版本:
dyld 1.01996–2004)dyld 2.0(2004–2007)dyld 2.x(2007–2017)dyld 3.0(2017)dyld 4.0(2022)
下面是针对内参中介绍 dyld 各个版本的简单整理,从版本的差异中,也能看出苹果对于动态链接的过程的一个优化历程。
-
是在大多数系统使用大型
C++动态库之前编写的,导致动态链接器必须做很多工作,而且速度非常慢。 -
首先
dyld 1.0使用了预绑定的技术 -
预绑定是一种技术,我们试图为系统和应用程序中的每个
dylib找到固定地址。 -
动态加载器会尝试加载这些地址的所有内容,如果它成功了,它会编辑所有这些二进制文件,让这些预先计算的地址在里面。
-
然后下一次当它把它们放到相同的地址时,它不需要做任何额外的工作。
dyld 2.0 是对 dyld 1.0 的完全重写
- 稍微扩展了
Mach-o格式并更新了dyld以便我们可以获得高效的C++库支持。 - 它还具有完整的
dlopen和dlsym实现以及正确的语义。 - 2.0 存在一些安全问题,因为它是为速度而设计的,所以它的健全性检查有限。
- 由于启动速度的提升,因此减少了预绑定的工作量。
dyld 2.x 做了很多显著的改进,在程序进程内执行。
-
添加了大量的架构和平台。
-
增加安全性
codeSigning代码签名。- 增加了
ASLR机制。 - 对
Mach-o标头中的许多内容添加了边界检查,这样就无法对格式错误的二进制文件执行某些类型的附加操作。
-
摆脱预绑定并用称为共享缓存(share cache)的东西取而代之,合并了大部分系统动态库,并进行了优化:
- 重新排列二进制文件以提高加载速度。
- 预链接动态库。
- 预构建
dyld和ObjC使用的数据结构。
dyld 3 出 3.0 版本主要是为了性能、可测试性、安全等方面考虑的。
- 将大部分
dyld移出进程,增加了可测试性;留在进程中的dyld位尽可能小,从而减少应用程序中的攻击面。移出进程的方式通过:- 确定安全敏感组件。
- 确定它的昂贵部分,它们是可缓存的,这些是符号查找。
- 大多数启动使用缓存,永远不必调用进程外的
Mach-o解析器或编译器,而是简单地验证它们,增加启动速度,缓存步骤:- 进程外的
Mach-o解析器,解析所有搜索路径、所有@rpaths、所有可能影响您的启动的环境变量,解析Mach-o二进制文件,执行所有这些符号查找,用结果创建闭包。 - 进程内引擎,它验证启动闭包是正确的,然后它只是映射到
dylibs,并跳转到main。 - 启动关闭缓存,系统应用程序关闭我们只是直接构建到共享缓存。
- 进程外的
dyld 4 目标是通过保持相同的 Mach-o 解析器来改进 dyld3,支持不需要预构建闭包的即时加载,也就是 Prebuilt + JustInTime 的双解析模式。
- 新的抽象基类
Loader,为进程中加载的每个Mach-o文件实例化一个Loader对象,Loader有两个具体的子类PrebuiltLoader和JustInTimeLoader。PrebuiltLoader只读的。它包含有关其Mach-o文件的预先计算的信息,包括其路径、验证信息、其依赖的dylib和一组预先计算的绑定目标。在启动时,dyld会为程序寻找预构建的PrebuiltLoader,验证完有效,则使用它。- 如果没有有效的
PrebuiltLoader,那么创建并使用新的JustInTimeLoader,JustInTimeLoader然后通过解析Mach-o找到它的依赖项,进行实时的解析。
总结
- 程序可通过覆盖装入和页映射的两种模式,被操作系统装载到内存中运行,目前几乎所有的主流操作系统都是按页映射的方式装载可执行文件的,页映射的时候,段地址对齐处理不当会造成空间的浪费。
- 进程建立,首先创建一个独立的虚拟地址空间,然后建立起可执行文件和进程虚存之间的映射结构,设置可执行文件的入口,执行程序。随着程序的执行,会不断的产生页错误,操作系统会通过映射结构为进程分配相应的物理页面来满足进程执行的需求。
- 在 ELF 文件中使用
Program Header Table保存Segment的信息,操作系统使用VMA来映射可执行文件中的各个Segment,另外堆和栈等空间也是以VMA的形式存在的,除此之外还有称为vdso的VMA可与系统内核进行通信。 - Linux 内核装载 ELF 时,首先会检查 ELF 可执行文件格式的有效性,再者设置动态链接器路径,对 ELF 文件进行映射,再初始化 ELF 进程环境,最后系统调用的返回地址修改成 ELF 可执行文件的入口。
- 由于静态链接对于计算机内存和磁盘的空间浪费非常严重,于是开始使用动态链接,把链接这个过程推迟到了运行时再进行,这就是动态链接的基本思想。
- 共享对象模块的访问根据模块所属内部或外部,指令调用或数据访问,一共分成了四种地址引用情况,针对这四种情况,都可实现了地址无关性,访问全局变量默认使用
GOT的方式,数据段的绝对地址引用,装载时进行重定位,此外 ELF 还会使用PLT延迟绑定的方式,也就是一次被用到时才进行绑定。 - 动态链接中存在一些比较重要的段,
.interp段,.dynamic段,动态符号表,以及一些动态链接重定位相关结构,除此之外操作系统通过进程的堆栈传递给动态链接器可执行文件和本进程的一些信息。 - 动态链接的步骤基本上分为 3 步,启动动态链接器本身,装载所有需要的共享对象,重定位和初始化。
- 满足运行时装载的共享对象往往被叫做动态装载库,它的装载是通过一系列由动态链接器提供的 API:
dlopen、dlsym、dlerror、dlclose进行操作。 dyld是 Apple 的动态链接器,Mach-O可执行文件会交由dyld负责链接 ,装载。已经从 1.0 版本发展到了 4.0 版本。