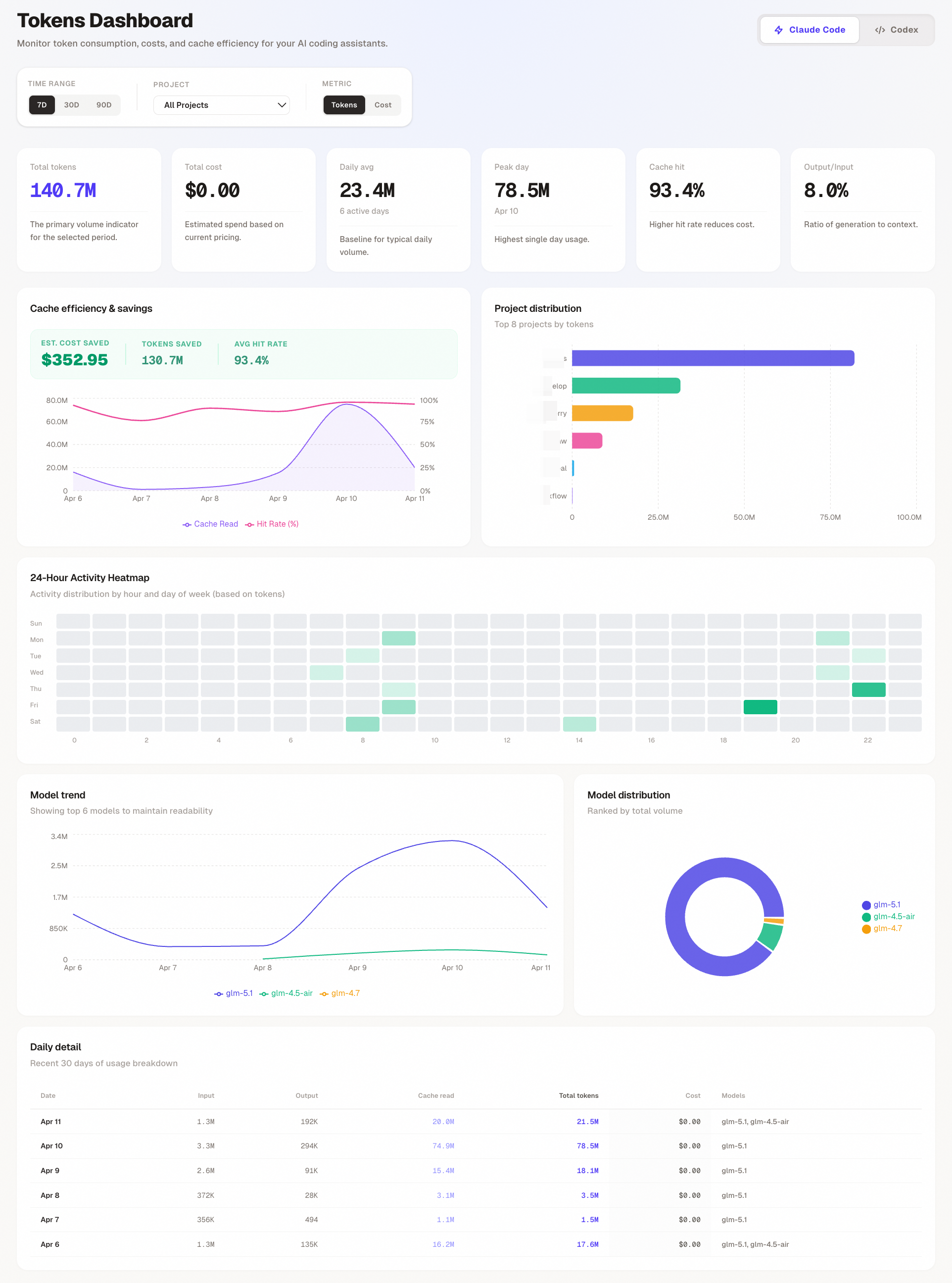
Article 13 Apr, 2026 Claude Code 一款工具帮你可视化 Claude Code/Codex 用量分析 一个开源的本地 Web Dashboard,用于统计与可视化 Claude Code 和 OpenAI Codex 的 Token、费用与缓存命中率。 查看详情