
本周趋势
Agent 自主性正在从“放权”走向“治理”。 Cursor Auto-review 不再把权限做成简单开关,而是用 classifier agent 在执行前判断风险;Claude Code 也把权限规则细化到工具参数级别。社区正在意识到,真正可用的 Agent 不是一路绿灯跑到底,而是能在低风险动作上保持速度、在关键边界前主动减速。
上下文、环境和成本成为 Agent 工程的新基础设施。 这周的案例从本地离线 coding agent、上下文退化的“smart zone / dumb zone”,到一个云端 Agent 扫描网络刷出 6531 美元账单,都指向同一件事:模型能力提升之后,系统能否长期稳定运行,取决于环境复现、上下文预算、权限边界和费用护栏这些看起来不那么“智能”的部分。
前沿模型供应链开始暴露非技术风险。 Anthropic 因美国政府指令暂停 Fable 5 / Mythos 5 访问,引发开发者对单一模型依赖的重新评估;GLM-5.2 借势强调开放权重;Rio-3.5-Open 又被指只是别人的模型与 Qwen 做线性 merge。模型选型不再只是性能、价格和上下文长度,可信来源、可迁移性和供应链韧性也进入同一张表。
产品与模型动态
Claude Code
v2.1.174 至 v2.1.181:权限治理、嵌套配置和远程使用体验继续补强。
- 新增
/config key=value,可以在交互、-p和 Remote Control 中直接改设置;macOS sandbox 增加sandbox.allowAppleEvents选项,让受限命令在明确授权后发送 Apple Events。 - 权限规则支持
Tool(param:value)语法,可按工具输入参数匹配,例如阻止特定模型的 subagent;嵌套.claude/skills、agent、workflow 和 output-style 会优先使用离当前工作目录最近的定义。 - 管理端
availableModels约束更严格,默认模型不能再绕过 allowlist;Bedrock 凭证缓存改为遵循真实过期时间,减少固定 1 小时缓存带来的身份问题。 - 修复中途断连时丢失部分响应、WSL2 鼠标滚轮、Linux sandbox 大目录 glob 让 Bash 工具描述膨胀等问题;长段落流式输出也改为按行出现,读感更稳定。
Codex
0.140.0 与 0.141.0:远程执行链路、插件 MCP 和跨平台路径继续收紧。
- 0.141.0 让远程 executor 使用经过认证的端到端加密 Noise relay channel,远程执行从“能跑”继续向“可被信任地跑”推进。
- 跨平台远程执行会保留 executor 原生工作目录和 shell,文件系统权限路径在 app-server 与 exec-server 边界之间传递更准确,减少 Windows、macOS、Linux 混用时的路径错配。
- 被选中的 executor 插件可以按线程激活自己的 stdio MCP server;插件发现也增加 “created by me” marketplace 和按认证需求划分的 curated catalogs。
- 0.140.0 延续了多 Agent、插件加载、远程安装鉴权和工作区插件识别方面的修复,并移除了实验性的
/realtime语音控制和相关音频依赖,让 CLI 更聚焦代码执行链路。
其他工具与模型
Anthropic 暂停 Fable 5 / Mythos 5 访问。

Anthropic 在官方声明中表示,美国政府以国家安全为由要求暂停 Fable 5 和 Mythos 5 的访问,其他模型不受影响。公司反对仅凭一个狭窄 jailbreak 就召回商业模型,并强调行业内不存在绝对不可破解的模型。无论事件后续如何,这都让开发者第一次非常直观地看到:前沿模型可用性可能被政策、合规和安全争议突然切断。
GLM-5.2 正式发布
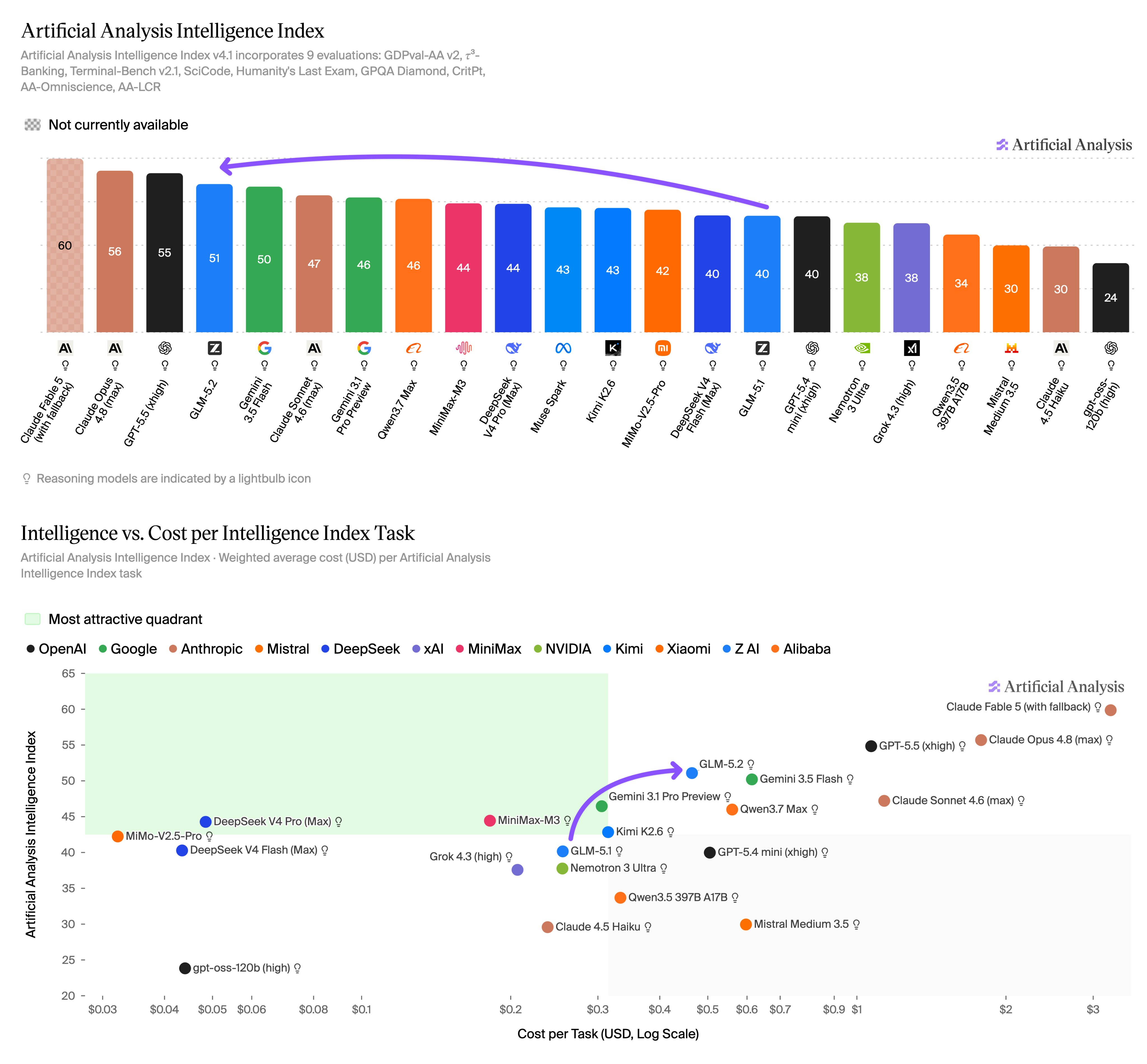
Z.ai 发布 GLM-5.2,强调 744B-A40B MoE、1M 上下文和 MIT 协议开放权重。它的发布语境比参数本身更重要:在闭源前沿模型访问受限的同一周,开放权重被重新包装成一种工程韧性。对企业来说,这类模型未必马上替代最强闭源模型,但它确实提供了一个对冲选项:当 API、地区或合规策略变化时,至少还有可迁移、可自托管的备选路径。
各项评测指标看 GLM 5.2 排行也很高,基本相当于 Claude Opus 4.8 的能力,这也推动 GLM 股价强势上涨。想要体验的人非常多,但很多都卡在 GLM 会员抢购这一步,想用用不上。
Anthropic 展示 Claude 在化学 NMR 任务上的能力。
Anthropic 与化学家合作测试 Claude 处理 NMR 光谱的能力。在小样本对比中,Opus 4.7 的氢谱预测误差低于传统容差窗口的一半,并能在部分任务中从光谱和分子式反推结构。它不是一个可以直接概括到所有化学场景的结论,但说明前沿模型正在进入更专业、更结构化的科学工作流:不是替代实验,而是把“提出可检验假设”的速度拉高。
本周精选
Cursor Auto-review:用 classifier agent 治理 Agent 自主性

Agent 权限不该只有“允许”和“阻止”,更像一个会随上下文变化的风险旋钮。
Cursor 的 Auto-review 用一个轻量级 classifier agent 在工具调用前判断风险。它不是只看命令字符串,而是可以读取文件、搜索工作区,再判断这次操作是否符合用户意图。比如 python script.py 是否安全,取决于脚本内容、目录上下文和当前任务,而不是命令本身。
最值得借鉴的是反馈设计:被拦截时,它不直接打断用户要求确认,而是把原因返回给主 Agent,让主 Agent 自己换一条更安全的路径。Cursor 披露的实测数据是约 4% 的被审查动作会被拦截,约 7% 的会话最终出现至少一次中断。这说明权限治理可以既降低风险,又尽量不把用户重新拖回“审批员”角色。
The Anatomy of an Agent Harness
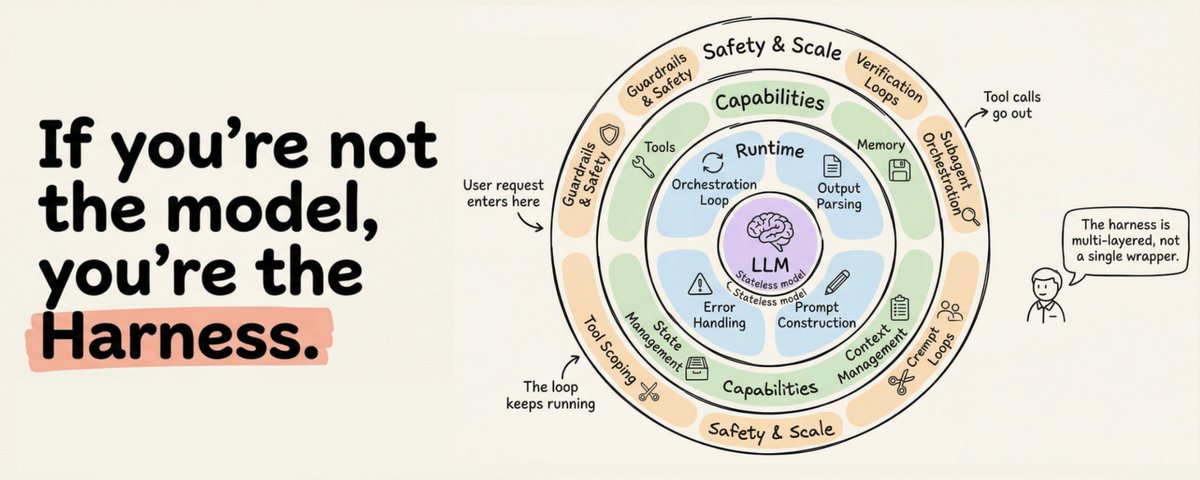
如果模型是 CPU,Agent Harness 就是把它变成可用计算机的操作系统。
Akshay 把 agent harness 拆成 orchestration loop、tools、memory、context management、state persistence、error handling、guardrails 等 12 个组件。文章最好的地方,是把“Agent 为什么从 demo 到生产会崩”讲清楚:问题往往不在模型,而在模型周围的基础设施。工具调用失败、上下文塞满垃圾、状态无法恢复、错误不能被验证,都会让一个看似聪明的 LLM 变成不可靠的系统。
它也把 prompt engineering、context engineering 和 harness engineering 的层级关系讲得很直白。prompt 是指令,context 是模型当下能看到的工作集,而 harness 是完整运行时。对开发者来说,这个框架很适合当成自查表:你到底是在写一个聊天机器人,还是在搭一个能持续执行、能恢复、能被审计的工程系统。
/architect:Claude 当架构师,Codex 当施工队
跨厂商 multi-agent 协作开始出现可复用工程模板。
这个项目把 Claude Fable 5 放在架构师位置,负责拆任务、冻结验收标准、审查结果;把 Codex 放在执行者位置,在独立 worktree 中并行完成实现。它的关键不是“两个模型一起干活”这个噱头,而是把状态收敛到仓库:docs/HANDOFF.md、docs/gates/ 和 git 历史成为跨会话记忆。
这种做法把 Agent 协作从聊天上下文里拉回工程制品。架构师先写清楚验收标准,执行者必须和 spec 辩证,审查最好在新上下文里完成。对真实团队来说,这比“开很多 subagent 让它们自己商量”更接近可维护的工作流。
Building a Good Vertical Agent
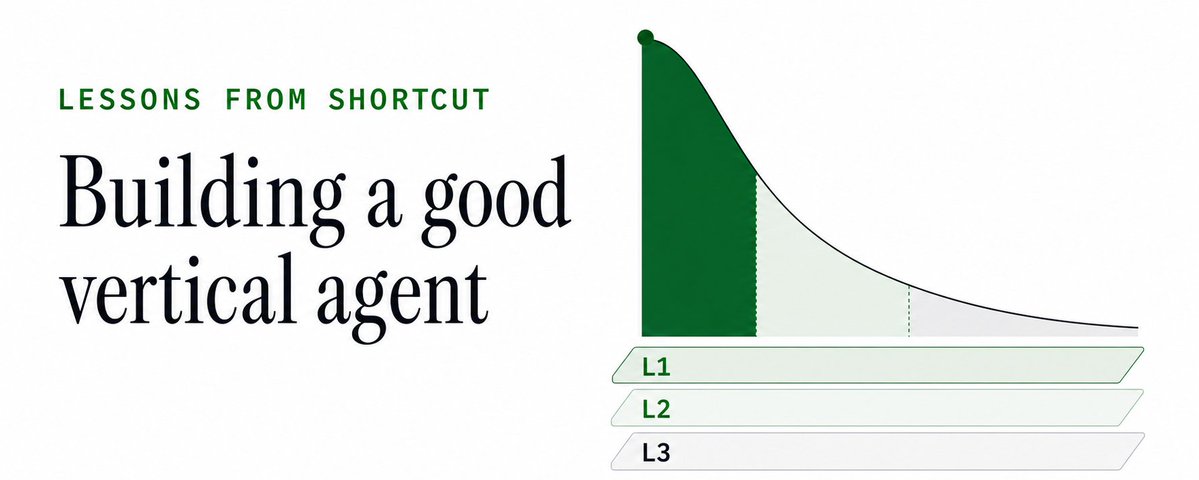
好 Agent 不是更聪明的 while-loop,而是对任务分布的忠实压缩。
Peter Wang 从 Shortcut spreadsheet agent 的实践出发,提出一个很实用的判断:agent 的准确率取决于上下文质量,而上下文质量不是“塞得越多越好”,而是要像 CPU cache 一样分层。L1 放最常用、最热的知识,L2 放可按需加载的中层材料,L3 放更慢但更完整的参考。每个领域都有长尾任务,工程目标是最小化平均每个任务消耗的上下文,而不是把整个领域塞进 prompt。
文章里另一个反直觉点是工具数量:Shortcut 倾向于只给一个 execute_code 工具,而不是几十个细碎工具。原因是工具越多,schema 越占上下文,模型越容易选错;把能力放进代码 API,让模型用编程语言组合能力,反而更稳定。它把 vertical agent 的竞争力从“模型选择”拉回到领域建模、上下文分层和工具界面设计。
Socket:恶意 PyPI / npm 包开始瞄准 MCP 与 AI 开发者
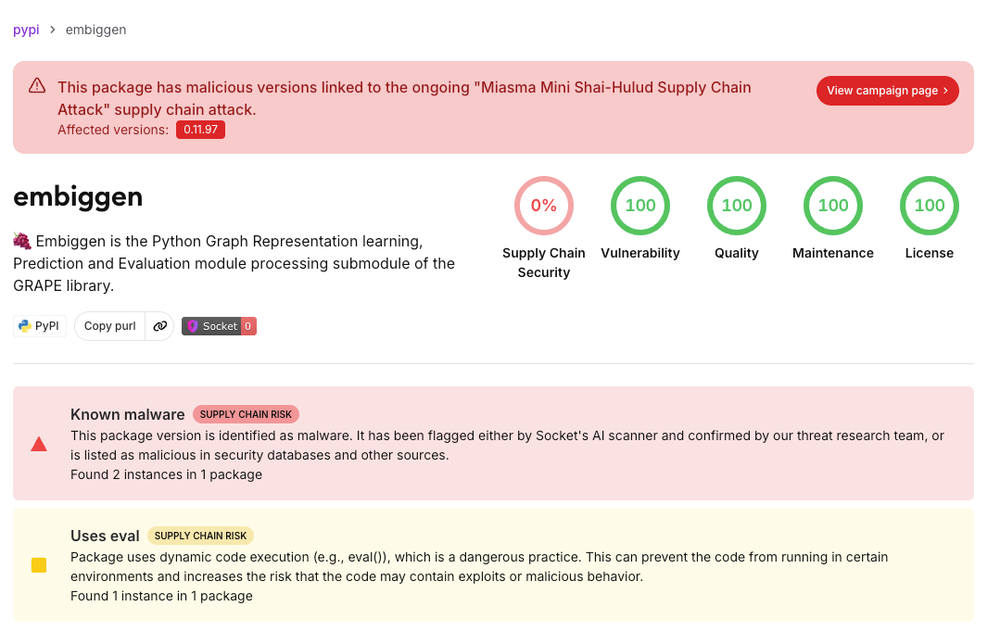
AI 开发工具链已经成为供应链攻击的新入口。
Socket 披露了一组针对 bioinformatics 和 MCP 开发者的恶意包,涉及 npm 与 PyPI 多个制品。攻击链包括 .pth 启动钩子、原生扩展导入时触发、加载器和 payload 分离等方式,目标覆盖 GitHub、npm、PyPI、SSH、Docker、云凭证和 CI/CD 环境变量。
尤其值得注意的是,恶意代码里还出现了伪装成系统指令的注释,试图干扰 LLM 辅助分析。这不是“AI 会不会写恶意软件”的抽象讨论,而是攻击者已经把 LLM 的分析方式纳入对抗面。对 MCP、LangChain、OpenAI-compatible 工具链用户来说,依赖审计和凭证隔离正在变成基本动作。
How to Setup a Local Coding Agent on macOS
本地 coding agent 不只是隐私方案,也是一种供应链和成本对冲。
作者用 llama.cpp、Gemma 4 26B-A4B、MTP 投机解码和多模态 projector,在 M1 Max 64GB 上跑通离线编程 Agent。最有价值的是实测细节:MTP draft 模型把生成速度从 58.2 tok/s 提升到 72.2 tok/s,--spec-draft-n-max 的最优点是 3;MLX 在这个场景反而慢于 llama.cpp。
这篇文章不是在宣称本地模型已经全面追平云端前沿模型,而是给了一个可复现的工作流:当网络、隐私、预算或模型供应链出现限制时,本地 Agent 至少能承担一部分可控任务。它和本周的模型访问争议放在一起看,意义更明显。
Don’t trust large context windows
上下文窗口大小不是可用上下文大小,长会话里的 Agent 会悄悄变笨。
作者把长上下文里的体感问题命名为 smart zone 和 dumb zone:即使模型标称 200k、1M 或 2M,上下文超过某个有效区域后,注意力和指令遵循都会退化。对 coding agent 来说,这尤其危险,因为几轮文件读取、测试日志和调试输出就能迅速堆满上下文。
它给出的实践建议很朴素:不要把 auto-compact 当救命绳,而是主动把重要信息写成 spec、plan、handoff、ADR 这类命名制品,再开启新会话。模型可以读文件,文件也能被人审查;把记忆外置到仓库,比把所有东西塞进聊天窗口更可靠。
社区热议
Fable 5 / Mythos 5 被美国政府指令暂停访问
讨论焦点不只是 Anthropic 这一次是否处理得当,而是前沿模型能否被政策事件突然切断。支持暂停的一方强调国家安全和 jailbreak 风险,反对者则担心这个标准会让所有强模型都处于随时被召回的状态。对开发者来说,最实际的结论是:关键业务不要只绑定一个模型供应商。
给 Claude Code 一个“懒惰资深工程师”模式,代码量减少 6 倍
这条讨论的价值在于它非常可操作:通过提示模型像“懒惰但负责的资深工程师”一样工作,只在必要时写代码,优先复用、删除和简化,用户声称生成代码量减少约 6 倍。社区里不少人分享了类似角色提示。它说明 coding agent 的质量控制不一定都靠复杂工具,有时一个强约束的工程人格就能显著改变输出风格。
稍微减少 AI 生成前端的 slop:让它做成 Qt 应用风格
作者发现,当要求 Agent 生成 Qt 风格界面时,常见的渐变、圆角、emoji、居中大标题等 AI 前端套路会显著减少。评论区有人认同,也有人提出 GTK、Windows 95 等类似锚点。这个讨论有趣的地方在于,它把“AI 审美偏差”从主观吐槽变成了可实验的提示约束。
开源社区
NVIDIA/SkillSpector
本周周榜第一,用来扫描 AI agent skill 的安全风险。
SkillSpector 是一个面向 agent skills 的安全扫描器,可以检测恶意模式、危险权限和潜在漏洞。本周在固定周榜上新增 5257 stars,排名第一。它正好贴合本期主线:当 skill 成为 Agent 的能力扩展单元,skill 本身也会变成供应链入口,需要像依赖包一样被审计。
addyosmani/agent-skills
面向 AI coding agents 的工程 skills 集合,本周继续保持高热度。
这个仓库收集生产级工程 skill,覆盖代码审查、测试、调试、性能、文档等常见任务。本周周榜显示新增 11684 stars。它的价值不在“多几个 prompt”,而在把工程经验打包成可复用的工作单元,让 Agent 在不同仓库里复用同一套判断框架。
mattpocock/skills
Matt Pocock 的工程 skills 发布 1.0.0,开始把 skill 体系整理成稳定接口。
1.0.0 新增 ask-matt 路由 skill,用来根据任务指向合适的 skill 或流程;同时把 codebase-design、domain-modeling、writing-great-skills 等能力抽成共享 skill,并重新梳理 user-invoked 与 model-invoked 的边界。skill 正在从“个人 prompt 收藏”变成可版本化、可依赖、可组合的 Agent 能力包。
kenn-io/agentsview
本地优先的 Agent 会话搜索、统计与洞察工具。
agentsview 支持 Claude Code、Codex 等 20 多种 agent,会在本地分析 session、token 使用和工作模式。本周它仍在活跃更新。随着团队越来越依赖长会话和多 Agent 并行,能回看“Agent 到底做了什么、花了多少 token、在哪些任务上反复失败”的观测工具会变得越来越重要。
DeusData/codebase-memory-mcp
把代码库索引成持久知识图谱的 MCP server。
codebase-memory-mcp 用单个静态二进制索引代码库,支持 158 种语言,并把查询结果以 MCP 工具形式提供给 Agent。它本周在周榜里继续增长,价值点和“不要相信大上下文窗口”正好呼应:与其反复把整仓塞进上下文,不如把代码理解沉淀成可查询的外部记忆。