
论文:Agentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses
arXiv:https://arxiv.org/abs/2604.25850
代码仓库:https://github.com/china-qijizhifeng/agentic-harness-engineering
作者:Jiahang Lin, Shichun Liu, Chengjun Pan, Lizhi Lin, Shihan Dou, Xuanjing Huang, Hang Yan, Zhenhua Han, Tao Gui(复旦 / 北大 / 齐济智风)
核心问题:为什么要从 Prompt 走向 Harness?
一句话总结
这篇论文提出了 AHE, Agentic Harness Engineering:不要只让模型学会写代码,也不要只自动改 prompt,而是让一个独立的进化 agent 根据 benchmark 轨迹,自动修改 coding agent 周围的 harness,包括 system prompt、工具描述、工具实现、中间件、技能、子 agent 配置和长期记忆。
它的核心观点是:
对长程 coding agent 来说,性能瓶颈不只是模型本身,而是模型外面的执行系统。只要这个系统足够可观测、可编辑、可回滚,agent 就可以像工程师一样持续改进它。
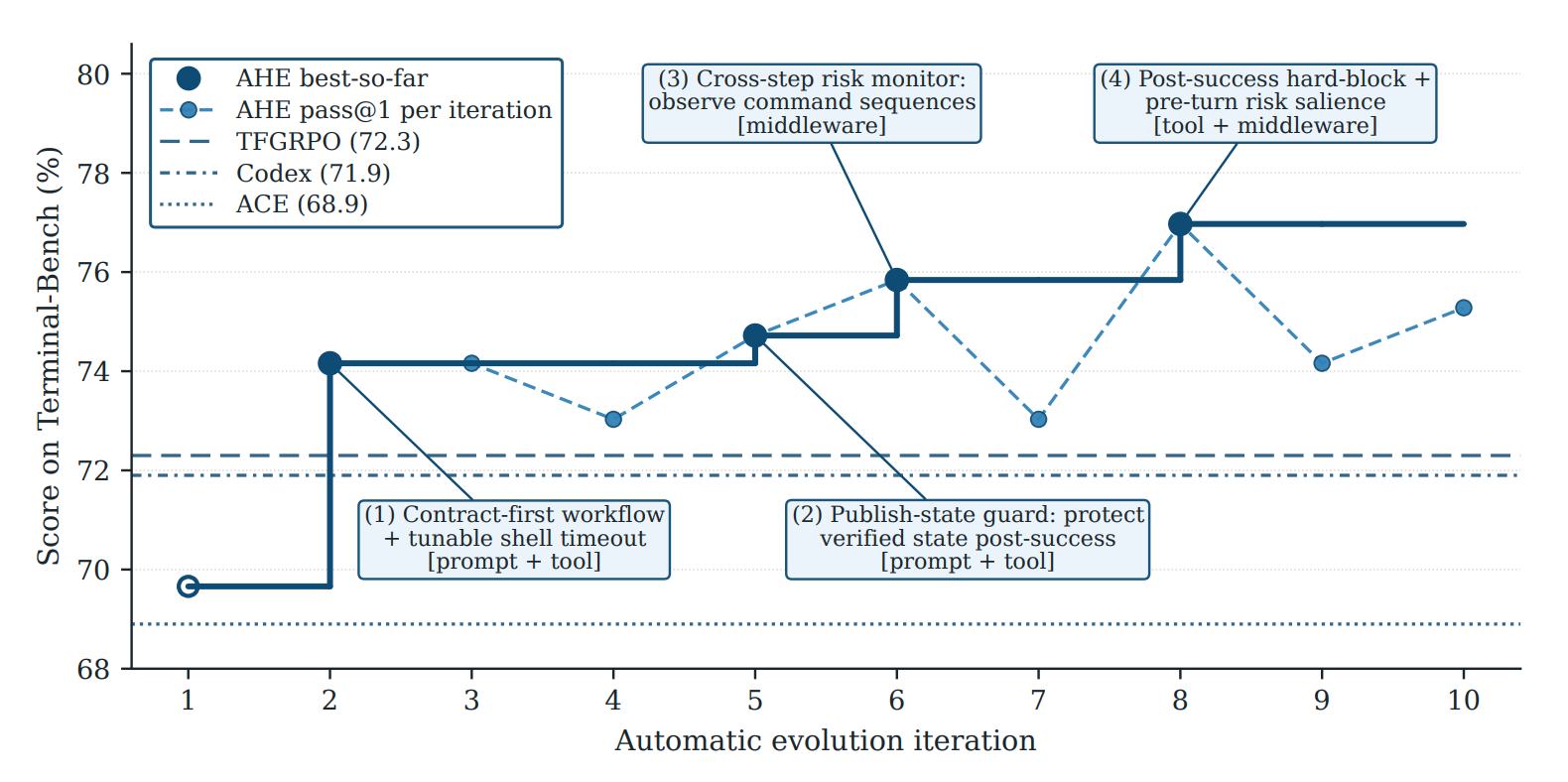
论文在 Terminal-Bench 2(一个终端编程任务评测基准)上做了 10 轮自动进化,pass@1(一次成功率)从 69.7% 提升到 77.0%。注意所有对比方法共享同一个 base model(GPT-5.4),差异纯粹来自 harness:AHE 超过了人工设计的 Codex-CLI harness 71.9%,也超过了 ACE、TF-GRPO 这类自进化基线。更有价值的是,冻结后的 harness 不再继续进化,直接迁移到 SWE-bench-verified(另一个主流代码修复评测基准)和其他模型族上仍然有效。
先说清楚:什么是 Harness?
在 coding agent 场景里,harness 可以理解为”模型之外的工程脚手架”。它决定了模型如何观察环境、如何调用工具、如何执行命令、如何记忆经验、如何判断任务结束。
一个典型 coding-agent harness 至少包含这些东西:
| 组件 | 作用 |
|---|---|
| System prompt | 规定 agent 的工作风格、约束和任务流程 |
| Tool description | 告诉模型有哪些工具、工具怎么用、什么情况下用 |
| Tool implementation | 真正执行文件读写、shell、搜索、测试等动作的代码 |
| Middleware | 在模型和工具之间插入控制逻辑,例如 finish 前强制验证 |
| Skill | 可复用的任务经验,例如调试、打包、测试策略 |
| Sub-agent config | 多 agent 分工和调用配置 |
| Long-term memory | 从历史任务中沉淀的长期经验 |
这篇论文要解决的问题是:如果这些组件都能被文件化、版本化、评估化,那么能不能让 agent 自动修改它们?
这篇论文的团队背景
从公开信息看,这篇论文背后的团队不是一个单纯的产品工程团队,而是 高校 NLP/Agent 研究团队 + Agent 基础设施创业/产业团队 的组合。
论文作者署名机构包括三方:
| 机构 | 参与作者 | 背景判断 |
|---|---|---|
| Fudan University | Jiahang Lin、Shichun Liu、Shihan Dou、Xuanjing Huang、Tao Gui | 复旦 NLP / LLM / Agent 研究线,是论文的主要学术研究主体之一 |
| Peking University | Chengjun Pan | 北大作者参与,可能承担算法、实验或系统研究协作 |
| Shanghai Qiji Zhifeng Co., Ltd | Lizhi Lin、Hang Yan、Zhenhua Han | 上海齐济智风,论文代码托管在 china-qijizhifeng GitHub 组织下,和 NexAU / agentic harness 基础设施关系紧密 |
其中值得注意的是两条线:
-
复旦 NLP 系研究积累 通讯作者 Tao Gui 和 Xuanjing Huang 都来自复旦相关 NLP / 大模型研究体系。这个团队长期做自然语言处理、LLM agent、代码智能体和 agent 评测相关工作。论文里的 Agent Debugger、trajectory analysis、self-evolution 这些关键词,很符合高校团队在”可解释、可评估、可归因”的研究口味。
-
Nex / 齐济智风的系统工程背景 AHE 的方法依赖一个可编辑、解耦的 harness substrate:NexAU(Nex Agent Universe)。Nex 是上海创新研究院、齐济智风等联合打造的全栈 AI Agent 平台,NexAU 是其中的 agent 框架,核心理念是”低门槛、高效率、灵活定制”,支持动态工具注入、Skills、Sub-agents、Hooks、MCP、状态管理、记忆压缩/召回和全链路可观测性。AHE 的 seed harness 和七类可编辑组件全部建立在 NexAU 之上——每个组件都是文件级 artifact,挂在固定挂载点上,所有改动 git 可追踪。代码仓库属于
china-qijizhifeng,论文署名里也有 Shanghai Qiji Zhifeng Co., Ltd,这说明这项工作很可能来自”研究团队 + 实际 agent 框架团队”共同打磨:高校负责问题定义、实验设计和归因分析,产业/框架团队提供 NexAU 这类 agent runtime 和工程 substrate。
这也解释了为什么 AHE 不是一篇典型的”prompt 优化论文”。它的关注点非常工程化:工具实现、middleware、long-term memory、manifest、rollback、git history、benchmark rollout,这些都更像真实 agent 平台团队在反复调系统时遇到的问题。换句话说,这篇论文的背景是 LLM agent 研究正在和 agent runtime 工程合流:一边追求 benchmark 上的可证实提升,另一边把提升落到可维护的系统组件里。
论文为什么重要?
过去大家优化 agent,大致有三条路线:
- 训练或微调模型:改模型参数,成本高,闭源模型通常做不了。
- 优化 prompt / playbook:让模型把经验写进上下文,简单但容易变成长文本负担。
- 改 agent 系统本身:调整工具、中间件、记忆、执行约束,但通常靠人手工做。
AHE 把第三条路线自动化了。它不是让模型”反思一下下次做得更好”,而是让一个 Evolve Agent 阅读失败轨迹,定位 harness 的问题,然后实际修改 harness 文件,并在下一轮用 benchmark 验证修改是否真的有效。
这和 prompt self-refinement 的差别非常大:
- prompt 优化通常只改自然语言策略;
- AHE 可以改工具实现、工具描述、中间件和长期记忆;
- prompt 优化的效果很难归因;
- AHE 要求每次修改都写入 manifest(修改合同:记录改了什么、预计修复和可能回归哪些任务),下一轮自动验账。
论文最有启发的地方就在这里:经验不是只存在 prompt 里,也可以存在可执行、可审计、可回滚的工程组件里。
术语速查
为了便于理解后续的流程解读,针对一些术语进行简要介绍。
| 术语 | 含义 |
|---|---|
| Terminal-Bench 2 | 一个 coding agent 评测基准,包含 89 个终端环境下的真实编程任务(部署、调试、打包等),按难度分 easy / medium / hard。 |
| SWE-bench-verified | 另一个主流 coding agent 评测基准,来自 GitHub 真实 Python 仓库的 issue 修复任务,共 500 个。 |
| pass@1 | 评测指标:每个任务只跑一次就成功的比例。数值越高说明 agent 的”一次性解决能力”越强。 |
| rollout | agent 完成一个任务的完整执行过程(从收到任务到最终提交结果)。每次 rollout 在独立沙箱中从头运行,因 LLM 采样随机性,同一任务多次 rollout 可能走不同路径。论文中每题跑 k=2 次,pass@1 取这 2 次的平均成功率,以获得更稳定的能力评估。 |
| seed harness | 进化的起点——一个极简的初始 harness(论文中只有一个 shell 执行工具),用来排除”人工调参”的干扰,确保性能提升纯粹来自自动进化。 |
| manifest | 每次 harness 修改的”合同”:记录改了什么、依据什么证据、预计修复哪些任务、担心哪些任务回归。下一轮自动验证是否兑现。 |
| ACE | Agent-Computer-Environment,一种 agent 自进化方法,把经验写成 playbook(可复用策略文本)塞进上下文,让 agent 参考历史经验执行新任务。 |
| TF-GRPO | 基于轨迹偏好(trajectory preference)的强化学习方法,通过对比成功和失败的执行轨迹来优化 agent 行为。 |
| opencode | 开源终端编程 agent(来自 Anomaly),类似 Claude Code / Codex CLI 的 coding 工具。 |
| terminus-2 / Harbor | Harbor 是 Terminal-Bench 官方的评测调度框架,负责分发任务、隔离环境、判定结果;terminus-2 是 Harbor 内置的一种预设 harness 配置。 |
| NexAU | Nex Agent Universe,Nex 全栈 AI Agent 平台中的 agent 框架。支持动态工具注入、Skills、Sub-agents、Hooks、记忆管理和全链路可观测性,AHE 的 harness 组件全部建立在 NexAU 的文件级挂载点上。 |
方法主线:AHE 如何让 Harness 自我进化?
AHE 的整体架构
AHE 是一个闭环系统,主要有三个角色:
- Code Agent:真正去跑 coding benchmark 的 agent。
- Agent Debugger:阅读 Code Agent 的轨迹,分析失败根因和成功模式。
- Evolve Agent:根据分析结果修改 harness,并记录修改理由和预测影响。
可以先用一张图理解三类 agent 的分工:

整个循环可以概括为:
Evaluate -> Analyze -> Improve -> Re-evaluate
流程可以更细地展开:
输入:seed harness H0、base model M、benchmark D、每题 rollout(从头执行一次任务的完整过程)数 k、最大迭代 N
for t in 1..N:
1. 用当前 harness 在 benchmark 上跑 k 次 rollout,得到轨迹 T_t
2. 清洗轨迹,去掉 base64、大段重复工具输出等噪声
3. 从第 2 轮开始,对上一轮 manifest 做归因:
- 预测修复的任务是否真的修了?
- 预测风险的任务是否真的回归了?
- 无效修改按文件粒度回滚
4. Agent Debugger 把轨迹蒸馏成分层证据库
5. Evolve Agent 阅读证据,修改 harness,写入新的 manifest
6. commit 当前 harness 和 manifest
这里有两个很关键的设计:
- 模型固定:实验中 base model 不变,性能提升只能归因于 harness 修改。
- seed 很弱:初始 harness 只有一个 shell 执行工具,没有 middleware、skills、sub-agent,避免一开始就混入大量人工经验。
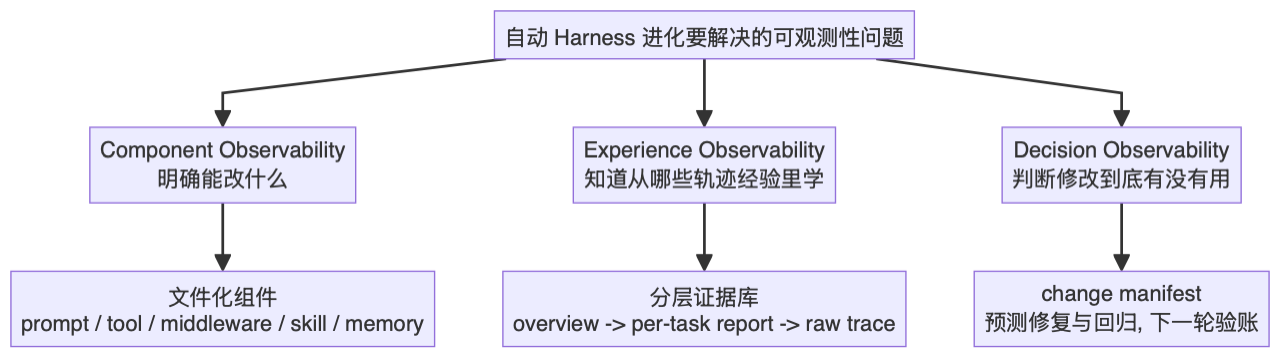
三个 Observability:AHE 的真正核心
论文标题里有 “Observability-Driven”,这不是装饰词。作者认为自动 harness 进化的难点不是 agent 不够聪明,而是它看不清三个东西:
- 它到底能改什么?
- 它应该从哪些历史经验里学?
- 它做的修改到底有没有用?
AHE 对应提出了三层 observability。
Component Observability:让 harness 组件变成明确文件
AHE 基于 NexAU 框架,把 harness 拆成七类正交组件:
- system prompt
- tool description
- tool implementation
- middleware
- skill
- sub-agent configuration
- long-term memory
这些组件都有固定挂载点,都是文件级 artifact。这样 Evolve Agent 修改 harness 时,不是在一大坨 prompt 里”凭感觉加两段话”,而是在一个明确的动作空间里工作。
这个设计带来三个好处:
- 可定位:某类失败可以映射到某类组件,例如工具问题、结束条件问题、记忆问题。
- 可回滚:每个逻辑修改是一个 git commit,可以按文件粒度撤销。
- 可归因:下一轮性能变化可以和具体组件修改建立联系。
这点很像软件工程里的模块化:你只有先把系统拆成清楚的模块,才能谈自动优化。
Experience Observability:把千万 token 轨迹变成可钻取证据库
长程 coding-agent benchmark 最大的问题之一是轨迹太长。一次 benchmark 可能产生上千万 token 的消息、命令、日志、文件 diff、测试输出。直接把这些塞给 Evolve Agent 不现实,粗暴总结又会丢掉关键细节。
AHE 使用 Agent Debugger,把原始轨迹变成一个分层证据库:
- Raw trace:原始轨迹保留,作为事实源。
- Cleaned trace:去掉 base64、重复工具输出等噪声,但保留消息顺序和调用结构。
- Per-task analysis:每个任务一份分析报告,写清失败根因、成功模式、pass/fail 状态。
- Benchmark-level overview:聚合所有任务报告,作为每轮 Evolve Agent 的入口。
这叫 progressive disclosure:agent 先读全局 overview,需要证据时再钻到 per-task report,仍然不确定时再回原始 trace。
这比”总结一下失败原因”更工程化,因为它保留了可追溯链路。Evolve Agent 不是靠一个摘要做决策,而是有索引、有证据、有原始轨迹兜底。
Decision Observability:每次修改都必须可证伪
AHE 最狠的一刀是 change manifest。
每次 Evolve Agent 修改 harness,都必须记录:
- 这次修改依据了哪些失败证据;
- 推断的根因是什么;
- 实际修改了什么;
- 预计会修复哪些任务;
- 哪些任务可能有回归风险。
下一轮 benchmark 跑完后,系统会把预测和真实结果对齐:
- 如果预测修复的任务真的改善了,这个修改被支持;
- 如果没有改善,或者引入明显回归,就可能被回滚;
- 系统还能统计 Evolve Agent 对”修复”和”回归”的预测能力。
这让 harness 修改从”自我解释”变成了”可证伪合同”。这也是 AHE 区别于很多 self-reflection 方法的关键:它不是让 agent 写一段漂亮理由,而是让理由承担下一轮验证压力。
实验结果:AHE 到底强在哪里?
实验设置
论文主要回答三个问题:
- AHE 相比人工 harness 和其他自动方法是否更强?
- AHE 是否过拟合 Terminal-Bench 2?
- AHE 的收益来自哪些组件,归因机制是否靠谱?
主要设置如下:
- 进化 benchmark:Terminal-Bench 2,共 89 个任务,其中 easy 4 个、medium 55 个、hard 30 个。
- 每题 rollout:k = 2。
- 迭代次数:10 轮。
- 单题 timeout:1 小时。
- 主实验模型:GPT-5.4 high reasoning(所有对比方法共享同一 base model,差异只来自 harness)。
- 迁移 benchmark:SWE-bench-verified,500 个任务,覆盖 7 个仓库。
- 指标:
- pass@1:任务平均成功率;
- tokens/trial:每次 trial 平均 token 消耗。
对比方法包括:
- 人工设计 harness:
- opencode:开源 coding agent(来自 Anomaly),类似 Claude Code / Codex CLI 的终端编程工具;
- terminus-2:Harbor 项目的内置 harness。Harbor 是 Terminal-Bench 官方提供的评测调度框架,负责分发任务、隔离执行环境和判定 pass/fail;
- Codex-CLI:OpenAI 的终端编程 agent。
- 同 seed 自进化方法:ACE、TF-GRPO;
- AHE 自己从 bash-only NexAU0 seed 开始进化。
主结果:Terminal-Bench 2 从 69.7% 到 77.0%
主表结果如下:
| Method | All | Easy | Medium | Hard |
|---|---|---|---|---|
| opencode | 47.2% | 75.0% | 52.7% | 33.3% |
| terminus-2 | 62.9% | 75.0% | 74.5% | 40.0% |
| Codex-CLI | 71.9% | 75.0% | 80.0% | 56.7% |
| NexAU0 seed | 69.7% | 87.5% | 78.2% | 51.7% |
| ACE | 68.9% | 91.7% | 78.2% | 48.9% |
| TF-GRPO | 72.3% | 100.0% | 79.4% | 55.6% |
| AHE | 77.0% | 100.0% | 88.2% | 53.3% |
几个观察:
- AHE 总体最强:All 从 seed 的 69.7% 到 77.0%,提升 7.3 个百分点。
- Medium 提升最大:从 78.2% 到 88.2%,提升 10 个百分点。由于 89 个任务里 medium 有 55 个,所以它主导了 aggregate。
- Hard 不如 Codex-CLI:AHE hard 53.3%,Codex-CLI 56.7%。论文后面解释,这可能来自多个组件在长程任务上重复验证、消耗预算,而不是能力完全缺失。
- ACE 甚至低于 seed:说明把经验塞进 prompt/playbook 不一定稳,尤其当经验和新任务表面不完全匹配时,会增加上下文成本和行为干扰。
这组结果支持论文的核心判断:收益不只是来自”更多自然语言反思”,而是来自可执行 harness 组件的结构化进化。
迁移结果:不是只会刷 Terminal-Bench
如果一个自进化系统只在目标 benchmark 上有效,那它很可能是在 benchmark-specific tuning。AHE 做了两类迁移实验。
迁移到 SWE-bench-verified
AHE 在 Terminal-Bench 2 上进化完后,冻结 harness,不继续训练或进化,直接跑 SWE-bench-verified。
整体结果:
| Method | Success | Tokens k |
|---|---|---|
| ACE | 74.6% | 679 |
| TF-GRPO | 74.2% | 582 |
| NexAU0 seed | 75.2% | 526 |
| AHE | 75.6% | 461 |
这个结果的提升幅度不大,但方向很关键:
- 成功率 AHE 最高:75.6%;
- token 消耗最低:461k,比 seed 少约 12%,比 ACE 少约 32%;
- ACE 和 TF-GRPO 在成功率上反而低于 seed,同时 token 更多。
论文的解释是:ACE/TF-GRPO 这类方法更多把经验放在 prompt 或工具序列偏好里,迁移到 SWE-bench 后,这些文本/策略可能变成成本负担。AHE 则把经验固化进工具、中间件和长期记忆里,减少了每次调用时重新推理的成本。
分仓库看,AHE 在 django 和 sphinx-doc 这类更大、更 token-expensive、需要多步 edit-and-verify 的仓库上更有优势;在 scikit-learn、pydata、astropy 等较小子集上有小幅回归,作者认为这可能与小样本 pass@1 方差有关。
迁移到其他模型族
AHE 还把在 GPT-5.4 high 上进化出的 harness,直接迁移到其他 base model:
- GPT-5.4 medium
- GPT-5.4 xhigh
- qwen-3.6-plus
- gemini-3.1-flash-lite-preview
- deepseek-v4-flash
结果全部是正增益,范围从 +2.3 到 +10.1 个百分点。
论文特别提到三个跨模型族结果:
- deepseek-v4-flash:51.7% -> 61.8%,+10.1 pp;
- qwen-3.6-plus:56.2% -> 62.5%,+6.3 pp;
- gemini-3.1-flash-lite-preview:36.5% -> 41.6%,+5.1 pp。
这说明 AHE 学到的不是某个模型专属的 prompt hack,而更像通用 coordination pattern:什么时候检查文件、什么时候验证、如何结束任务、如何处理边界条件、如何减少无效探索。
一个有意思的现象是,弱一些的模型收益更大。直觉上也合理:强模型能从 prompt 里临时推理出很多策略,弱模型更依赖 harness 把正确行为”外置”为工具和中间件。
组件拆解(Ablation):真正有用的不是 System Prompt
论文最精彩的一组实验是组件拆解(ablation study):逐个去掉或单独加入某类组件,看它到底有没有用。
作者把完整 AHE harness 的某一类组件单独拿出来,塞回 seed harness,看单组件贡献:
| Variant | All | Easy | Medium | Hard |
|---|---|---|---|---|
| NexAU0 seed | 69.7% | 87.5% | 78.2% | 51.7% |
| + memory only | 75.3% | 50.0% | 83.6% | 63.3% |
| + tool only | 73.0% | 75.0% | 87.3% | 46.7% |
| + middleware only | 71.9% | 100.0% | 81.8% | 50.0% |
| + system_prompt only | 67.4% | 75.0% | 78.2% | 46.7% |
| AHE full | 77.0% | 100.0% | 88.2% | 53.3% |
结论非常清楚:
- 长期记忆 alone:+5.6 pp,总体强,Hard 最强;
- 工具 alone:+3.3 pp,Medium 很强;
- 中间件 alone:+2.2 pp,Easy 清零;
- system prompt alone:-2.3 pp,反而变差。
这几乎是对”只要把 prompt 写好就行”的反证。
为什么 prompt 单独变差?论文的解释是,system prompt 里的纪律性要求需要工具、middleware、memory 配合才能执行。单独插入一段”要更严谨、要验证、要注意边界”的自然语言,可能只会增加认知负担,并不提供实际能力。
不同组件负责不同失败面:
- memory:记录边界 case,例如性能 margin、队列超限取消、评测器式 closure、源码打包布局等;
- tool:演化出一个 1364 行 shell 工具,会在命令附近自动暴露 contract hints;
- middleware:加入 finish-hook,在结束前强制一次接近 evaluator 的 closure check;
- system prompt:提供通用纪律,但必须依赖其他组件落地。
还有一个重要发现:组件之间不是简单相加。
memory、tool、middleware 单独加起来的收益是 +11.1 pp,但 full AHE 只有 +7.3 pp。原因是多个组件可能同时推动”结束前再验证”,叠加后在 Hard 长程任务上会重复消耗 turn/time budget。
这给未来研究留下一个方向:进化系统不只要知道单个组件有没有用,还要建模组件之间的相互干扰。
自归因分析:会预测修复,但不太会预测回归
AHE 的 decision observability 允许作者评估 Evolve Agent 的自我预测能力。
每轮修改时,Evolve Agent 会预测:
- 这次修改预计修复哪些任务;
- 哪些任务有回归风险。
论文统计 9 个 evaluation round 的 precision / recall:
| 预测类型 | Precision | Recall | 相比随机 |
|---|---|---|---|
| Fix prediction | 33.7% | 51.4% | 约 5 倍随机基线 |
| Regression prediction | 11.8% | 11.1% | 约 2 倍随机基线 |
这说明:
- Evolve Agent 对”我要修什么”有不错的证据驱动能力;
- 但对”我会破坏什么”明显更弱;
- 这解释了进化曲线为什么不是单调上升,中间会有回退和波动。
这点很真实,也很工程。人类工程师也常常比较擅长解释一个 patch 为什么能修 bug,却不一定能预见它会在哪些边缘任务上引入回归。AHE 至少把这件事显式量化了。
方法定位:AHE 和常见 Agent 优化有什么不同?
用一张对比表来理解 AHE 与其他方法的区别:
| 方法 | 优化对象 | 优点 | 问题 |
|---|---|---|---|
| Prompt engineering | system prompt | 简单、低成本 | 容易冗长,执行性弱 |
| Reflexion / self-refine | 反思文本 | 能积累经验 | 容易停留在自然语言建议 |
| ACE | playbook / context | 可复用任务经验 | 每次调用都增加上下文负担 |
| TF-GRPO | 成功轨迹偏好 | 利用 rollout 信号 | 可编辑面较窄 |
| AHE | prompt、tool、middleware、memory 等完整 harness | 可执行、可回滚、可归因 | 工程和计算成本更高,组件交互复杂 |
AHE 的独特性在于:它把 agent 优化从”语言层”推进到”系统层”。这更接近真实工程团队调优 coding agent 的方式:失败了不是只改一句 prompt,而是可能加一个工具、改一个 hook、写一条长期经验、收紧结束条件。
工程落地:如何复现一个简化版 AHE?
即使不完整复现论文,也可以借鉴它的设计思想,按下面这条最小闭环搭一个简化版:

把 harness 文件化
先把 agent 配置拆成明确目录:
harness/
system_prompt.md
tools/
shell.md
shell.py
middleware/
finish_check.py
skills/
debug_test_failure.md
memory/
lessons.md
agents/
code_agent.yaml
要求所有修改都落在这些文件里,不允许改 evaluator、不允许换模型、不允许改 benchmark。
保存每次 rollout 的完整轨迹
每个任务至少保存:
runs/
task_001/
trial_0/
messages.jsonl
tool_calls.jsonl
stdout.log
result.json
轨迹必须能回答三个问题:
- agent 当时看到了什么?
- 它采取了什么动作?
- evaluator 为什么判它失败?
做分层分析
不要直接把所有 log 丢给优化 agent。可以生成:
analysis/
overview.md
tasks/
task_001.md
task_002.md
raw_index.json
每个 task report 建议固定模板:
# Task ID
## Status
pass / fail / partial
## Failure signature
失败表象是什么?
## Root cause
根因更像 prompt、tool、middleware、memory 还是环境问题?
## Evidence
引用关键 tool call / test output / file diff
## Candidate harness fix
建议修改哪个组件,为什么?
每个 patch 都写 manifest
例如:
change_id: iter03_finish_hook
files:
- harness/middleware/finish_check.py
evidence:
- task_014 failed because agent stopped after build success without running evaluator-like test
root_cause: premature_finish
fix: add finish hook that requires evaluator-isomorphic closure check
expected_fixes:
- task_014
- task_027
regression_risks:
- task_061
- task_073
下一轮自动对比 task delta:
- expected_fixes 里真的变好的比例;
- regression_risks 是否命中;
- 未预测回归有哪些;
- 是否需要回滚。
先做小 benchmark
完整 AHE 成本高。工程实践里可以先从 20-50 个内部任务开始:
- 有明确 evaluator;
- 失败原因可追踪;
- 任务类型覆盖真实工作流;
- 每次迭代只允许少量 harness 修改。
这能避免 Evolve Agent 一轮改太多,导致归因混乱。
评价与启发:这篇论文能带走什么?
这篇论文给工程实践的启发
我认为 AHE 最值得带走的不是具体数字,而是四个工程原则。
原则一:别把所有经验都塞进 prompt
如果一条经验可以变成工具默认行为、middleware hook 或长期记忆,就不要每次都靠 prompt 重新提醒模型。
自然语言适合表达目标和原则;工具和中间件适合固化可执行流程。
原则二:agent 轨迹要可观测,而不是只看最终 pass/fail
只有 pass/fail,优化系统只能撞运气。要让 agent 进化,必须保存过程证据:
- 哪一步开始偏了;
- 哪个工具输出被误读;
- 哪个文件没检查;
- 哪个测试信号被忽略;
- 为什么提前结束。
原则三:每次 harness 修改都应该是可验证的假设
”我觉得这样更好”没有工程价值。更好的做法是为每次修改写一份 manifest:
- 根据哪些失败证据,我做了什么改动;
- 我预期会修复 A、B、C,担心 D、E 回归;
- 下一轮跑 benchmark 验证,没有命中的就回滚或降权。
这能把主观判断变成可度量、可证伪的实验。
原则四:评估的不只是 agent,也是 harness
当 base model 固定时,harness 就是主要变量。未来 coding agent 的竞争,可能很大一部分不是”谁的 prompt 更长”,而是:
- 谁的工具抽象更好;
- 谁的中间件更懂验证;
- 谁的记忆更能压缩经验;
- 谁的观测系统更能支持持续改进。
总结
AHE 把 coding agent 的改进范式从 prompt-level self-improvement 推到了 harness-level self-evolution。
它的核心贡献可以浓缩成一句话:
让 agent 改进 agent 的关键,不是给它更多自由,而是给它更好的可观测性、更清晰的可编辑边界,以及每次修改都必须接受验证的机制。
从实验看,AHE 的收益主要来自工具、中间件和长期记忆,而不是 system prompt;从迁移看,这些结构化经验在不同 benchmark 和模型族上仍有价值;从局限看,回归预测和组件交互仍然是下一步难题。
如果说过去两年大家在讨论 context engineering,那么这篇论文更像是在往前推一步:context 不只是放进窗口里的文本,context 也可以是可执行、可审计、可演化的系统结构。
这大概就是 Agentic Harness Engineering 最有价值的地方。