产品介绍
multica(https://multica.ai)定位是为 AI-native 团队设计的人 + Agent 协作平台,主要解决这三个问题:
- Agent 任务管理超出注意力上限。 一个人开两三个终端跑 agent 还应付得来,但当任务量上来,五六个 agent 同时在跑,每个都在自己的终端窗口里输出,再叠加一定的时间跨度,你很难追踪谁做到了哪、结果是什么、需不需要跟进。
- 团队知识孤岛。 每个人都在用 coding agent,但上下文全部散落在各自的 agent session 里。A 做完一件事,B 不知道;agent 跑完一轮,结果只有发起人看得到。
- 多人多 Agent 缺乏协作中枢。 团队同时有多个 agent 在跑任务,人和 agent 之间、agent 和 agent 之间,缺少一个共同的协作界面来协调工作。
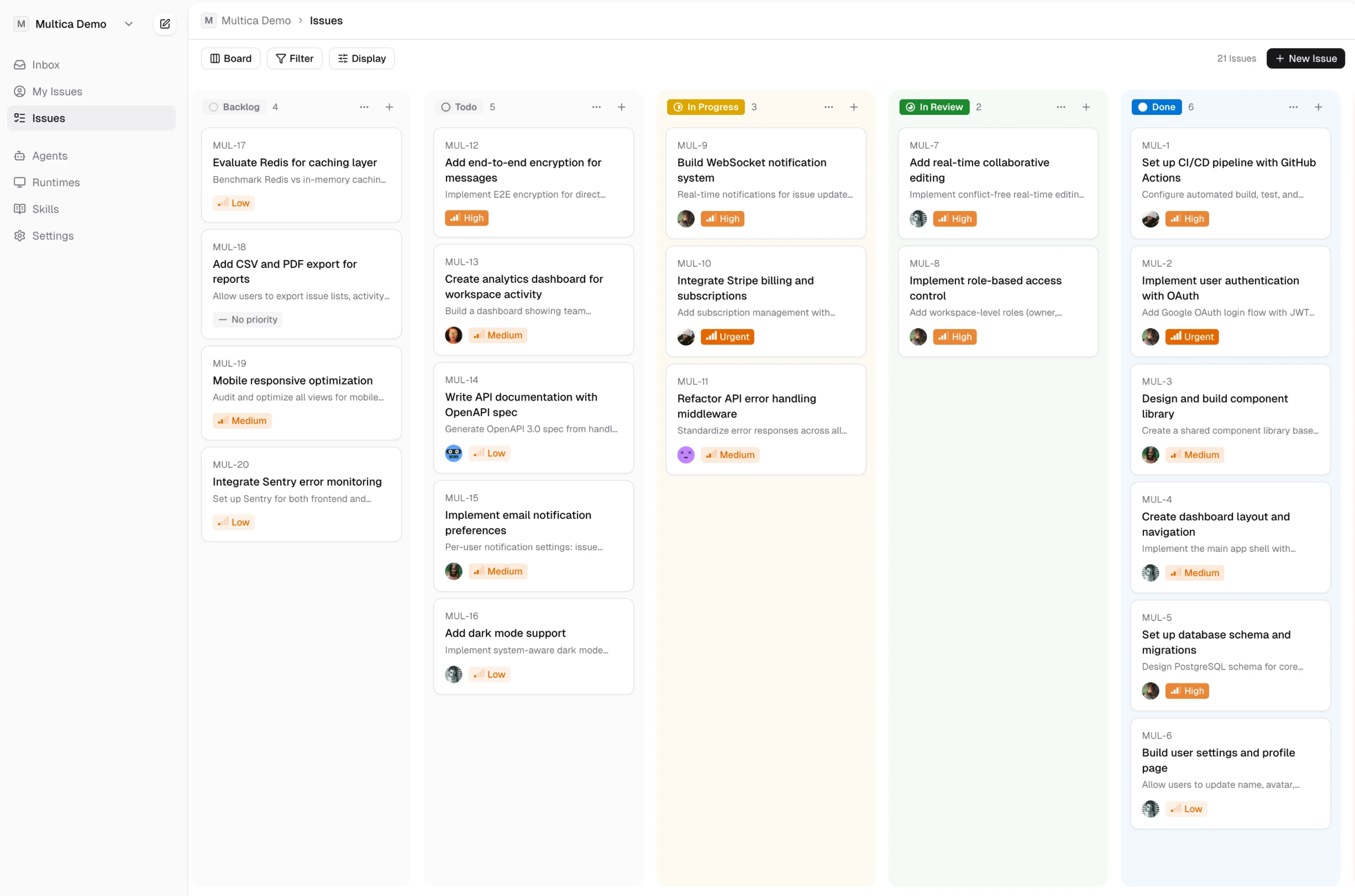
multica 的解法是:每个人把自己的 coding agent(Claude Code / Codex)注册到团队 workspace,然后像分配任务给同事一样,把 issue 分配给 agent。agent 自动领取任务、在你的本地机器上执行代码、提交结果、更新状态——所有事情都发生在一个面板里,你不用在终端之间来回跳。执行结果、上下文、评论全部沉淀在平台,团队成员随时可查。多个 agent 并行跑任务时,谁做到哪了、结果是什么、需不需要跟进,一目了然。
multica 可以个人用,但它主要场景为团队协作设计的。这个定位决定了一些功能上的取舍,这个后面会展开。
核心机制
1. 部署与运行
multica 同时提供 Cloud 和自部署两种模式:
# Cloud 模式:连接 multica Cloud
multica setup
# 自部署模式:连接自己的服务器
multica setup self-host
Cloud 模式,登录之后可以注册一个独立域名 https://multica.ai/<workspace_name>,这里管理所有空间下的任务。
自部署更多满足企业用户,很多团队不是不想用 agent 协作平台,而是不想把代码和任务数据放到第三方云上。自部署意味着数据库、API Server、WebSocket Gateway 全在自己的基础设施里,数据不出内网。
大多数 agent 协作方案的执行发生在云端,agent 在远端服务器上跑,你只能看到结果。multica 反过来了:执行引擎是本机 daemon,代码在你本地跑,在云端的是任务管理流程。这带来三个实际好处:
- 环境天然一致。 agent 在你的机器上执行,访问的是你的开发环境、你的依赖、你的工具链。Claude Code 启动时直接继承你的
HOME、PATH、API Key 等环境变量,不需要在云端复刻一套开发环境。 - 配置管理更可控。 agent CLI 的版本、模型选择、MCP Server 配置都由开发者自己管理。平台不替你决定用哪个模型、哪些工具——你升级 Claude Code 版本、切换模型、调整
CLAUDE.md,daemon 下次启动就生效。 - 代价是运维成本。 每台参与协作的机器都需要装 daemon、配好 agent CLI、保持在线。开发者关机了,agent 就下线。24/7 可用的场景需要专门跑 daemon 的机器。
2. 任务执行
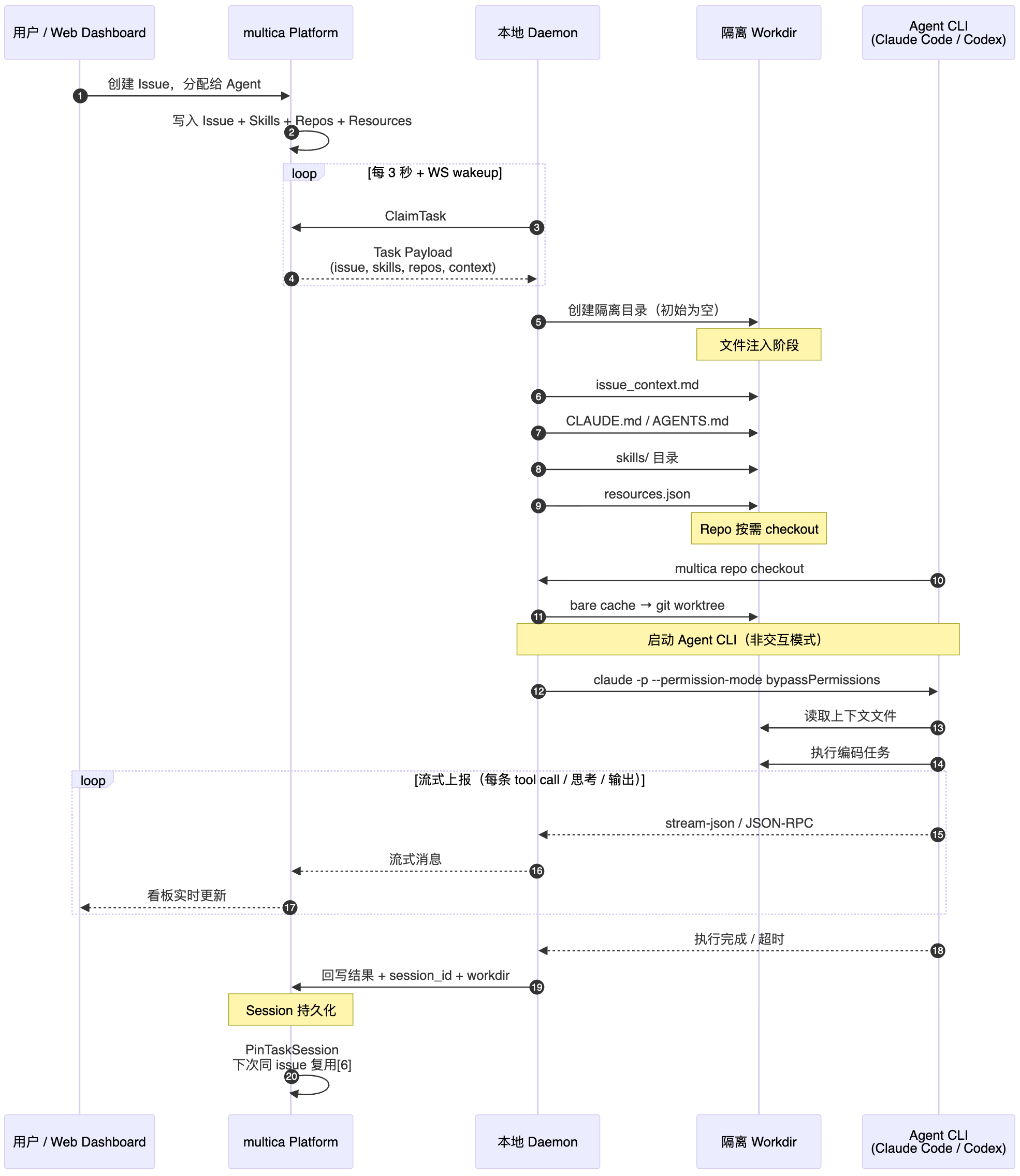
一条 issue 被分配给 agent 后,大致经过以下步骤:
- daemon 从服务端 claim 任务,payload 中带回 issue、skills、repos、project resources 等上下文;
- 在本机准备隔离的工作目录,初始是空的,repo 不会预先全量拉下;
- 把上下文拆成多个文件注入工作目录:
issue_context.md、AGENTS.md/CLAUDE.md、skills 目录、resources.json; - 启动对应 agent CLI,流式转发执行过程。任务执行采用 bypass 权限,防止中间因授权被打断——这是硬编码的,不支持自定义,所以理想的 daemon 应当运行在远程可信设备上;
- 任务结束后把结果、session、workdir 回写服务端。
workdir 的作用
这个设计是 multica 的一大特色,它的很多特点和限制都由此引出。每个任务拿到一个完全独立的工作目录,上下文通过文件注入,代码通过 bare cache + git worktree 按需 checkout。多个任务可以同时跑在同一个仓库上,互不干扰——各自有自己的 worktree,共享底层对象库。
好处是并行任务不会互相污染;上下文注入幂等可靠(覆盖而非合并);poisoned session 可以干净丢弃。以下是 Codex Agent 执行一次 issue 后的工作目录结构:
# ~/multica_workspaces
├── .repos # 所有的 git 仓库
│ └── {workspace_id}
│ └── {project_name}.git
└── {workspace_id}
# {workspace_id}/{issue_id}
├── codex-home # 独立的codex环境
│ ├── auth.json -> ~/.codex/auth.json # 授权软链
│ ├── config.toml
│ └── skills # 只有multica平台配置的skill
├── logs
├── output
└── workdir
├── .agent_context # context folder
├── AGENTS.md # multica Agent Guide
└── repo # 项目实际的 repo 目录,基于 worktree 拉出
干净是干净,但对习惯了直接在项目目录里跑 Codex 的开发者来说,有几个现象会感觉反常:
- 看不到自己的项目文件。 workdir 初始是空的,agent 需要先 checkout 才有代码。你不能在 workdir 里”偷偷加”一个文件然后期待 agent 看到——每次任务准备阶段都会重新生成。
- 默认分支,不能选 feature branch。
RepoData只有 URL 字段,没有 branch 配置。multica 总是用远程仓库的默认分支(main/master),不支持让 agent 在 feature branch 上工作。 - skill/插件生效机制不统一。 对 Codex,每个任务有独立的
codex-home/,用户插件和全局 skill 完全不继承。但 Claude Code 却不受影响——两者行为不对称,不注意可能会踩坑。
理解这些的前提是接受一个设计哲学:workdir 是平台资产,不是开发者的个人工作区。它的设计初衷是满足团队协作——多人(包括 Agent)开发同一个项目,为了避免工作区冲突,隔离是必然选择。但如果你不是团队,只是顺序迭代一个项目,这个设计就会显得不自然。
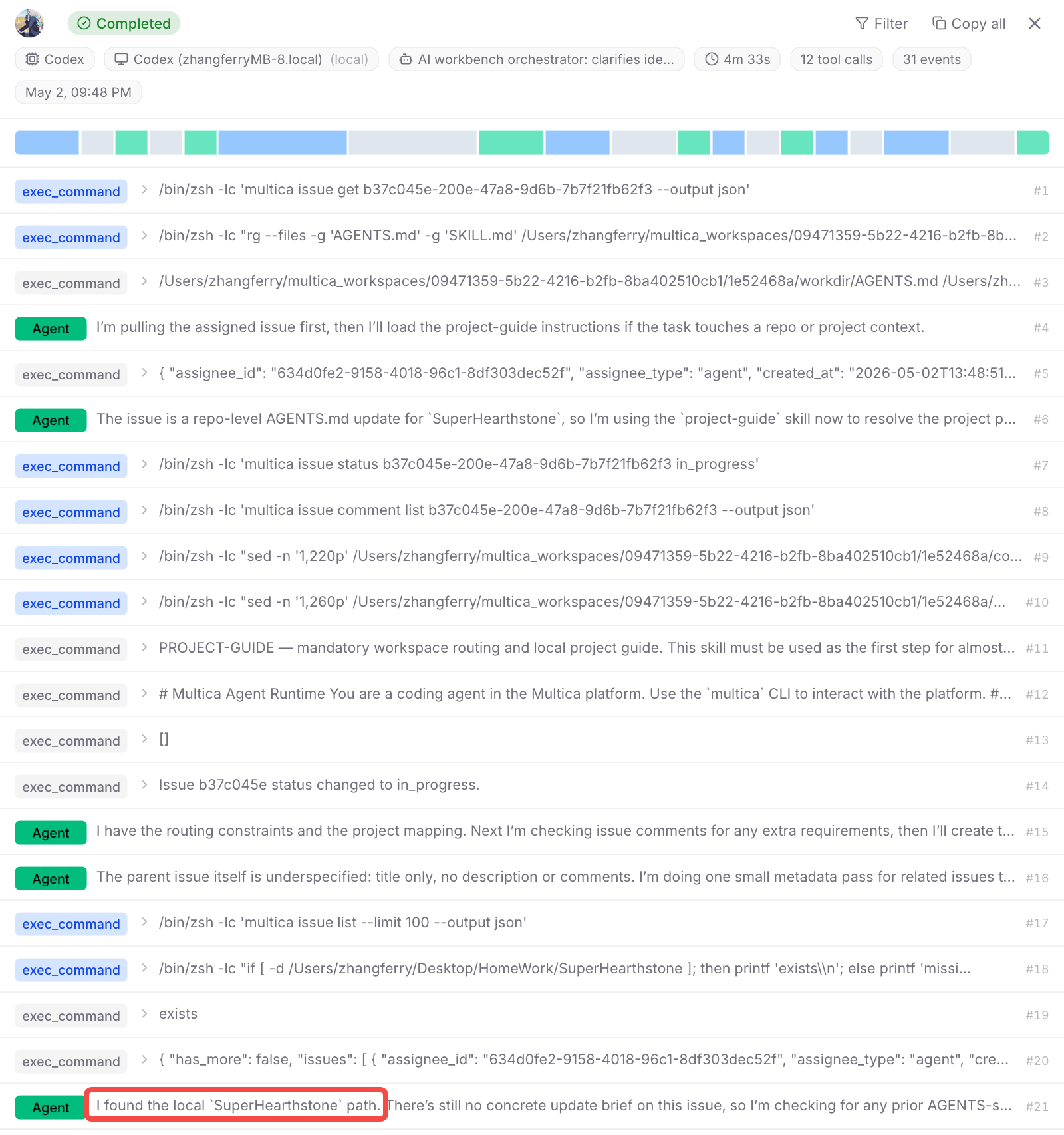
我的做法是写一个 project-guide skill,让 agent 在任务执行前读取,从而知道该去哪个目录工作。但问题就是绕了一大圈——像下面这个例子,直到第 21 轮会话才找到正确的工作目录。
3. 多 agent 协作
多 agent 怎么协同?multica 没有用复杂的 DAG 编排引擎,而是用了一组很朴素的原语:
- issue parent-child 结构:父任务拆子任务,子任务完成后触发父任务继续,可以多层嵌套
- @mention 触发:executor 在执行中 @mention researcher,自动创建子 issue 并派发
- comment 驱动:子任务的结果通过 comment 回写,触发父任务的 agent 继续执行,人也是通过 comment 推进任务
- session 复用:同一个 agent 对同一个 issue 多次执行时,尝试复用上次的 session 和 workdir
以下是一个多 agent 协作的示例,右侧可以看到多个 agent 之间的任务流转记录。
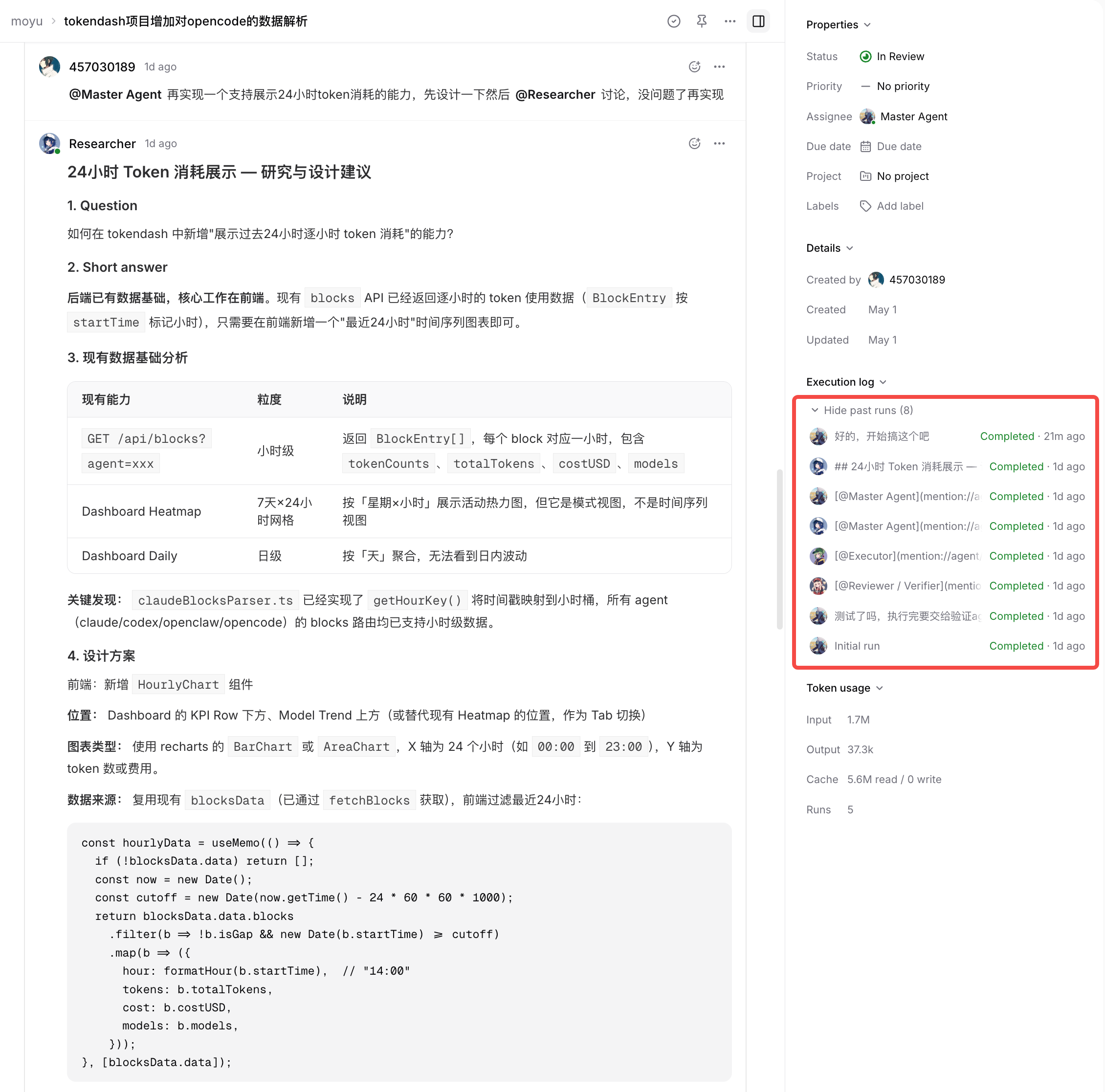
上下文怎么串起来?Agent 被告知的第一件事是运行 multica issue get <ID> --output json 来理解任务。上下文不是通过 prompt 灌进去的,而是写到 workdir 里的文件让 agent 自己读。子任务完成后,结果写入子 issue 的 comment,父 agent 通过再次读取 issue 信息获取子任务结果。
会话恢复也有两层机制:Claude Code 用 --resume <sessionID> 恢复上次的对话,Codex 用 thread/resume JSON-RPC 恢复上次的线程。如果恢复失败(session 已失效),daemon 会自动 fallback 到全新 session 从头开始,不会卡住。
4. 一些玩法
除了基本的任务分配、autopilot 定时任务外,还可以借助 multica 的 CLI 在现有内部服务做一些流程上的集成。它提供了丰富的 cli 能力,可以通过另一个 agent 对它做任何你在网页端的操作:
CORE COMMANDS
agent: Work with agents
autopilot: Manage autopilots (scheduled/triggered agent automations)
issue: Work with issues
project: Work with projects
repo: Work with repositories
skill: Work with skills
workspace: Work with workspaces
RUNTIME COMMANDS
daemon: Control the local agent runtime daemon
runtime: Work with agent runtimes
ADDITIONAL COMMANDS
attachment: Work with attachments
auth: Authenticate multica with multica
config: Manage configuration for multica
login: Authenticate and set up workspaces
setup: Configure the CLI, authenticate, and start the daemon
update: Update multica to the latest version
还有一些值得尝试的玩法:
- Slack / 飞书 Bot:在办公场景,讨论出一个需求,直接 @bot 让它把任务加到 multica 里。但目前任务状态变更还没有提供 webhook,只能通过轮询查看进度,期待后续支持。
- Bug 修复:bug 平台报警或新增 bug,自动触发 issue 创建,agent 在隔离环境里分析和修复。这比”人看到通知再去手动创建 task”会快很多。
- CI/CD 联动:multica task 执行完成后触发 CI pipeline,CI 失败后反向创建 multica issue 让 agent 修复,形成”写代码 → 跑测试 → 修 bug”的自动循环。
- Figma / Storybook:设计稿作为 project resource 注入,agent 可以基于设计稿生成 UI 代码。multica 的 resources.json 机制天然支持这种扩展。
同类竞品
Craft Agents
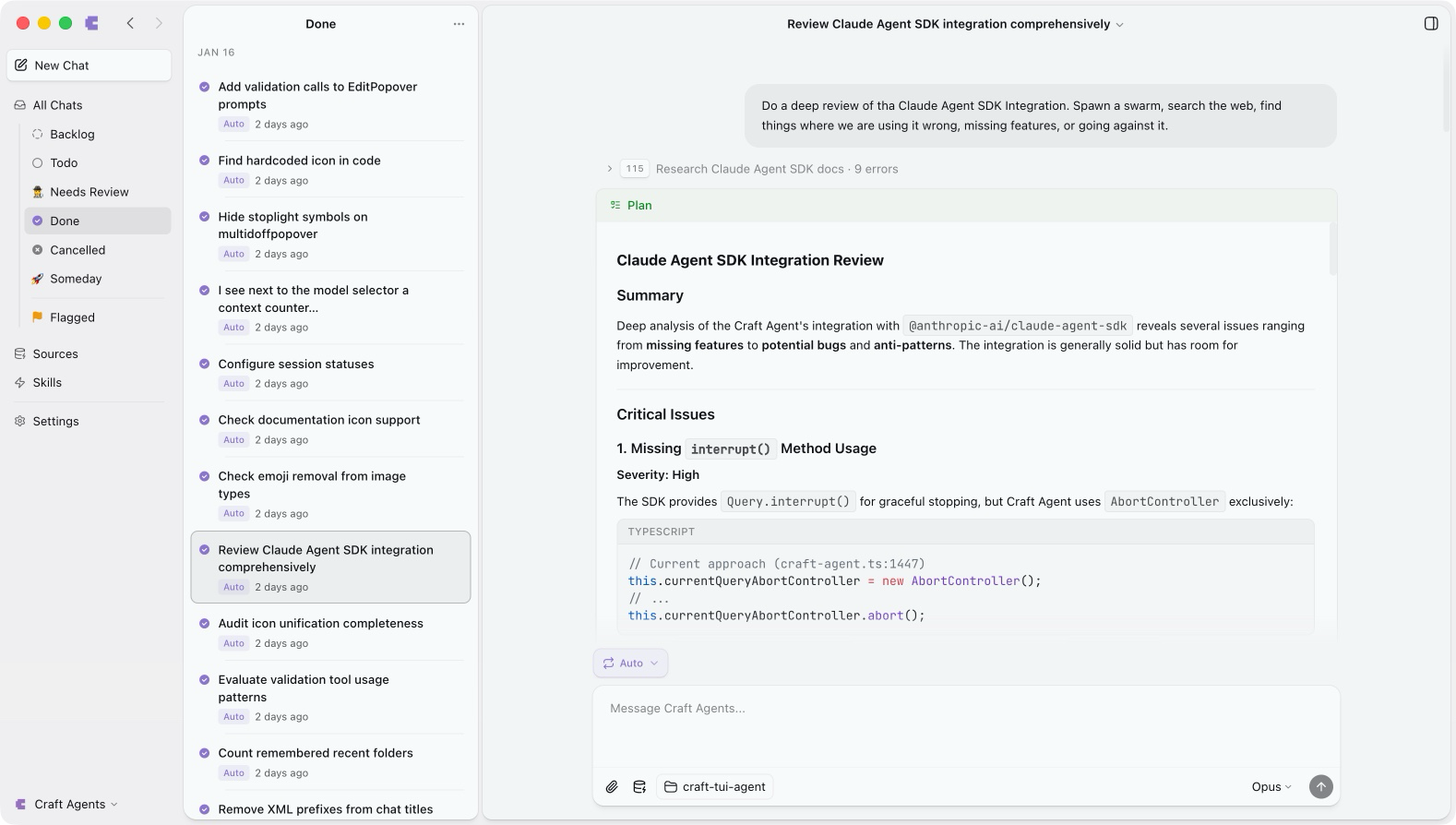
Craft 在 2026 年 2 月开源了 Craft Agents,定位是”文档中心化的 agent 界面”。它支持多 LLM 后端,有 Multi-Session Inbox 管理和状态工作流,还支持三级权限模式(只读 Explore / 需确认 Ask to Edit / 全自动 Auto)和事件驱动自动化。
但 Craft Agents 的核心模型还是”对话 + 文档”——它是一个增强版的 agent 聊天界面,不是代码执行平台。它不关心 agent 在哪台机器上跑、代码仓库怎么隔离、session 怎么持久化。
另外它使用的是官方授权登录,直接拒绝了国内各种 Coding Plan 用户,这个是我认为不太友好的地方。
Linear
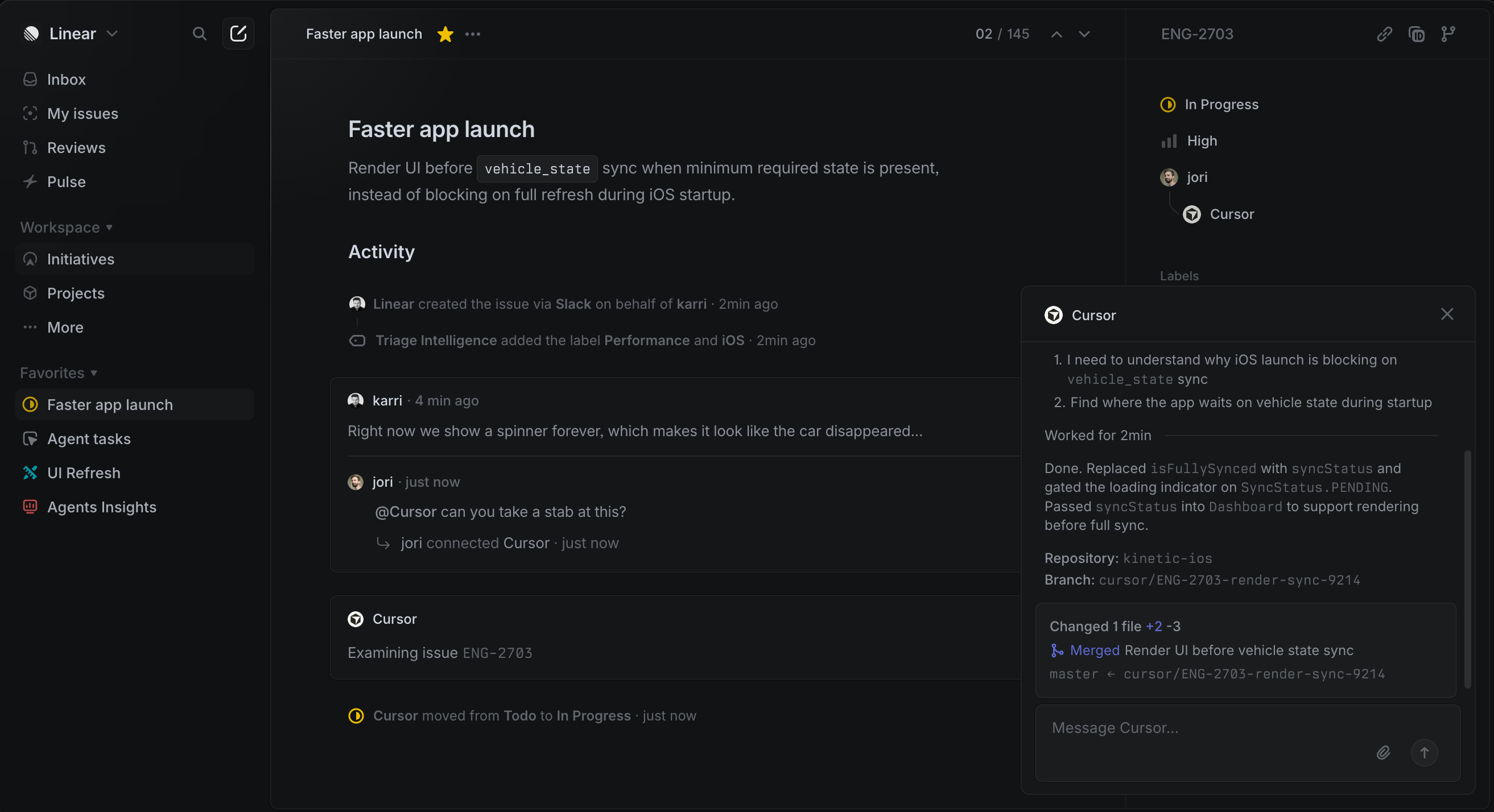
在任务管理层面最接近 multica 的”工作流层”——issue、cycle、status machine、webhook 都很成熟,很多团队已经用 Linear 作为 agent 的任务源。但 Linear 的定位是”给人用的项目管理工具”,它不关心任务是怎么执行的。
multica 团队早期也都是 Linear 用户,所以产品里确实能看到不少 Linear 的影子。
multica 特色
multica 体现的工程判断是清晰的:
- 不把所有智能塞进平台后端,而是让本地 agent 作为一等公民。
- 不把任务执行做成黑箱,而是保留运行日志、tool 轨迹、session 指针与 workdir。
- 不追求对所有 provider 做统一抽象,而是利用各自已有的 skill / config 入口。
- 不让 repo 获取成为随意网络访问,而是纳入 workspace 边界和本地 daemon 控制。
- 足够开放,可自部署,可直接调用 cli
这条路线的代价是实现复杂度更高、边缘兼容问题更多;但它换来的,是一种更接近真实研发团队工作流的 agent 基础设施雏形。
从适用性看:如果你的团队已经在用多种 coding agent、需要多人协作和任务追踪,multica 值得认真试一轮。如果你只是个人用 Claude Code 写代码,现阶段直接用 CLI + CLAUDE.md 可能更轻量——multica 的价值在多人场景下才真正显现。
对 agent 工作台的畅想
multica 的设计不禁让人想到一个问题:理想的 agent 工作台应该是什么样的?
当前大多数 agent 工具的设计思路还停留在”给人一个更好的聊天窗口”。但 agent 和人的工作方式有本质区别:人需要的是灵活的编辑和沟通界面,agent 需要的是结构化的指令、明确的执行边界、可追溯的产出。
从这个角度看,理想的 agent 工作台至少应该具备几个特征:
任务应该是可执行的,不只是可描述的。 一条 issue 不应该只是一段给人看的文字,它应该携带足够的结构化信息让 agent 知道”去哪、做什么、怎么交付”。multica 在这方面走了一步——issue context、repo、skills 都被写入 workdir——但还有很大的空间,比如自动关联 CI/CD 状态、依赖关系、测试结果。
上下文管理应该是自动的,而不是靠人去维护。 现在大多数人用 agent 的方式是手动准备 prompt、手动贴代码、手动提供项目背景。这在单人场景下还行,多人场景下完全不可持续。multica 的文件注入机制是一个雏形,但理想态应该是:agent 进入一个 workspace 就自动知道所有相关的代码库、文档、历史决策,不需要人去”教”它。
执行应该是可观测且可控的,而不是黑箱。 multica 的流式消息上报做得不错——你能在面板上看到 agent 每一步在干什么。Craft Agents 在控制维度上做了有趣的设计:三级权限模式(只读 Explore / 需确认 Ask to Edit / 全自动 Auto),让团队可以按风险级别选择 agent 的自主程度。更进一步,理想的系统应该能让”回放”一次 agent 执行就像回放一段录像:哪些文件被读了、哪些被改了、每一步的思考链是什么、哪些决策点可以被人工干预。
协作应该是原生的,而不是后加的。 现在的 agent 工具大多是”单人版 + 共享功能”。multica 的 issue-based 协作是一个方向,但也许更自然的模型是类似 Google Docs 的实时协作——多个 agent 和多个人同时在一个 workspace 里工作,彼此能看到对方的修改和意图,而不是通过 issue comment 来异步通信。
Skill 和知识应该是流动的,而不是静态配置的。 multica 的 skill 分发机制已经很工程化了,但它还是”分配”模式——平台决定哪个 agent 拥有哪些 skill。更理想的状态可能是:skill 能被 agent 自主发现和加载,根据任务上下文动态决定需要什么能力,就像人根据任务需要去查文档一样。Craft Agents 在这方面走了一步——通过 MCP 协议让 agent 动态连接外部数据源——但它解决的是数据访问层,不是执行能力层。
这些都不是 multica 现在能做到的,但它至少搭了一个底座:本地 daemon + 隔离 workdir + 文件注入 + 多 provider + 会话复用。在这个底座上,上面这些能力是可以逐步叠加的。